







1.1.3、Statistics Job
从OperatorTree生成Job的过程:
1、对输出表生成MoveTask
2、从OperatorTree中的一个根节点向下深度优先遍历
3、ReduceSinkOperator标识Map/Reduce界限,多个Job间的界限
4、遍历其他根节点,遇到JoinOpeartor合并MapReduceTask
5、生成StatTask更新元数据
6、剪断Map和Reduce之间的Operator关系
代码层面:
Utilities.getMRTasks(plan.getRootTasks()).size()
+ Utilities.getTezTasks(plan.getRootTasks()).size()
+ Utilities.getSparkTasks(plan.getRootTasks()).size();计算生成MR Job的逻辑:
从执行计划根节点任务开始遍历,当该task属于ExecDriver实例,那么Job数+1
计算TezTask生成的Job数逻辑:
也是从执行计划根节点开始遍历,如果该task属于TezTask,那么Job数+1
计算Spark Job数的逻辑:
也是从执行计划根节点开始遍历,如果该task属于SparkTask,那么Job数+1
分析层面:
从explain可以看出一个sql语句会被划分多少个Stage,其实Stage总数就是Job数。但是有些Stage并不是MR或者Spark/Tez任务。所以要根据Operator类型来确定大概有多少个Job.
1.1.4、Only Map?
总结:即只要不发生shuffle,只是做简单的处理,如简单查或者文件移动/删除就会只有map阶段。
1、Creaet table As Select field from table [where condition]
2、select field from table [where condition] --需要设置hive.fetch.task.conversion=none


3、insert into/overwrite target_table select * from table [where condition]

4、select /+MAPJOIN(...)/ ....

5、使用transform,只调用map script;
具体使用可参考:https://github.com/rgordon/hive-transform-example
cat>/tmp/myscript.sh
sed -r -e 's/\{(.*)\}/\1/' -e's/"//g’ -e 's/v(.)/v\100/g'
create table d (item map<string,string>);
create table s (item map<string,string>);
insert into s select map( 'k1', 'v1' ,'k2' ,'v2' , 'k3', 'v3');
add file /tmp/myscript.sh;
select
str_to_map (result)
from
(select
transform (item) using "myscript.sh" as result
from s) t
1.1.5、Only Reduce?
常规上思考MapReduce任务肯定是要有map阶段的,reduce阶段输入数据是通过map端输出数据拿来的。所以MapReduce不可能存在只有reduce的场景。
同样在hive的源码中也可以发现,ExecDriver在配置Job的时候是绑定了ExecMapper和ExecReducer,那么底层引擎是依赖于MapReduce的。
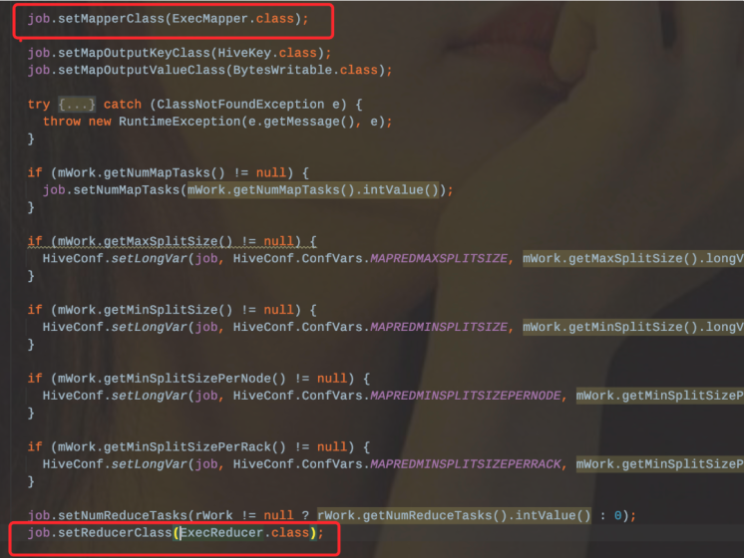
这么看来Hive也是不可能支持的。
但是在Hive的源码中存在另外一个MR框架。是hive自己实现的。
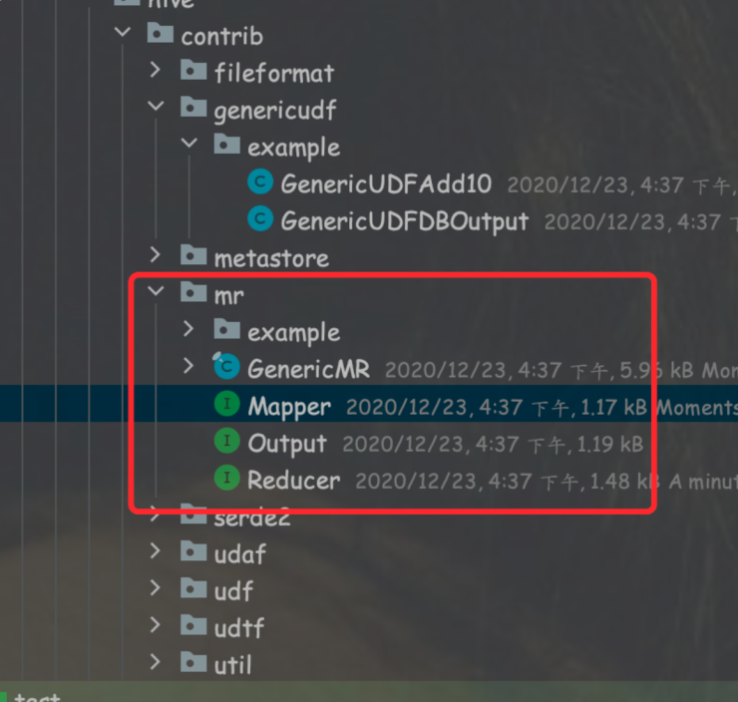
该框架内的MapReduce和hadoop底层的MR组件不一样,hive自身的MR框架,Map和Reduce是独立开的,每个阶段都是直接使用输入输出流,两者之间并没有依赖关系。
所以hive自身框架内的MR是可以支持只有reduce阶段的。可以使用transform函数来实现。
FROM (
FROM src
MAP value, key
USING 'java -cp hive-contrib-${system:hive.version}.jar org.apache,hadoop.hive,ontrib.mr.example.IdentityMapper'
As k, v
CLUSTER BY k) map output
REDUCE k, v
USING 'java -cp hive-contrib-${system:hive.version}.jar org.apache.hadoop.hive.contrib.mr.example.MordCountReduce'
AS k, v;

















 1238
1238











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











