







正则化方法:防止过拟合,提高泛化能力
在训练数据不够多时,或者overtraining时,常常会导致overfitting(过拟合)。其直观的表现如下图所示,随着训练过程,网络在training data上的error渐渐减小,但是在验证集上的error却反而渐渐增大——因为训练出来的网络过拟合了训练集,对训练集外的数据却不work
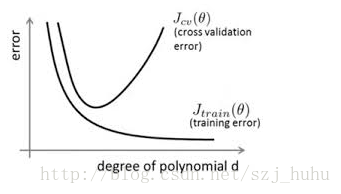
我们常常将原始数据集分为三部分:training data、validation data,testing data。这个validation data是什么?它其实就是用来避免过拟合的,在训练过程中,我们通常用它来确定一些超参数(比如根据validation data上的accuracy来确定early stopping的epoch大小。
避免过拟合的方法有很多:early stopping、数据集扩增(Data augmentation)、正则化(Regularization)包括L1、L2(L2 regularization也叫weight decay),dropout。
L2正则化
L2正则化就是在代价函数后面再加上一个正则化项:
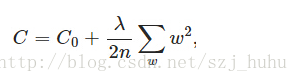
C0代表原始的代价函数,后面那一项就是L2正则化项,样本大小n。λ就是正则项系数。
先求导:
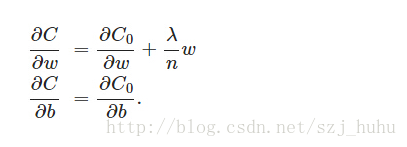
可以发现L2正则化项对b的更新没有影响,但是对于w的更新有影响:
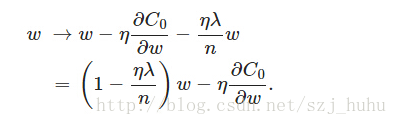
因为η、λ、n都是正的,L2正则化它的效果是减小w,这也就是权重衰减(weight decay)的由来。
对于基于mini-batch的随机梯度下降,w和b更新的公式跟上面给出的有点不同
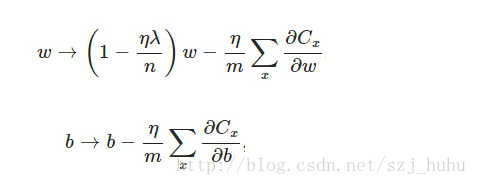
对比上面w的更新公式,可以发现后面那一项变了,变成所有导数加和,乘以η再除以m,m是一个mini-batch中样本的个数。
奥卡姆剃刀法则:更小的权值w,从某种意义上说,表示网络的复杂度更低,对数据的拟合刚刚好。而在实际应用中,也验证了这一点,L2正则化的效果往往好于未经正则化的效果
L1正则化
在原始的代价函数后面加上一个L1正则化项,即所有权重w的绝对值的和,乘以λ/n
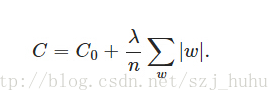
计算导数:
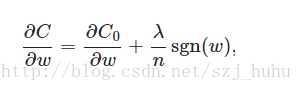
sgn(w)表示w的符号。那么权重w的更新规则为:
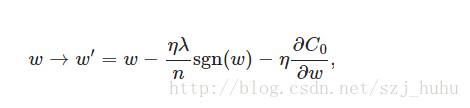
当w为正时,更新后的w变小。当w为负时,更新后的w变大——因此它的效果就是让w往0靠,使网络中的权重尽可能为0,也就相当于减小了网络复杂度,防止过拟合















 277
277

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









