






正则化(regularization):
1. 定义
为了防止过拟合,进而增强泛化能力(泛化误差=测试误差:generalization error=test error)。
是一种为了减小测试误差的行为(有时候会增加训练误差)。我们在构造模型(机器学习模型等)时,最终目的是让模型在面对新数据的时候可以有很好的表现。当你用比较复杂的模型(比如神经网络)去拟合数据是,很容易出现过拟合现象,这会导致模型的泛化能力下降,这时候,就需要使用正则化,降低模型的复杂度。
2. 结构
范数定义:假设x是一个向量,它的L^p范数定义:
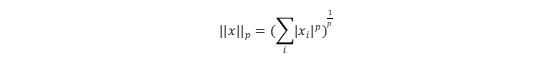
在目标函数后面添加一个系数的“惩罚项”是正则化的常用方式,为了防止系数过大而让模型变得复杂。加入正则化项之后的目标函数为:
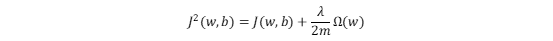
λ/2m是一个常数。
参数的稀疏
可以简化模型,避免过拟合。因为一个模型中真正重要的参数可能并不多,如果考虑所有的参数起作用,那么可以对训练数据可以预测的很好,但是对测试数据表现性能极差。另一个好处是参数变少可以使整个模型有更好的可解释性。
3. 正则化的常用方法
L0正则化
L0正则化的值是模型参数中非零参数的个数。因为稀疏的参数可以防止过拟合,所以用L0范数(非零参数的个数)来做正则化是可以防止过拟合的。利用非零参数的个数,可以很好的来选择特征,实现特征稀疏的效果,具体操作时选择参数非零的特征即可。但是L0正则化很难求解,所以一般采用L1正则化。
L1正则化(Lasso regression)
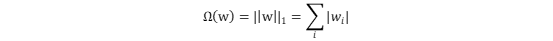 理解:L1正则化是L0正则化的最优凸近似,表示各个参数绝对值之和。L1正则化通过让原目标函数加上了所有特征系数绝对值的和来实现正则化。L1正则化更适用于特征选择。
理解:L1正则化是L0正则化的最优凸近似,表示各个参数绝对值之和。L1正则化通过让原目标函数加上了所有特征系数绝对值的和来实现正则化。L1正则化更适用于特征选择。
L2正则化(Ridge regression)
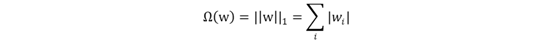
理解:标识各个参数的平方的和的开方值。L2正则化通过让原目标函数加上了所有特征系数的平方和来实现正则化。L2正则化更适用于防止模型过拟合。
训练集增强
更大数量的训练集是提升学习模型泛化能力最好的方法。如果不能够获取训练数据,可以自己“创造”数据,通过对原数据的调整(旋转、平移、放大、缩小等)。
Dropout
是一种计算方便但是功能很强大的正则化方法,适用于神经网络。基本步骤是在每一次迭代中,随机删除一部分节点,只训练剩下的节点。每次迭代都会随机删除,每次迭代删除的节点都不一样,相当于每次迭代训练的都是不一样的网络,通过这样的方式降低节点之间的关联性以及模型的复杂性,从而达到正则化的效果。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









