







http://blog.csdn.net/carson2005/article/details/7235196
在贝叶斯分类(这里有个简介:http://blog.csdn.net/carson2005/article/details/6854005 )器设计之中,需要在类的先验概率和类条件概率密度均已知的情况下,按照一定的决策规则确定判别函数和决策面。但是,在实际应用中,类条件概率密度通常是未知的。那么,当先验概率和类条件概率密度都未知或者其中之一未知的情况下,该如何来进行类别判断呢?其实,只要我们能收集到一定数量的样本,根据统计学的知识,我们是可以从样本集来推断总体概率分布的。一般来说,有以下几种方法可以解决这个问题:
一、监督参数估计:样本所属的类别及类条件总体概率密度函数的形式为已知,而表征概率密度函数的某些参数是未知的。例如,只知道样本所属总体分布形式为正态分布,而正态分布的参数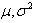 是未知的。监督参数估计的目的就是由已知类别的样本集对总体分布的某些参数进行统计推断。
是未知的。监督参数估计的目的就是由已知类别的样本集对总体分布的某些参数进行统计推断。
二、非监督参数估计:已知总体概率密度函数形式但未知样本所属的类别,要求推断出概率密度函数的某些参数,这种推断方法称之为非监督情况下的参数估计。 这里提到的监督参数估计和非监督参数估计中的监督和非监督是指样本所属类别是已知还是未知。但无论哪种情况下的参数估计都是统计学中的经典问题,解决的方法很多。但最常用的有两种:一种是最大似然估计方法;另一种是贝叶斯估计方法。虽然两者在结果上通常是近似的,但从概念上来说它们的处理方法是完全不同的。最大似然估计把参数看做是确定(非随机)而未知的,最好的估计值是在获得实际观察样本的概率为最大的条件下得到的。而贝叶斯估计则是把参数当做具有某种分布的随机变量,样本的观察结果使先验分布转换为后验分布,再根据后验分布修正原先对参数的估计。
三、非参数估计:已知样本所属的类别,但未知总体概率密度函数的形式,要求我们直接推断概率密度函数本身。统计学中常见的一些典型分布形式不总是能够拟合实际中的分布。此外,在许多实际问题中经常遇到多峰分布的情况,这就迫使我们必须用样本来推断总体分布,常见的总体类条件概率密度估计方法有Parzen窗法和Kn近邻法两种。















 9389
9389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









