






最近在利用python对机器学习进行实践,因为之前我是先完整的刷了一遍周志华老师的《西瓜书》才开始的实践活动,因此,时间跨度很久,以至于对于SVM的相关理论有些生疏了,甚至关于SVM的一些之前没注意到的问题,现在暴露了出来,所以这篇文章主要是想跟大家分享一下个人关于SVM的一些令人纠结的问题的思考,同时记录一下,如果有误请见谅,欢迎一起探讨。当然,如果这篇文章还能入得了各位“看官”的法眼,麻烦点赞、关注、收藏,支持一下!
对于本文中有些问题的答案,因为本人比较懒,所以我会直接将互联网上一些写的很好的大佬的回答截图附上,同时为了保护各位大佬的知识劳动成果,我也会在文章最后附上本文所涉及的所有大佬的文章的相关网址链接,需要查看大佬们原文的可以自取
讲之前,先附上一张《西瓜书》中的图片(如下),感觉这张图在SVM中可以算是经典中的经典
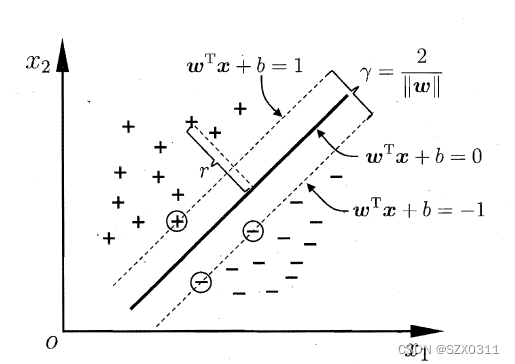
一、超平面方程![]() 是怎么来的?
是怎么来的?

二、支持向量所在平面方程![]() 中的±1是哪里来的?
中的±1是哪里来的?
相信如果将支持向量所在的平面方程写成如下形式,可能更加让人容易接受
![]()
很多人疑惑的是±t是如何变成±1的,其实这个说白了很简单,就是一个缩放过程,下面给出:
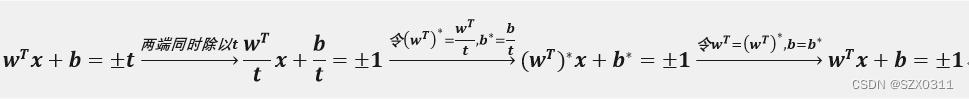
在这里我们需要明白w和b本质上只是一个表示符号,如果今天心情不好,甚至可以把它改成m和a
±1的来源是解释明白了,但是可能有人还存在疑惑,缩放之后的曲线,还是原来的曲线吗?我的答案是:是的!!!为了让大家直观感受一下,举个简单的例子:

观察上面的直线方程1和直线方程2,我们不难发现,两者是等价的,即通过描点法将直线方程1和直线方程2分别在同一直角坐标系中画出,两条直线完全重合
三、在SVM求解的推导过程中怎么从求最小化变成了求最大化?
在SVM的求解过程中是为了求取一个间隔最大的超平面,即支持向量所在的两个平面方程之间的距离最大,而这等价于求解![]() 最小化,如下图所示:
最小化,如下图所示:
![]()
![]()
但是在引入拉格朗日乘子法对上述方程进行求解时为啥变成了求最大化,如下图所示:
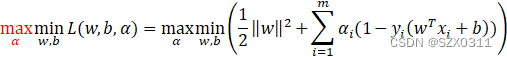
![]()
根据KKT条件可以知道拉格朗日乘子大于等于0,即![]() ,再结合给定的限定条件可以知道:
,再结合给定的限定条件可以知道:
![]()
所以:
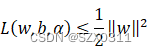
由此可知:
结论①:![]() 的最大值必然小于等于
的最大值必然小于等于![]() 的最小值
的最小值
结论②:![]()
当w和b已知后超平面函数L仍然不确定,因为函数L还受参数α的影响,同时结合上面得到的结论①和结论②,即可将上面的不等式转换成如下形式:
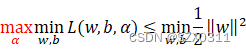
所以我们就可以通过求解![]() 来近似逼近
来近似逼近![]()
本文参考借鉴的相关文章有:

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









