






文章目录
一、概要
1. 传统的入侵检测数据集(如KDD)很难在现实网络环境提取出相同的特征数据,采用CIC-IDS2017数据集配套的CICFlowMeter流量特征提取工具,可以将训练好的模型运用到现实世界。
数据集官网: CIC-IDS-2017 。下载也可以去网上找一些资源
2. ICNN模型是自己搭的,可以用效果更好的模型
1.1 整体架构流程
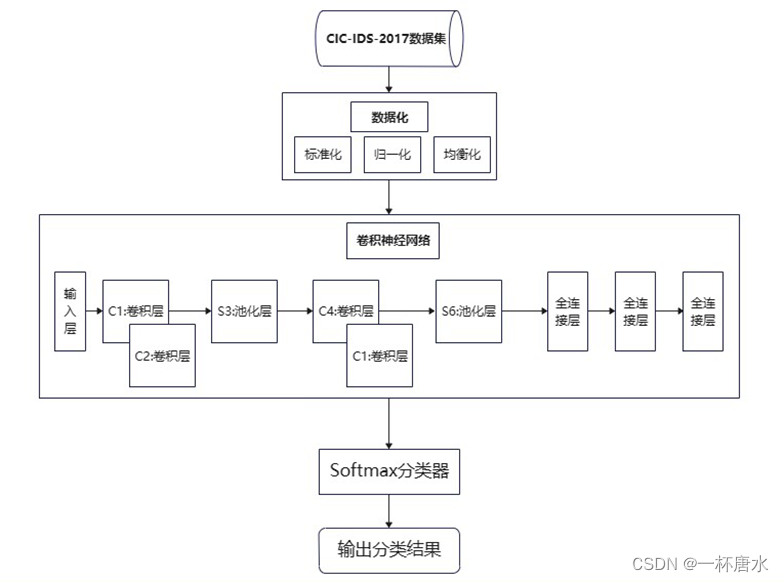
二、 模型构建过程
2.1 数据处理
2.1.1 合并数据集
CIC-IDS-2017数据集文件如下,需要读取数据进行合并,并去除脏数据
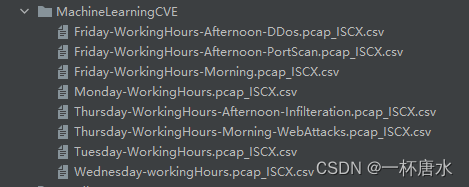
raw_data = mergeData()
# 根据file读取数据
def writeData(file):
print("Loading raw data...")
raw_data = pd.read_csv(file, header=None, low_memory=False)
# 剔除第一行属性特征名称
return raw_data.drop([0])
# 按行合并多个Dataframe数据
def mergeData():
monday = writeData("../data/MachineLearningCVE/Monday-WorkingHours.pcap_ISCX.csv")
friday1 = writeData("../data/MachineLearningCVE/Friday-WorkingHours-Afternoon-DDos.pcap_ISCX.csv")
friday2 = writeData("../data/MachineLearningCVE/Friday-WorkingHours-Afternoon-PortScan.pcap_ISCX.csv")
friday3 = writeData("../data/MachineLearningCVE/Friday-WorkingHours-Morning.pcap_ISCX.csv")
thursday1 = writeData("../data/MachineLearningCVE/Thursday-WorkingHours-Afternoon-Infilteration.pcap_ISCX.csv")
thursday2 = writeData("../data/MachineLearningCVE/Thursday-WorkingHours-Morning-WebAttacks.pcap_ISCX.csv")
tuesday = writeData("../data/MachineLearningCVE/Tuesday-WorkingHours.pcap_ISCX.csv")
wednesday = writeData("../data/MachineLearningCVE/Wednesday-workingHours.pcap_ISCX.csv")
frame = [monday, friday1, friday2, friday3, thursday1, thursday2, tuesday, wednesday]
# 合并数据
result = pd.concat(frame)
list = clearDirtyData(result)
result = result.drop(list)
return result
# 清除CIC-IDS数据集中的脏数据,第一行特征名称和含有Nan、Infiniti等数据的行数
def clearDirtyData(df):
dropList = df[(df[14] == "Nan") | (df[15] == "Infinity")].index.tolist()
return dropList
2.1.2 数据拓展
原始数据分布非常不平衡,对数据进行类似重采样的拓展,每条数据达到5000条以上
查看原始数据分布:
# 得到标签列索引
last_column_index = raw_data.shape[1] - 1
# 统计标签数量
print(raw_data[last_column_index].value_counts())
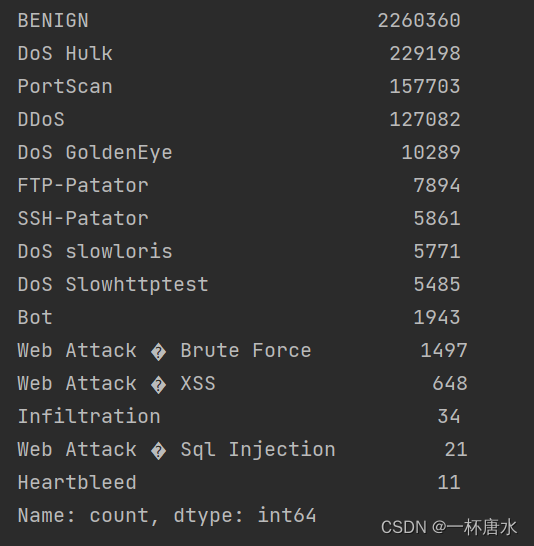
可以发现数据分布非常不均匀,对数据进行拓展,代码如下:
lists = separateData(raw_data)
expendData(lists)
# 将大的数据集根据标签特征分为15类,存储到lists集合中
def separateData(raw_data):
# dataframe数据转换为多维数组
lists = raw_data.values.tolist()
temp_lists = []
# 生成15个空的list集合,用来暂存生成的15种特征集
for i in range(0, 15):
temp_lists.append([])
# 得到raw_data的数据标签集合
label_set = lookData(raw_data)
# 将无序的数据标签集合转换为有序的list
label_list = list(label_set)
for i in range(0, len(lists)):
# 得到所属标签的索引号
data_index = label_list.index(lists[i][len(lists[0]) - 1])
temp_lists[data_index].append(lists[i])
if i % 5000 == 0:
print(i)
saveData(temp_lists, '../data/expendData/')
return temp_lists
def lookData(raw_data):
# 打印数据集的标签数据数量
last_column_index = raw_data.shape[1] - 1
print(raw_data[last_column_index].value_counts())
# 取出数据集标签部分
labels = raw_data.iloc[:, raw_data.shape[1] - 1:]
# 多维数组转为以为数组
labels = labels.values.ravel()
label_set = set(labels)
return label_set
# 将lists分批保存到file文件路径下
def saveData(lists, file):
label_set = lookData(raw_data)
label_list = list(label_set)
for i in range(0, len(lists)):
save = pd.DataFrame(lists[i])
file1 = file + label_list[i] + '.csv'
save.to_csv(file1, index=False, header=False)
# lists存储着15类数据集,将数据集数量少的扩充到至少不少于5000条,然后存储起来。
def expendData(lists):
totall_list = []
for i in range(0, len(lists)):
while len(lists[i]) < 5000:
lists[i].extend(lists[i])
totall_list.extend(lists[i])
saveData(lists, '../data/expendData/')
save = pd.DataFrame(totall_list)
file = '../data/clearData/totall_extend.csv'
print("正在保存")
save.to_csv(file, index=False, header=False)
2.1.3 数据预处理
读取汇总的文件,对数据进行数值化、标准化、归一化、过滤异常值。
代码如下:
df = pd.read_csv('..\data\clearData\\totall_extend.csv',header=None, low_memory=False)
last_column_index = df.shape[1] - 1
print(df[last_column_index].value_counts())
df.columns = [
'Destination Port', 'Flow Duration', 'Total Fwd Packets', 'Total Backward Packets',
'Total Length of Fwd Packets', 'Total Length of Bwd Packets', 'Fwd Packet Length Max',
'Fwd Packet Length Min', 'Fwd Packet Length Mean', 'Fwd Packet Length Std',
'Bwd Packet Length Max', 'Bwd Packet Length Min', 'Bwd Packet Length Mean',
'Bwd Packet Length Std', 'Flow Bytes/s', 'Flow Packets/s', 'Flow IAT Mean',
'Flow IAT Std', 'Flow IAT Max', 'Flow IAT Min', 'Fwd IAT Total', 'Fwd IAT Mean',
'Fwd IAT Std', 'Fwd IAT Max', 'Fwd IAT Min', 'Bwd IAT Total', 'Bwd IAT Mean',
'Bwd IAT Std', 'Bwd IAT Max', 'Bwd IAT Min', 'Fwd PSH Flags', 'Bwd PSH Flags',
'Fwd URG Flags', 'Bwd URG Flags', 'Fwd Header Length', 'Bwd Header Length',
'Fwd Packets/s', 'Bwd Packets/s', 'Min Packet Length', 'Max Packet Length',
'Packet Length Mean', 'Packet Length Std', 'Packet Length Variance',
'FIN Flag Count', 'SYN Flag Count', 'RST Flag Count', 'PSH Flag Count',
'ACK Flag Count', 'URG Flag Count', 'CWE Flag Count', 'ECE Flag Count',
'Down/Up Ratio', 'Average Packet Size', 'Avg Fwd Segment Size',
'Avg Bwd Segment Size', 'Fwd Header Length', 'Fwd Avg Bytes/Bulk',
'Fwd Avg Packets/Bulk', 'Fwd Avg Bulk Rate', 'Bwd Avg Bytes/Bulk',
'Bwd Avg Packets/Bulk', 'Bwd Avg Bulk Rate', 'Subflow Fwd Packets',
'Subflow Fwd Bytes', 'Subflow Bwd Packets', 'Subflow Bwd Bytes',
'Init_Win_bytes_forward', 'Init_Win_bytes_backward', 'act_data_pkt_fwd',
'min_seg_size_forward', 'Active Mean', 'Active Std', 'Active Max',
'Active Min', 'Idle Mean', 'Idle Std', 'Idle Max', 'Idle Min', 'Label'
]
df.dropna(inplace=True, axis=0)
# 得到标签列索引
all_col = df.columns
cat_col = df.columns.drop('Label')
# 数据标准化
df=encode_numeric_zscore(df,cat_col)
# 数据归一化
df=encode_numeric_range(df,cat_col)
# 数据数值化
df=Numerical_Encoding(df,df.Label)
# 异常清除
invalid_mask = np.isnan(df) | np.isinf(df)
valid_rows = ~np.any(invalid_mask, axis=1)
# 仅保留有效行
df = df[valid_rows]
# 数据归一化
def encode_numeric_range(df, names, normalized_low=0, normalized_high=1,
data_low=None, data_high=None):
for name in names:
if data_low is None:
data_low = min(df[name])
data_high = max(df[name])
df[name] = ((df[name] - data_low) / (data_high - data_low)) \
* (normalized_high - normalized_low) + normalized_low
return df
# 数据标准化
def encode_numeric_zscore(df, names, mean=None, sd=None):
for name in names:
if mean is None:
mean = df[name].mean()
if sd is None:
sd = df[name].std()
df[name] = (df[name] - mean) / sd
return df
# 数据数值化
def Numerical_Encoding(df,label):
labels = pd.DataFrame(label)
label_encoder = LabelEncoder()
enc_label = labels.apply(label_encoder.fit_transform)
df.Label = enc_label
return df
2.2 模型构建
2.2.1 数据加载
测试集与训练集按照8:2的比例进行划分:
X = df.drop(columns=['Label'])
y = df['Label']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=50)
定义一个pytorch的继承Dataset的LoadData类,用来加载数据,返回样本值X与标签y
class LoadData(Dataset):
def __init__(self, X, y):
self.X = X
self.y = y
def __len__(self):
return len(self.X)
def __getitem__(self, index):
X = torch.tensor(self.X.iloc[index])
y = torch.tensor(self.y.iloc[index])
return X, y
train_data = LoadData(X_train, y_train)
test_data = LoadData(X_test, y_test)
X_dimension = len(X_train.columns)
y_dimension = len(y_train.value_counts())
print(f"X的维度:{X_dimension}")
print(f"y的维度:{y_dimension}")
batch_size = 128
train_dataloader = DataLoader(train_data, batch_size=batch_size)
test_dataloader = DataLoader(test_data, batch_size=batch_size)
2.2.2 搭建ICNN模型
# 使用cuda进行GPU加速,如果无可加速显卡,则使用cpu
device = 'cuda:0' if torch.cuda.is_available() else 'cpu'
ICNN模型搭建
(可以使用其他更好的网络模型):
结构图示:基于 LeNet-5 的入侵检测模型的改进方案
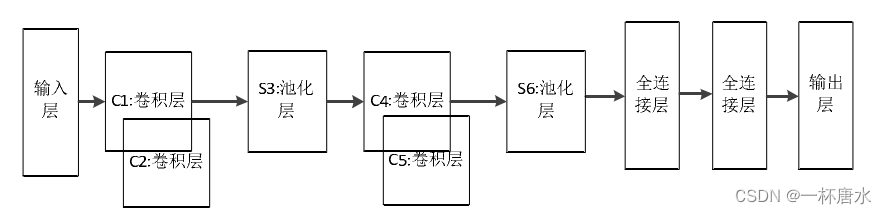
ICNN:改进卷积神经网络模型:
优点:基于 LeNet-5 的入侵检测模型的改进方案,提高模型对入侵检
测数据特征的学习能力。改进后的卷积神经网络 ICNN 将 LeNet-5 中单个卷积层接一个池化
操作改为两个卷积层后接一个池化操作,避免池化操作过于密集,导致网络模型学习不到
各种网络连接属性之间的联系。两个卷积层的直接堆叠可以使模型对入侵数据的特征提取
更加准确和深刻。在最后使用了两个全连接层和 Softmax 函数,第一个全连接层将前面的
卷积层学到的抽象信息映射到更大的空间中,增加了模型的表征能力。第二个全连接层也
有第一个的作用,但更多是为了输出的维度转换做准备,匹配入侵检测的分类。
class CNN(nn.Module):
def __init__(self):
super().__init__()
self.backbone = nn.Sequential(
nn.Conv1d(1, 32, kernel_size=2),
nn.Conv1d(32, 64, kernel_size=2),
nn.MaxPool1d(2, 2),
nn.Conv1d(64, 64, kernel_size=2),
nn.Conv1d(64, 128, kernel_size=2),
nn.MaxPool1d(2, 2),
)
self.flatten = nn.Flatten()
self.fc = nn.Sequential(
nn.Linear(2304, 64),
nn.ReLU(),
nn.Linear(64, 64),
nn.ReLU(),
nn.Linear(64, y_dimension)
)
def forward(self, X):
X = self.backbone(X)
X = self.flatten(X)
logits = self.fc(X)
return logits
def loss_value_plot(losses, iter):
plt.figure()
plt.plot([i for i in range(1, iter+1)], losses)
plt.xlabel('Iterations (×100)')
plt.ylabel('Loss Value')
#加载模型
CNN_model = CNN()
CNN_model.to(device=device)
def train(model, optimizer, loss_fn, epochs):
losses = []
iter = 0
for epoch in range(epochs):
print(f"epoch {epoch+1}\n-----------------")
for i, (X, y) in enumerate(train_dataloader):
X, y = X.to(device).to(torch.float32), y.to(device).to(torch.float32)
X = X.reshape(X.shape[0], 1, X_dimension)
y_pred = model(X)
loss = loss_fn(y_pred, y.long())
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i % 100 == 0:
print(f"loss: {loss.item()}\t[{(i+1)*len(X)}/{len(train_data)}]")
iter += 1
losses.append(loss.item())
return losses, iter
def test(model):
positive = 0
negative = 0
with torch.no_grad():
iter = 0
loss_sum = 0
for X, y in test_dataloader:
X, y = X.to(device).to(torch.float32), y.to(device).to(torch.float32)
X = X.reshape(X.shape[0], 1, X_dimension)
y_pred = model(X)
loss = loss_fn(y_pred, y.long())
loss_sum += loss.item()
iter += 1
for item in zip(y_pred, y):
if torch.argmax(item[0]) == item[1]:
positive += 1
else:
negative += 1
acc = positive / (positive + negative)
avg_loss = loss_sum / iter
print("Accuracy:", acc)
print("Average Loss:", avg_loss)
def loss_value_plot(losses, iter):
plt.figure()
plt.plot([i for i in range(1, iter+1)], losses)
plt.xlabel('Iterations (×100)')
plt.ylabel('Loss Value')
if os.path.exists('../Model/CNN_model.pth'):
CNN_model.load_state_dict(torch.load('../Model/CNN_model.pth'))
else:
losses, iter = train(CNN_model, optimizer, loss_fn, epochs)
torch.save(CNN_model.state_dict(), '../Model/CNN_model.pth')
loss_value_plot(losses, iter)
plt.savefig('../Model/CNN_loss.png')
test(CNN_model)
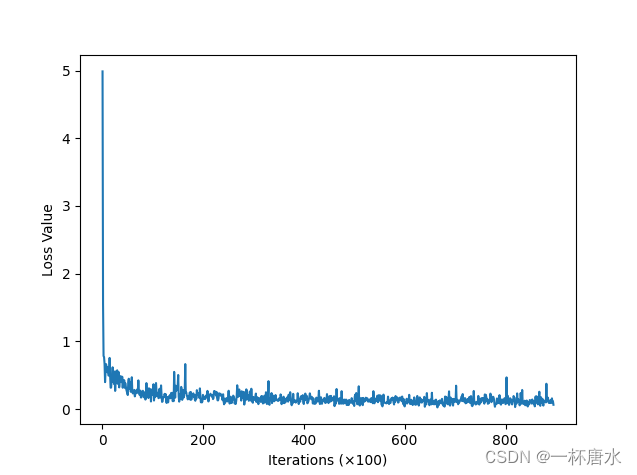
2.2.3 结果测试
执行 test 函数
test(CNN_model)

2.4 模型应用
2.4.1 加载模型
#加载模型
CNN_model.load_state_dict(torch.load('../data/CNN_model.pth'))
classes_map = ['BENIGN', 'Bot', 'DDoS', 'DoS GoldenEye', 'DoS Hulk', 'DoS Slowhttptest',
'DoS slowloris', 'FTP-Patator', 'Heartbleed', 'Infiltration', 'PortScan',
'SSH-Patator', 'Web Attack � Brute Force', 'Web Attack � Sql Injection',
'Web Attack � XSS']
2.4.2 数据分类
使用流量特征提取工具 CICFlowMeter 对现实流量数据进行抓取,并将流量数据
转换为与 CIC-IDS-2017 相同的特征数据,对特征数据进行数据预处理操作,将处理完的数
据输入上述训练完成的模型进行处理,再将处理结果输入 Softmax 分类器,进行网络流量
的分类,得出分类结果。
#进行数据分类
def pre(values, db, docs):
y_pred_list = []
df = pd.DataFrame(values)
df = encode_numeric_zscore(df)
df = encode_numeric_range(df)
test_data = LoadData(df.iloc[:, :])
test_dataloader = DataLoader(test_data, batch_size=1)
X_dimension = len(df.iloc[:, :].columns)
for X in test_dataloader:
X = X.to(device).to(torch.float32)
X = X.reshape(X.shape[0], 1, X_dimension)
y_pred = CNN_model(X)
y_pred_softmax = F.softmax(y_pred, dim=1)
predicted_labels = torch.argmax(y_pred_softmax, dim=1)
predicted_labels = [classes_map[idx.item()] for idx in predicted_labels]
y_pred_list.append(predicted_labels[0])
y_pred_array = np.array(y_pred_list)
for i in range(len(values)):
docs[i]["Label"] = y_pred_array[i]
print("插入了" + str(len(docs)))
#存入数据库
db.insert_many(docs)
三、完整代码
后续整理到github

















 1130
1130

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









