






文章目录
前言
使用BiLSTM(双向长短时记忆网络)进行股票预测
一、什么是BiLSTM
BiLSTM(Bidirectional Long Short-Term Memory)是一种基于循环神经网络(RNN)的模型架构,它在每个时间步上使用两个LSTM层,一个按照时间顺序处理输入序列,另一个按照时间的逆序处理输入序列。
二、数据集介绍
Tushare是一个免费、开源的python财经数据接口包。主要实现对股票等金融数据从数据采集、清洗加工到数据存储的过程,能够为金融分析人员提供快速、整洁、和多样的便于分析的数据,为他们在数据获取方面极大地减轻工作量,使他们更加专注于策略和模型的研究与实现上。考虑到Python pandas包在金融量化分析中体现出的优势,Tushare返回的绝大部分的数据格式都是pandas DataFrame类型,非常便于用pandas、NumPy、Matplotlib进行数据分析和可视化。
三、代码实现
1.matplotlib异常处理
- 取消警告提示
- 解决 libiomp5.dylib 库被重复加载导致的error
- 切换为图形界面显示的终端TkAgg
from matplotlib import MatplotlibDeprecationWarning
import warnings
import os.path
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
warnings.filterwarnings("ignore", category=MatplotlibDeprecationWarning)
matplotlib.use('TkAgg')
2.导入相关资源包
import matplotlib.pyplot as plt
import numpy as np
import tushare as ts
import torch
from torch import nn
import datetime
import time
3.定义模型结构
- inupt_size:输入向量维度
- hidden_size :隐藏层单元
- num_layers:lstm层数
- bidirectional : 开启双向lstm
- BiLSTM每个时间步是由2个相反方向的LSTM在计算结果,它们2个的结果会拼接起来,所以,BiLSTM的输出维度是2 x hidden_size
class LSTM_Regression(nn.Module):
def __init__(self, input_size, hidden_size, output_size=1, num_layers=2):
super(LSTM_Regression, self).__init__()
self.lstm = nn.LSTM(input_size, hidden_size, num_layers,bidirectional=True,batch_first=True)
self.fc = nn.Linear(hidden_size * 2, output_size)
def forward(self, _x):
x, _ = self.lstm(_x) # _x is input, size (seq_len, batch, input_size)
# s, b, h = x.shape # x is output, size (seq_len, batch, hidden_size)
# x = x.view(s * b, h)
x = self.fc(x)
# x = x.view(s, b, -1) # 把形状改回来
return x
4.制作数据集
def create_dataset(data, days_for_train=5) -> (np.array, np.array):
"""
根据给定的序列data,生成数据集
以i~i+days_for_train的数据作为x
以i + das_for_train + 1的数据为y
"""
dataset_x, dataset_y = [], []
for i in range(len(data) - days_for_train):
_x = data[i:(i + days_for_train)]
dataset_x.append(_x)
dataset_y.append(data[i + days_for_train])
return (np.array(dataset_x), np.array(dataset_y))
5.获取/展示数据集
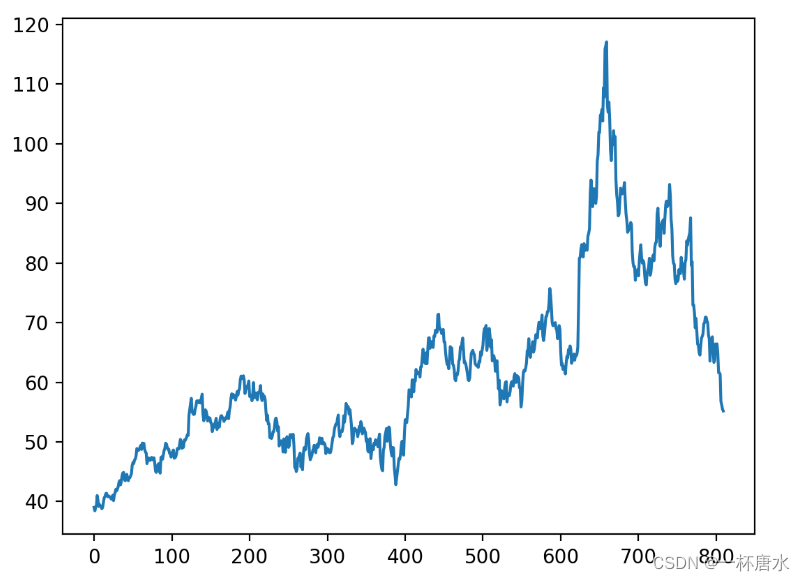
可以根据自己的兴趣选择想要下载的时间范围,比如代码中选择了起始日期为2010年7月1日。另外训练集与测试集的长度也可以自由调节。
def getdata_and_show():
pro = ts.pro_api('ebe58bda43ffb0999bd5be35a40edbefd594afc7d41b0710ef40d76b')
df = pro.daily(ts_code='002352.SZ', start_date='20200701')["close"].values
data_close = df.astype('float32')
plt.plot(data_close)
plt.savefig('./img/data.png', format='png', dpi=200)
plt.close()
# plt.show()
return data_close
6.预处理 / 分割 / 加载数据集
max_value = np.max(data_close_1)
min_value = np.min(data_close_1)
data_close = (data_close_1 - min_value) / (max_value - min_value)
dataset_x, dataset_y = create_dataset(data_close, DAYS_FOR_TRAIN)
# 先转为tensor
dataset_x = torch.from_numpy(dataset_x).reshape(-1, 1, DAYS_FOR_TRAIN)
dataset_y = torch.from_numpy(dataset_y).reshape(-1, 1, 1)
dataset = Data.TensorDataset(dataset_x, dataset_y)
# 划分训练集和测试集,80%作为训练集
train_size = int(len(dataset) * 0.8)
test_size = len(dataset) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(dataset, [train_size, test_size])
train_loader = Data.DataLoader(
dataset=train_dataset,
batch_size=64,
shuffle=True
)
test_loader = Data.DataLoader(
dataset=test_dataset,
batch_size=64,
shuffle=True
)
7.训练模型
train_loss = []
test_loss = []
#加载模型并设置模型参数
model = LSTM_Regression(DAYS_FOR_TRAIN, 8, output_size=1, num_layers=2)
loss_fn = nn.MSELoss()#二元交叉熵
#初始化优化器
optimizer = torch.optim.Adam(model.parameters(), lr=1e-2, betas=(0.9, 0.999), eps=1e-08, weight_decay=0)
def train():
for i in range(1000):
epoch_train_loss=[]
epoch_test_loss=[]
for _, (batch_x, batch_y) in enumerate(train_loader):
out = model(batch_x)
loss = loss_fn(out, batch_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch_train_loss.append(loss.item())
# 将训练过程的损失值写入文档保存,并在终端打印出来
with open('./log/log.txt', 'a+') as f:
f.write('{} - {}\n'.format(i + 1, loss.item()))
if (i + 1) % 1 == 0:
print('Epoch: {}, Loss:{:.5f}'.format(i + 1, loss.item()))
with torch.no_grad():
train_loss.append(sum(epoch_train_loss)/len(epoch_train_loss))
for _,(batch_x, batch_y) in enumerate(test_loader):
out=model(batch_x)
testloss=loss_fn(out,batch_y)
epoch_test_loss.append(testloss.item())
with torch.no_grad():
test_loss.append(sum(epoch_test_loss)/len(epoch_test_loss))
torch.save(model.state_dict(), './model/model_lstm_stock.pkl') # 可以保存模型的参数供未来使用
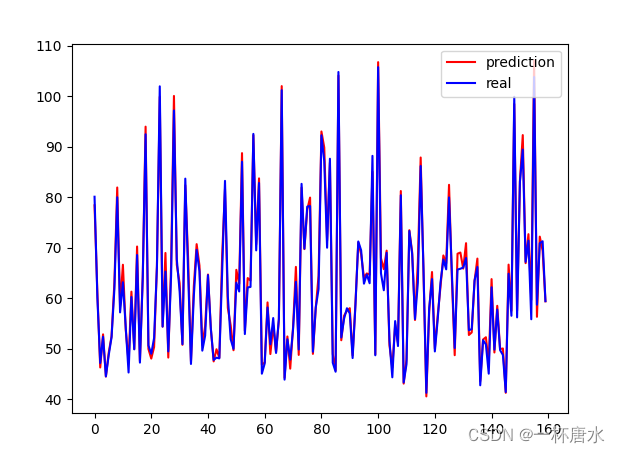
8.模型测试 / 评估
计算rmse与mae评估模型性能,并展示预测准确度
def test_model():
total_rmse = 0
total_mae = 0
num=len(test_loader)
pre_list=[]
real_list=[]
with torch.no_grad():
for _,(batch_x,batch_y) in enumerate(test_loader):
# 预测值
pre=model(batch_x)
#rmse计算
rmse = torch.sqrt(loss_fn(pre, batch_y))
total_rmse += rmse.item() * batch_y.size(0)
#mae计算
mae = torch.abs(pre - batch_y).sum()
total_mae += mae.item()
#还原维度
pre = pre * (max_value - min_value) + min_value
pre = pre.view(-1).data.numpy()
batch_y= batch_y * (max_value - min_value) + min_value
batch_y = batch_y.view(-1).data.numpy()
pre_list.extend(pre)
real_list.extend(batch_y)
plt.plot(pre_list, 'r', label='prediction')
plt.plot(real_list, 'b', label='real')
plt.legend(loc='best')
plt.show()
print(rmse.item()/num)
print(mae.item()/num)
plt.figure()
plt.plot(train_loss, 'b', label='train_loss')
plt.plot(test_loss,"r",label="test_loss")
plt.title("Train_Loss_Curve")
plt.ylabel('train_loss')
plt.xlabel('epoch_num')
plt.legend(loc='best')
plt.savefig('./img/loss.png', format='png', dpi=200)
plt.close()
# for test
model = model.eval() # 转换成测试模式
test_model()

四、完整代码
import torch.utils.data as Data
import os.path
import matplotlib.pyplot as plt
import numpy as np
import tushare as ts
import pandas as pd
import torch
from torch import nn
import datetime
import time
from matplotlib import MatplotlibDeprecationWarning
import warnings
import os.path
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
warnings.filterwarnings("ignore", category=MatplotlibDeprecationWarning)
DAYS_FOR_TRAIN = 10
class LSTM_Regression(nn.Module):
def __init__(self, input_size, hidden_size, output_size=1, num_layers=2):
super(LSTM_Regression, self).__init__()
self.lstm = nn.LSTM(input_size, hidden_size, num_layers,bidirectional=True,batch_first=True)
self.fc = nn.Linear(hidden_size * 2, output_size)
def forward(self, _x):
x, _ = self.lstm(_x)
x = self.fc(x)
return x
def create_dataset(data, days_for_train=5) -> (np.array, np.array):
dataset_x, dataset_y = [], []
for i in range(len(data) - days_for_train):
_x = data[i:(i + days_for_train)]
dataset_x.append(_x)
dataset_y.append(data[i + days_for_train])
return (np.array(dataset_x), np.array(dataset_y))
def getdata_and_show():
pro = ts.pro_api('ebe58bda43ffb0999bd5be35a40edbefd594afc7d41b0710ef40d76b')
df = pro.daily(ts_code='002352.SZ', start_date='20200701')["close"].values
data_close = df.astype('float32')
plt.plot(data_close)
plt.savefig('./img/data.png', format='png', dpi=200)
plt.close()
# plt.show()
return data_close
def train():
for i in range(1000):
epoch_train_loss=[]
epoch_test_loss=[]
for _, (batch_x, batch_y) in enumerate(train_loader):
out = model(batch_x)
loss = loss_fn(out, batch_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch_train_loss.append(loss.item())
# 将训练过程的损失值写入文档保存,并在终端打印出来
with open('./log/log.txt', 'a+') as f:
f.write('{} - {}\n'.format(i + 1, loss.item()))
if (i + 1) % 1 == 0:
print('Epoch: {}, Loss:{:.5f}'.format(i + 1, loss.item()))
with torch.no_grad():
train_loss.append(sum(epoch_train_loss)/len(epoch_train_loss))
for _,(batch_x, batch_y) in enumerate(test_loader):
out=model(batch_x)
testloss=loss_fn(out,batch_y)
epoch_test_loss.append(testloss.item())
with torch.no_grad():
test_loss.append(sum(epoch_test_loss)/len(epoch_test_loss))
torch.save(model.state_dict(), './model/model_lstm_stock.pkl') # 可以保存模型的参数供未来使用
def test_model():
total_rmse = 0
total_mae = 0
num=len(test_loader)
pre_list=[]
real_list=[]
with torch.no_grad():
for _,(batch_x,batch_y) in enumerate(test_loader):
# 预测值
pre=model(batch_x)
#rmse计算
rmse = torch.sqrt(loss_fn(pre, batch_y))
total_rmse += rmse.item() * batch_y.size(0)
#mae计算
mae = torch.abs(pre - batch_y).sum()
total_mae += mae.item()
#还原维度
pre = pre * (max_value - min_value) + min_value
pre = pre.view(-1).data.numpy()
batch_y= batch_y * (max_value - min_value) + min_value
batch_y = batch_y.view(-1).data.numpy()
pre_list.extend(pre)
real_list.extend(batch_y)
plt.plot(pre_list, 'r', label='prediction')
plt.plot(real_list, 'b', label='real')
plt.legend(loc='best')
plt.show()
print(rmse.item()/num)
print(mae.item()/num)
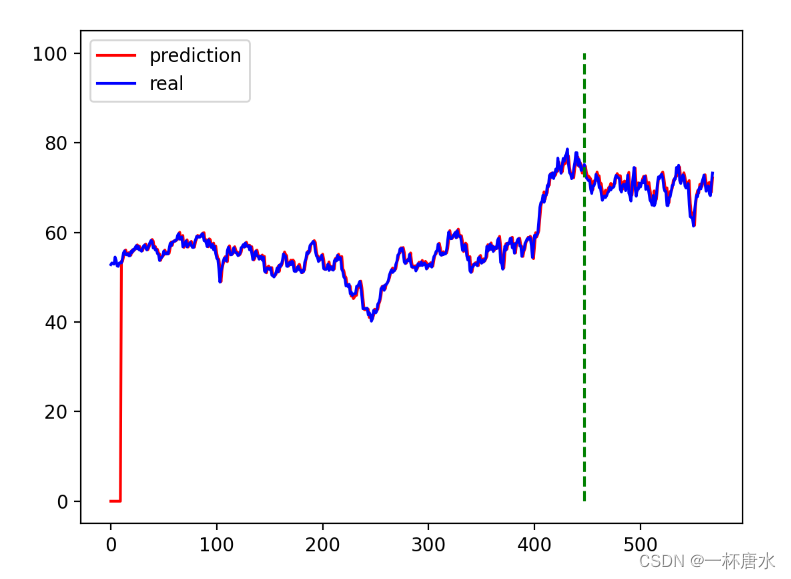
# pred_test = model(dataset_x) # 全量训练集
# pred_test = pred_test * (max_value - min_value) + min_value
# # 的模型输出 (seq_size, batch_size, output_size)
# pred_test = pred_test.view(-1).data.numpy()
# pred_test = np.concatenate((np.zeros(DAYS_FOR_TRAIN), pred_test)) # 填充0 使长度相同
# assert len(pred_test) == len(data_close)
#
# #绘图
# plt.plot(pred_test, 'r', label='prediction')
# plt.plot(data_close_1, 'b', label='real')
# plt.plot((train_size, train_size), (0, 100), 'g--') # 分割线 左边是训练数据 右边是测试数据的输出
# plt.legend(loc='best')
# plt.savefig('./img/result.png', format='png', dpi=200)
# plt.close()
if __name__ == '__main__':
data_close_1 = getdata_and_show()
# 将价格标准化到0~1
max_value = np.max(data_close_1)
min_value = np.min(data_close_1)
data_close = (data_close_1 - min_value) / (max_value - min_value)
dataset_x, dataset_y = create_dataset(data_close, DAYS_FOR_TRAIN)
# 先转为tensor
dataset_x = torch.from_numpy(dataset_x).reshape(-1, 1, DAYS_FOR_TRAIN)
dataset_y = torch.from_numpy(dataset_y).reshape(-1, 1, 1)
dataset = Data.TensorDataset(dataset_x, dataset_y)
# 划分训练集和测试集,80%作为训练集
train_size = int(len(dataset) * 0.8)
test_size = len(dataset) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(dataset, [train_size, test_size])
train_loader = Data.DataLoader(
dataset=train_dataset,
batch_size=64,
shuffle=True
)
test_loader = Data.DataLoader(
dataset=test_dataset,
batch_size=64,
shuffle=True
)
train_loss = []
test_loss = []
model = LSTM_Regression(DAYS_FOR_TRAIN, 8, output_size=1, num_layers=2) # 导入模型并设置模型的参数输入输出层、隐藏层等
loss_fn = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-2, betas=(0.9, 0.999), eps=1e-08, weight_decay=0)
if os.path.exists('./model/model_lstm_stock.pkl'):
model.load_state_dict(torch.load('./model/model_lstm_stock.pkl'))
test_model()
else:
train()
plt.figure()
plt.plot(train_loss, 'b', label='train_loss')
plt.plot(test_loss,"r",label="test_loss")
plt.title("Train_Loss_Curve")
plt.ylabel('train_loss')
plt.xlabel('epoch_num')
plt.legend(loc='best')
plt.savefig('./img/loss.png', format='png', dpi=200)
plt.close()
# for test
model = model.eval() # 转换成测试模式
test_model()














 706
706











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









