






文章目录
一、前言
记录自己的Transformer学习过程
二、 前缀知识
1.1 什么是self-attention
在自然语言处理中,self-attention可以将输入序列中的每个词向量与其他词向量进行比较,并根据它们之间的相似度来构建一个加权的表示。具体来说,就是通过计算一个query向量、一个key向量和一个value向量之间的点积得到相似度,然后按照相似度大小对value向量进行加权求和,得到一个经过自注意力机制处理后的词向量表示。这样处理后的词向量可以更好地表达输入序列中的语义关系。
在计算机视觉中,self-attention也可以用于图像中像素之间的关系建模,从而实现图像的分割和分类任务等。
1.2 self-attention 计算流程
- 首先将输入一串的Vetor (可以是你整个网络的输入也可以是隐藏层的输入),最终输出的也是一串Vetor,那么,如何产生这些输出的Vetor呢?
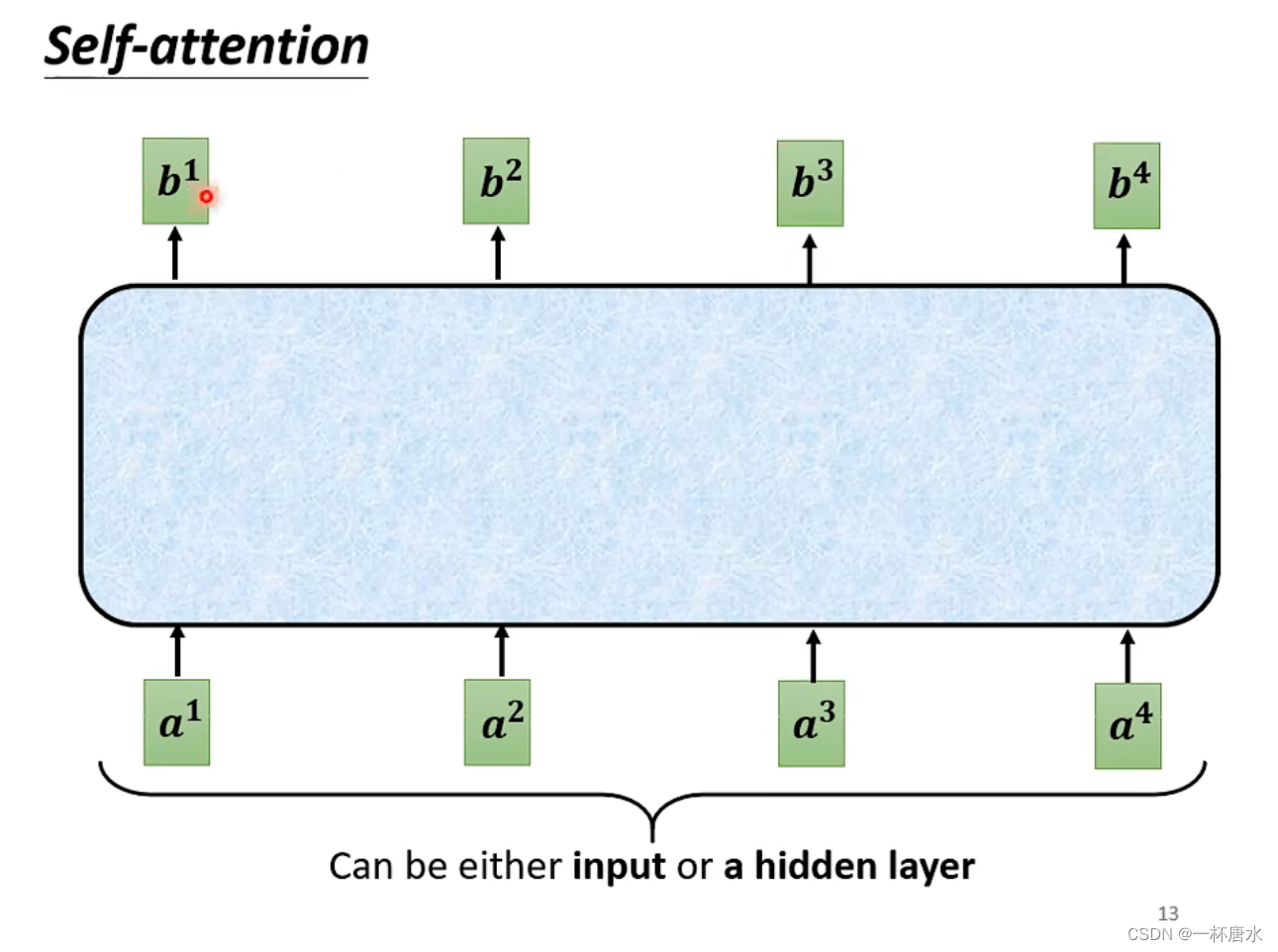
- self-attention的最终目的就是找出其他向量与你当前向量的关系(b1代表的就是a1 与 a2…a4之间的关系)如何找出这种关系呢?
总的来说就是使用两个不同的矩阵来乘以你的输入,生成q、k、v,再将q和k进行点积操作(Dot-product)操作得到一个中间值,再将所有算到的中间值进行进行Soft-max(也可以用其他操作)操作,将经过Soft-max得到的值与v进行相乘,抽取当前值与输入的Sequence重要的信息,再将乘积相加,就得到了b1,即输出的b1。b1…b4得到的方法都是类似。
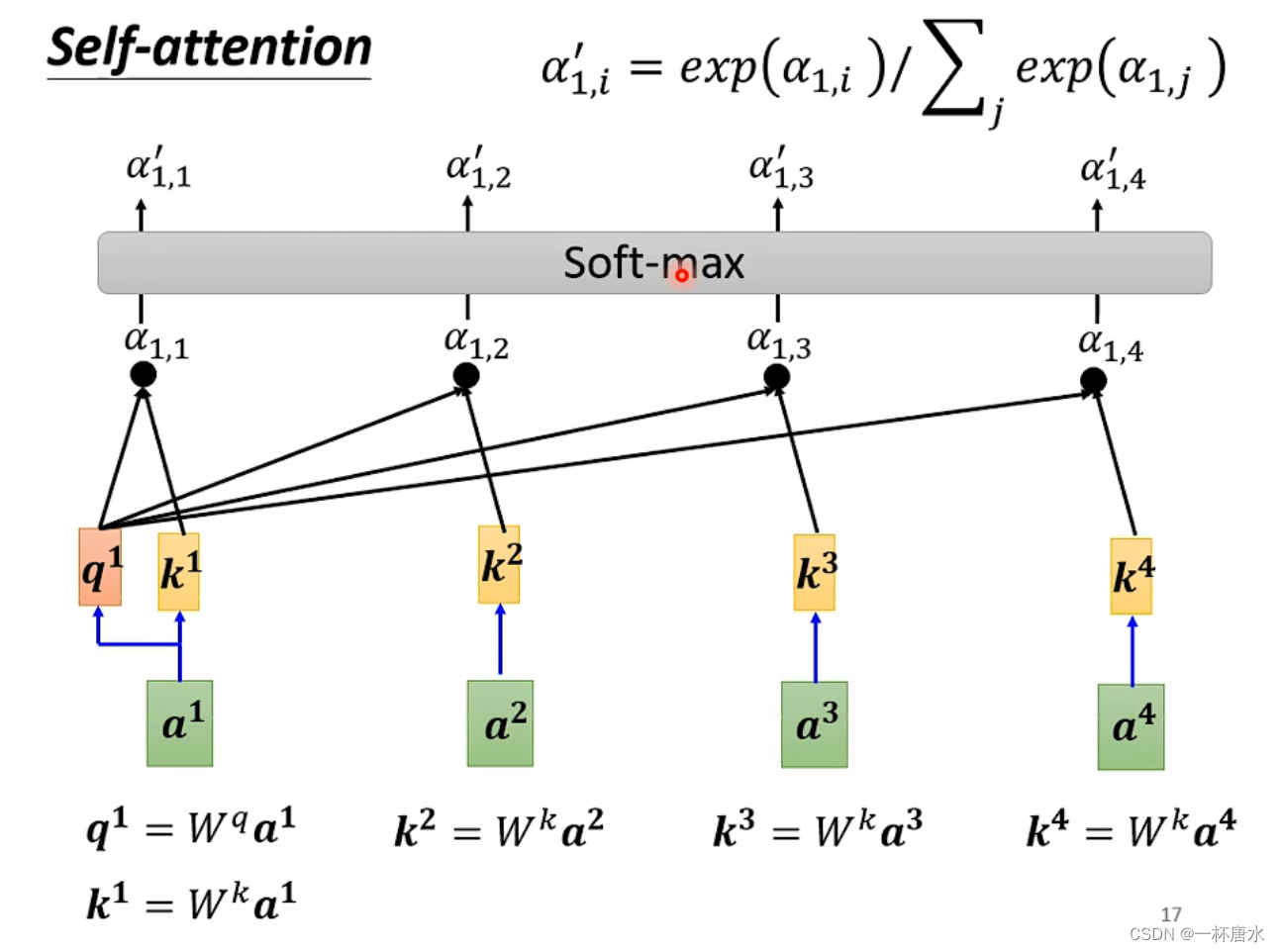
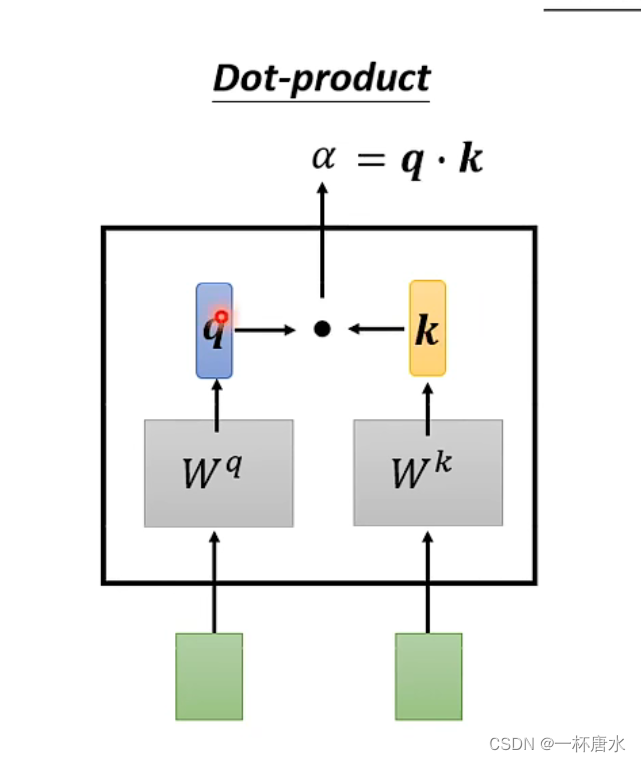
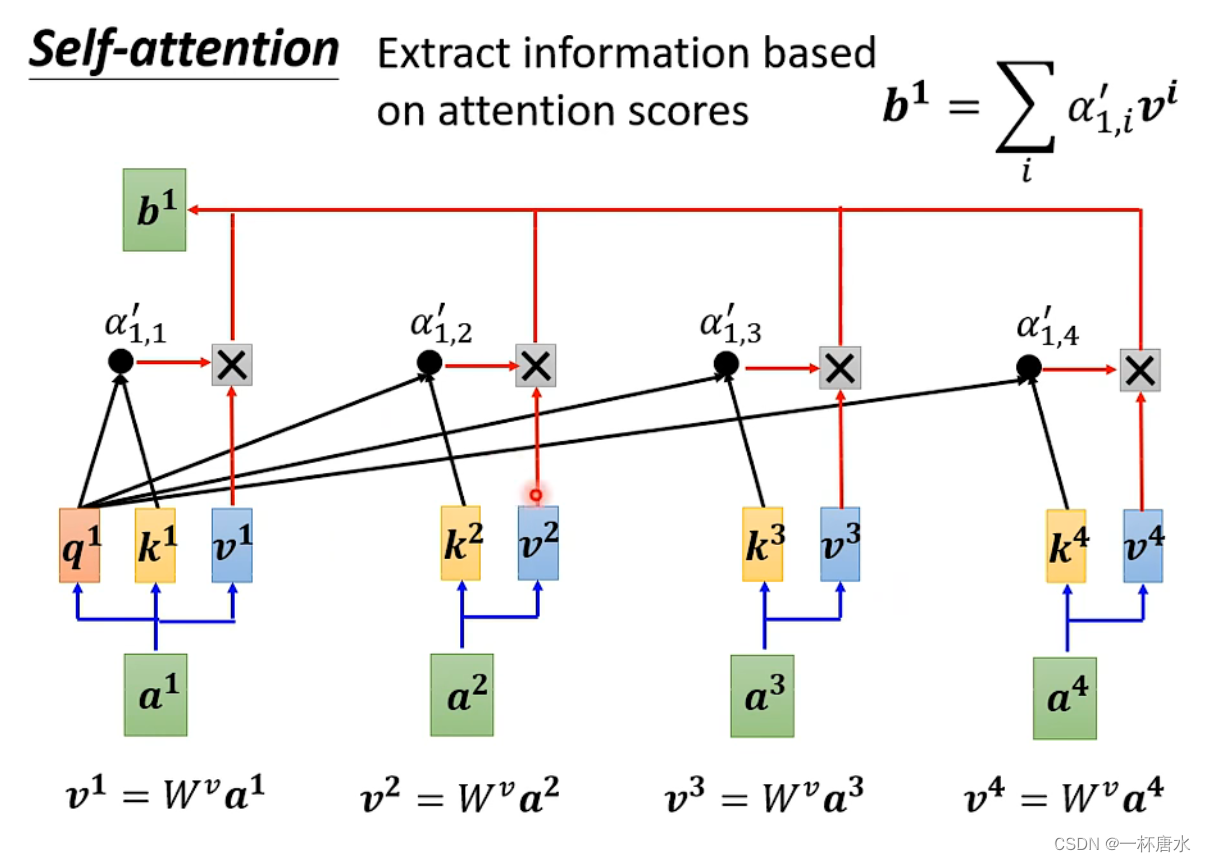
这里给出一个Dot-product的实现代码(Transformer中的操作)
class ScaledDotProductAttention(nn.Module):
def __init__(self):
super(ScaledDotProductAttention, self).__init__()
def forward(self, Q, K, V, attn_mask):
"""
Q: [batch_size, n_heads, len_q, d_k]
K: [batch_size, n_heads, len_k, d_k]
V: [batch_size, n_heads, len_v(=len_k), d_v]
attn_mask: [batch_size, n_heads, seq_len, seq_len]
说明:在encoder-decoder的Attention层中len_q(q1,..qt)和len_k(k1,...km)可能不同
"""
scores = torch.matmul(Q, K.transpose(-1, -2)) / \
np.sqrt(d_k) # scores : [batch_size, n_heads, len_q, len_k] matmul操作即矩阵相乘
# mask矩阵填充scores(用-1e9填充scores中与attn_mask中值为1位置相对应的元素)
# Fills elements of self tensor with value where mask is True.
scores.masked_fill_(attn_mask, -1e9)
attn = nn.Softmax(dim=-1)(scores) # 对最后一个维度(v)做softmax
# scores : [batch_size, n_heads, len_q, len_k] * V: [batch_size, n_heads, len_v(=len_k), d_v]
# context: [batch_size, n_heads, len_q, d_v]
context = torch.matmul(attn, V)
# context:[[z1,z2,...],[...]]向量, attn注意力稀疏矩阵(用于可视化的)
return context, attn
二、 Transformer
先来一张Transformer的全身照,第一眼看到总是痛苦的,但是细细品味,也是能够理解的
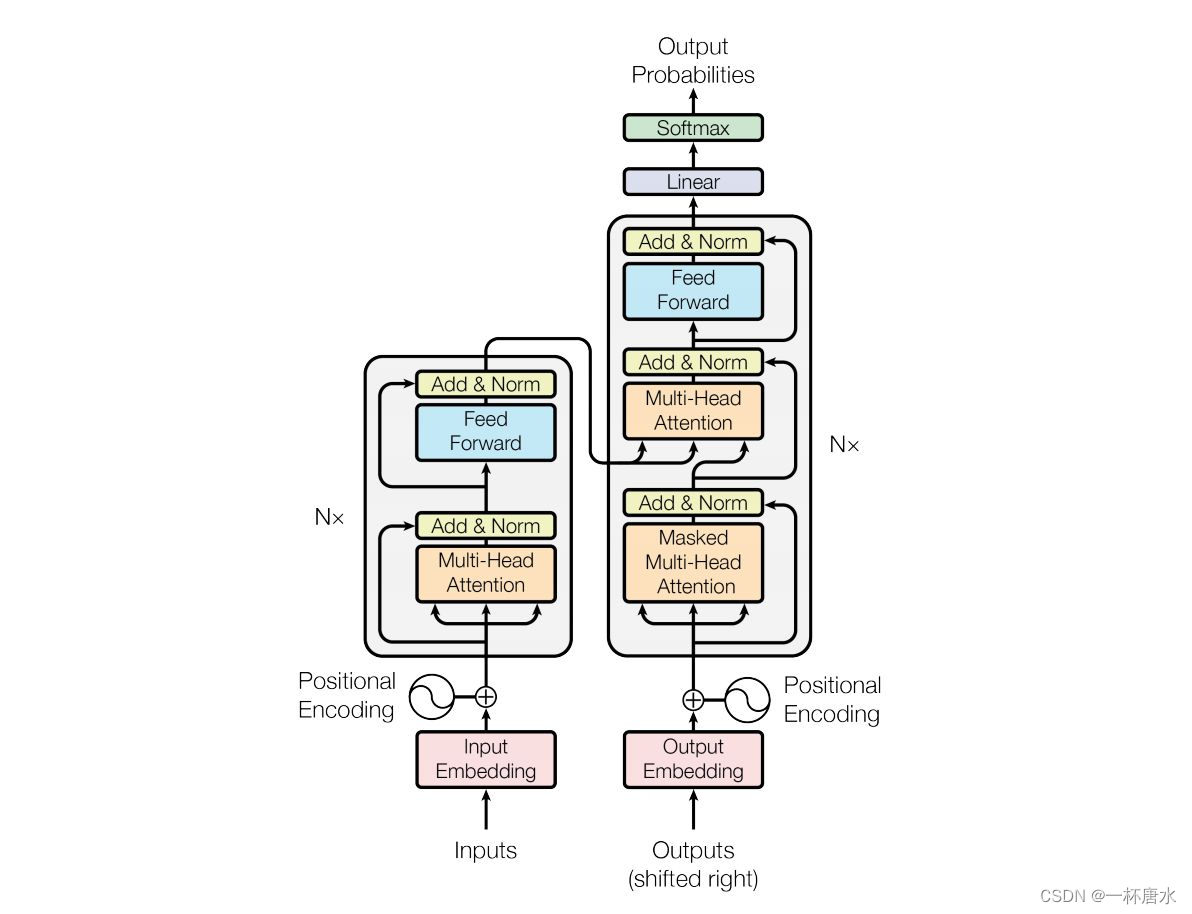
2.1 输入部分
Encoder 的输入是一段词向量,需要对原始输入进行分词,编码并转为tensor,并且,因为self-attention是并行的,会摧毁源数据的位置信息,为了保留位置信息,需要对每个词向量添加位置编码。

一个简单的例子:
# 训练集
sentences = [
# 中文和英语的单词个数不要求相同
# enc_input dec_input dec_output
['我 有 一 个 好 朋 友 P', 'S I have a good friend .', 'I have a good friend . E'],
['我 有 零 个 女 朋 友 P', 'S I have zero girl friend .', 'I have zero girl friend . E'],
['我 有 一 个 男 朋 友 P', 'S I have a boy friend .', 'I have a boy friend . E']
]
# 测试集(希望transformer能达到的效果)
# 输入:"我 有 一 个 女 朋 友"
# 输出:"i have a girlfriend"
# 中文和英语的单词要分开建立词库
# Padding Should be Zero
#1.cn
src_vocab = {'P': 0, '我': 1, '有': 2, '一': 3,
'个': 4, '好': 5, '朋': 6, '友': 7, '零': 8, '女': 9, '男': 10}
src_idx2word = {i: w for i, w in enumerate(src_vocab)}
src_vocab_size = len(src_vocab)
#2.en
tgt_vocab = {'P': 0, 'I': 1, 'have': 2, 'a': 3, 'good': 4,
'friend': 5, 'zero': 6, 'girl': 7, 'boy': 8, 'S': 9, 'E': 10, '.': 11}
idx2word = {i: w for i, w in enumerate(tgt_vocab)}
tgt_vocab_size = len(tgt_vocab)
def make_data(sentences):
"""把单词序列转换为数字序列"""
enc_inputs, dec_inputs, dec_outputs = [], [], []
for i in range(len(sentences)):
enc_input = [[src_vocab[n] for n in sentences[i][0].split()]]
dec_input = [[tgt_vocab[n] for n in sentences[i][1].split()]]
dec_output = [[tgt_vocab[n] for n in sentences[i][2].split()]]
# [[1, 2, 3, 4, 5, 6, 7, 0], [1, 2, 8, 4, 9, 6, 7, 0], [1, 2, 3, 4, 10, 6, 7, 0]]
enc_inputs.extend(enc_input)
# [[9, 1, 2, 3, 4, 5, 11], [9, 1, 2, 6, 7, 5, 11], [9, 1, 2, 3, 8, 5, 11]]
dec_inputs.extend(dec_input)
# [[1, 2, 3, 4, 5, 11, 10], [1, 2, 6, 7, 5, 11, 10], [1, 2, 3, 8, 5, 11, 10]]
dec_outputs.extend(dec_output)
return torch.LongTensor(enc_inputs), torch.LongTensor(dec_inputs), torch.LongTensor(dec_outputs)
enc_inputs, dec_inputs, dec_outputs = make_data(sentences)
位置编码公式:
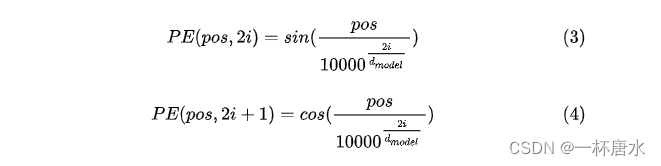
代码实现:
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=5000):
super(PositionalEncoding, self).__init__()
## 位置编码的实现其实很简单,直接对照着公式去敲代码就可以,下面这个代码只是其中一种实现方式;
## 从理解来讲,需要注意的就是偶数和奇数在公式上有一个共同部分,我们使用log函数把次方拿下来,方便计算;
## pos代表的是单词在句子中的索引,这点需要注意;比如max_len是128个,那么索引就是从0,1,2,...,127
##假设我的demodel是512,2i那个符号中i从0取到了255,那么2i对应取值就是0,2,4...510
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(
0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe)
def forward(self, x):
"""
x: [seq_len, batch_size, d_model]
"""
x = x + self.pe[:x.size(0), :]
return self.dropout(x)
2.2 Encoder
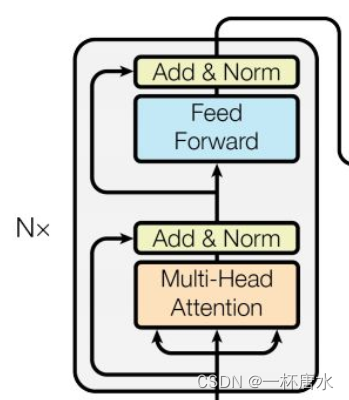
由上图可以看出,一个encoder由Multi-Head Attention 和 Feed Forward Network构成。
- 首先将输入的向量传入Multi-Head Attention,Multi-Head Attention机制只是在self-attention的基础上多运算了一次,并将最后的结果拼接即可。
2.2.1 Add&Normalize
将Multi-Head Attention的输出结果a与输入向量的b输入Add&Normalize模块,进行两个向量的相加当作新的输出,也就是input与output直接进行相加,这个过程也叫做Residual connection(残差连接),之后将输出值进行一个normalization操作,作为FC(FeedForward)的输入。
2.2.2 FeedForward
将FeedForward的输出与输入再做一个残差连接,并进行一个normalization操作,就得到了一个Encoder层的输出。
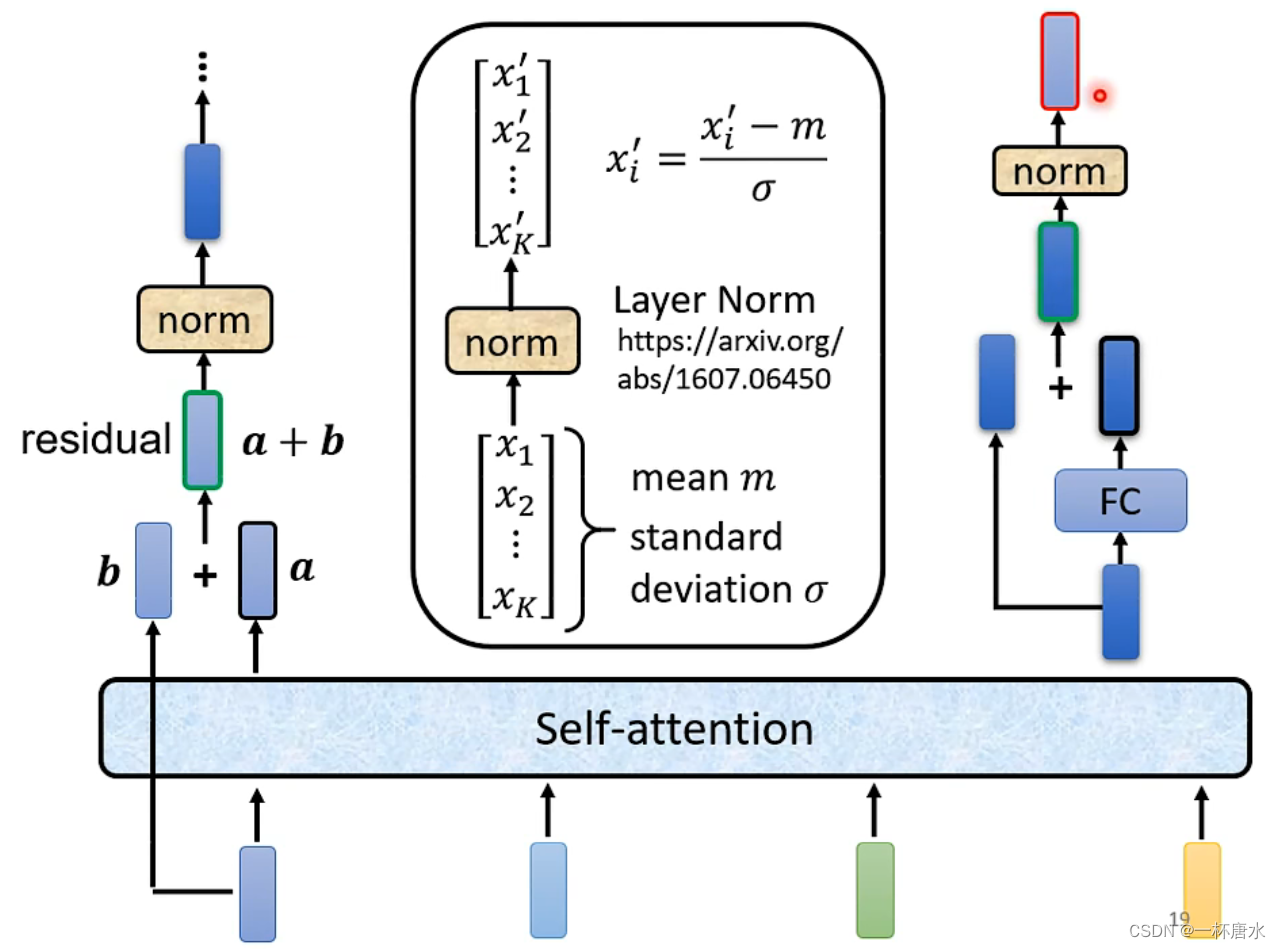
2.2.3 代码实现
Encoder整体代码实现:
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.src_emb = nn.Embedding(src_vocab_size, d_model) #这个其实就是去定义生成一个矩阵,大小是 src_vocab_size * d_model token Embedding
self.pos_emb = PositionalEncoding(d_model) # 位置编码情况,这里是固定的正余弦函数,也可以使用类似词向量的nn.Embedding获得一个可以更新学习的位置编码###Transformer中位置编码时固定的,不需要学习
self.layers = nn.ModuleList([EncoderLayer() for _ in range(n_layers)]) #使用ModuleList对多个encoder进行堆叠,因为后续的encoder并没有使用词向量和位置编码,所以抽离出来
def forward(self, enc_inputs):
"""
enc_inputs: [batch_size, src_len]
"""
enc_outputs = self.src_emb(enc_inputs) # [batch_size, src_len, d_model]
enc_outputs = self.pos_emb(enc_outputs.transpose(0, 1)).transpose(0, 1) # [batch_size, src_len, d_model]
# Encoder输入序列的pad mask矩阵
enc_self_attn_mask = get_attn_pad_mask(enc_inputs, enc_inputs) # [batch_size, src_len, src_len]
enc_self_attns = [] # 在计算中不需要用到,它主要用来保存你接下来返回的attention的值(这个主要是为了你画热力图等,用来看各个词之间的关系
for layer in self.layers: # for循环访问nn.ModuleList对象
# 上一个block的输出enc_outputs作为当前block的输入
# enc_outputs: [batch_size, src_len, d_model], enc_self_attn: [batch_size, n_heads, src_len, src_len]
enc_outputs, enc_self_attn = layer(enc_outputs,
enc_self_attn_mask) # 传入的enc_outputs其实是input,传入mask矩阵是因为你要做self attention
enc_self_attns.append(enc_self_attn) # 这个只是为了可视化
return enc_outputs, enc_self_attns
堆叠的Encoder:
class EncoderLayer(nn.Module):
def __init__(self):
super(EncoderLayer, self).__init__()
self.enc_self_attn = MultiHeadAttention()
self.pos_ffn = PoswiseFeedForwardNet()
def forward(self, enc_inputs, enc_self_attn_mask):
"""E
enc_inputs: [batch_size, src_len, d_model]
enc_self_attn_mask: [batch_size, src_len, src_len] mask矩阵(pad mask or sequence mask)
"""
# enc_outputs: [batch_size, src_len, d_model], attn: [batch_size, n_heads, src_len, src_len]
# 第一个enc_inputs * W_Q = Q
# 第二个enc_inputs * W_K = K
# 第三个enc_inputs * W_V = V
enc_outputs, attn = self.enc_self_attn(enc_inputs, enc_inputs, enc_inputs,
enc_self_attn_mask) # enc_inputs to same Q,K,V(未线性变换前)
enc_outputs = self.pos_ffn(enc_outputs)
# enc_outputs: [batch_size, src_len, d_model]
return enc_outputs, attn
MultiHeadAttention代码实现:
class MultiHeadAttention(nn.Module):
"""这个Attention类可以实现:
Encoder的Self-Attention
Decoder的Masked Self-Attention
Encoder-Decoder的Attention
输入:seq_len x d_model
输出:seq_len x d_model
"""
def __init__(self):
super(MultiHeadAttention, self).__init__()
self.W_Q = nn.Linear(d_model, d_k * n_heads,
bias=False) # q,k必须维度相同,不然无法做点积
self.W_K = nn.Linear(d_model, d_k * n_heads, bias=False)
self.W_V = nn.Linear(d_model, d_v * n_heads, bias=False)
# 这个全连接层可以保证多头attention的输出仍然是seq_len x d_model
self.fc = nn.Linear(n_heads * d_v, d_model, bias=False)
def forward(self, input_Q, input_K, input_V, attn_mask):
"""
input_Q: [batch_size, len_q, d_model]
input_K: [batch_size, len_k, d_model]
input_V: [batch_size, len_v(=len_k), d_model]
attn_mask: [batch_size, seq_len, seq_len]
"""
residual, batch_size = input_Q, input_Q.size(0)
# 下面的多头的参数矩阵是放在一起做线性变换的,然后再拆成多个头,这是工程实现的技巧
# B: batch_size, S:seq_len, D: dim
# (B, S, D) -proj-> (B, S, D_new) -split-> (B, S, Head, W) -trans-> (B, Head, S, W)
# 线性变换 拆成多头
# Q: [batch_size, n_heads, len_q, d_k]
Q = self.W_Q(input_Q).view(batch_size, -1,
n_heads, d_k).transpose(1, 2)
# K: [batch_size, n_heads, len_k, d_k] # K和V的长度一定相同,维度可以不同
K = self.W_K(input_K).view(batch_size, -1,
n_heads, d_k).transpose(1, 2)
# V: [batch_size, n_heads, len_v(=len_k), d_v]
V = self.W_V(input_V).view(batch_size, -1,
n_heads, d_v).transpose(1, 2)
# 因为是多头,所以mask矩阵要扩充成4维的
# attn_mask: [batch_size, seq_len, seq_len] -> [batch_size, n_heads, seq_len, seq_len]
attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1)
# context: [batch_size, n_heads, len_q, d_v], attn: [batch_size, n_heads, len_q, len_k]
context, attn = ScaledDotProductAttention()(Q, K, V, attn_mask)
# 下面将不同头的输出向量拼接在一起
# context: [batch_size, n_heads, len_q, d_v] -> [batch_size, len_q, n_heads * d_v]
context = context.transpose(1, 2).reshape(
batch_size, -1, n_heads * d_v)
# 这个全连接层可以保证多头attention的输出仍然是seq_len x d_model
output = self.fc(context) # [batch_size, len_q, d_model]
return nn.LayerNorm(d_model).to(device)(output + residual), attn
FeedForwardNet代码实现:使用全连接网络
也可以替换Conv1d
class PoswiseFeedForwardNet(nn.Module):
def __init__(self):
super(PoswiseFeedForwardNet, self).__init__()
self.fc = nn.Sequential(
nn.Linear(d_model, d_ff, bias=False),
nn.ReLU(),
nn.Linear(d_ff, d_model, bias=False)
)
def forward(self, inputs):
"""
inputs: [batch_size, seq_len, d_model]
"""
residual = inputs
output = self.fc(inputs)
# [batch_size, seq_len, d_model]
return nn.LayerNorm(d_model).to(device)(output + residual)
2.3 Decoder
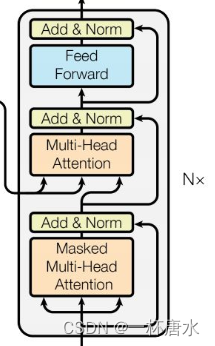
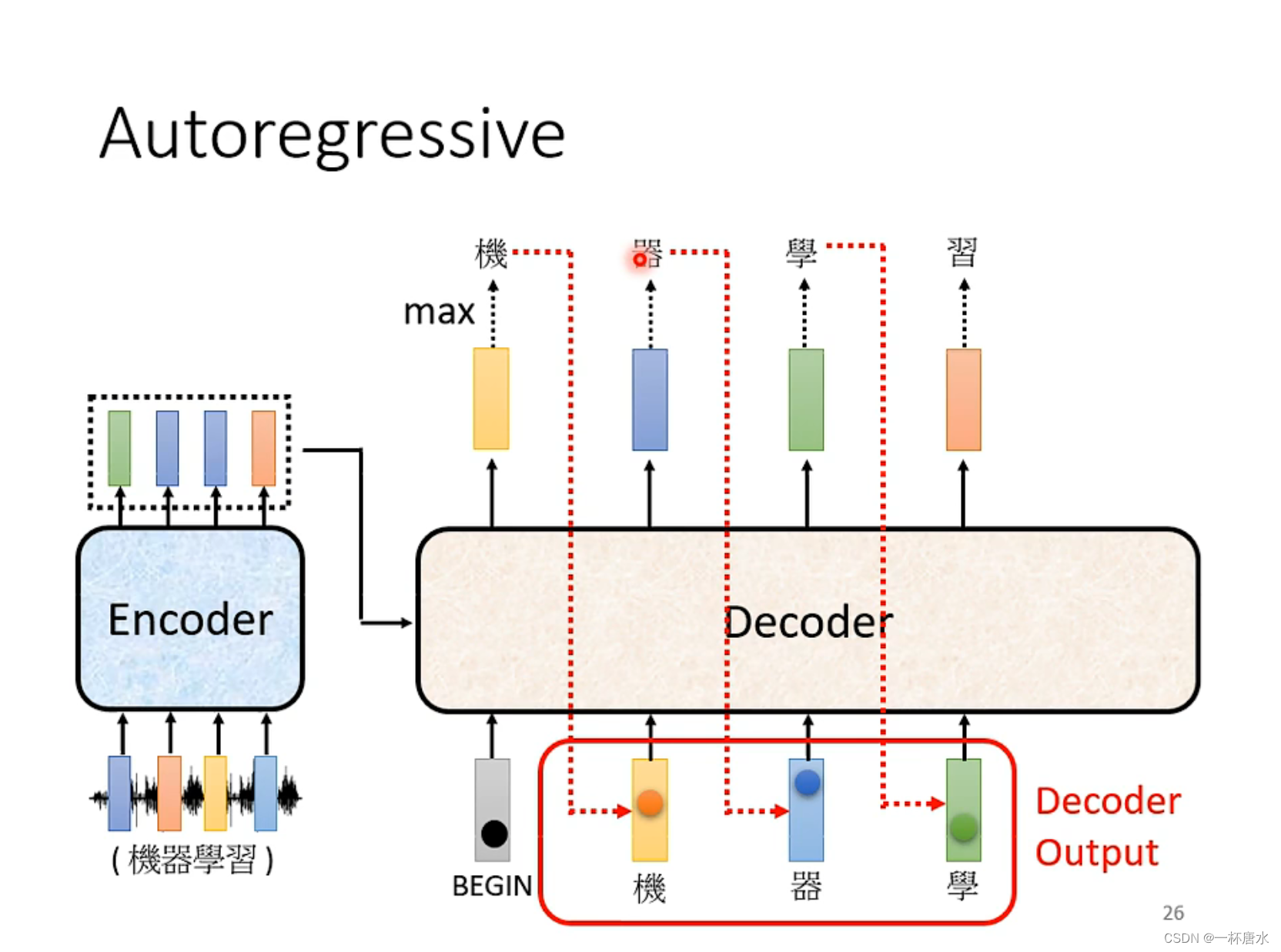
Decoder 部分的任务简单来说就是产生输出,Decoder接收到BEGIN信号后,将根据Encoder的output产生一个结果,此后将结果再次输入Decoder,再次与Encoder的输出进行运算,得到第二个结果,然后将得到的结果输入下一层的Decoder与输入的Encoder一起继续运算,再得到一个结果,如此反复。
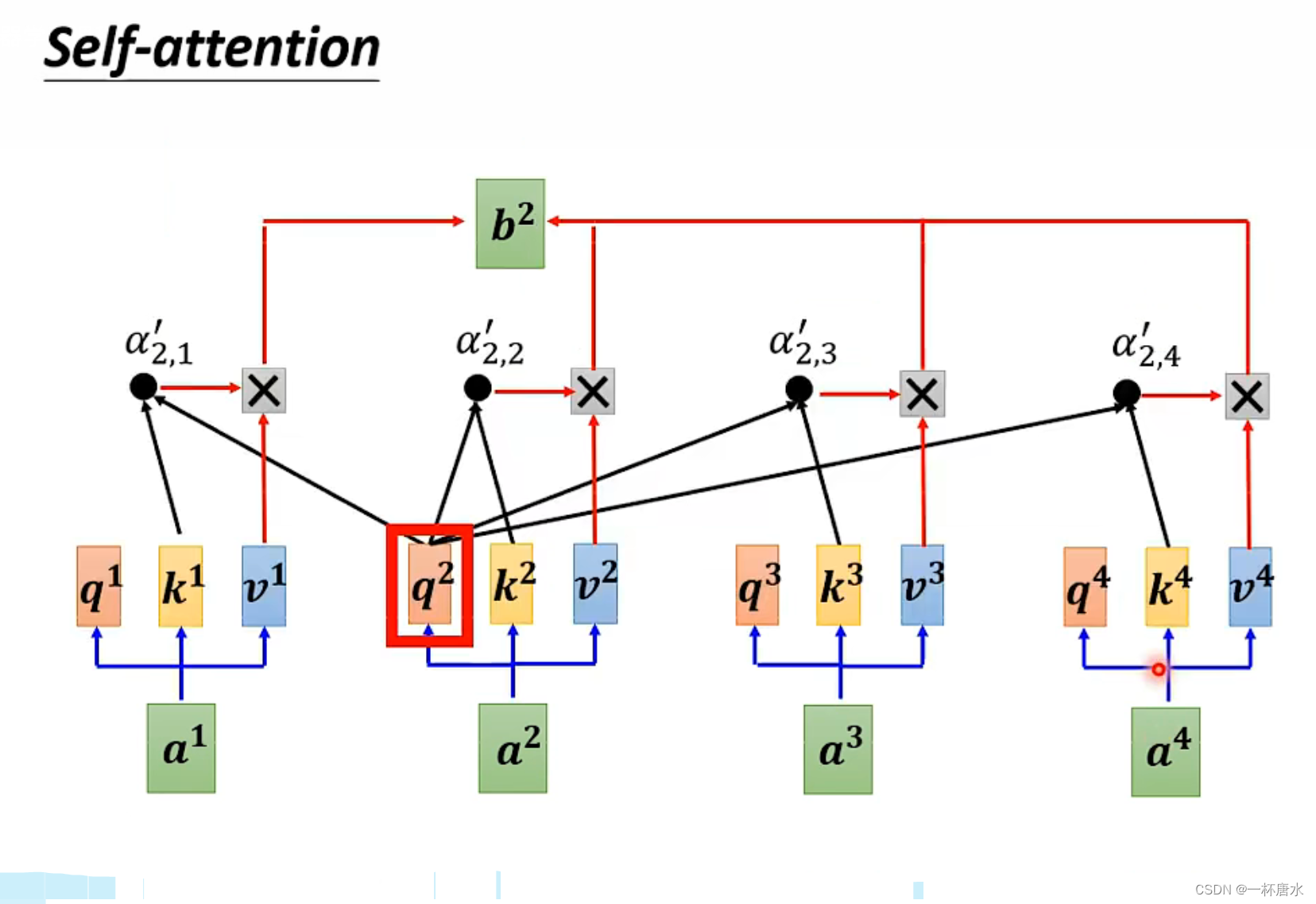
2.3.1 Masked Self-attention
当a2在Self-attention中想要产生一个输出b2时,需要考虑所有输入向量的信息
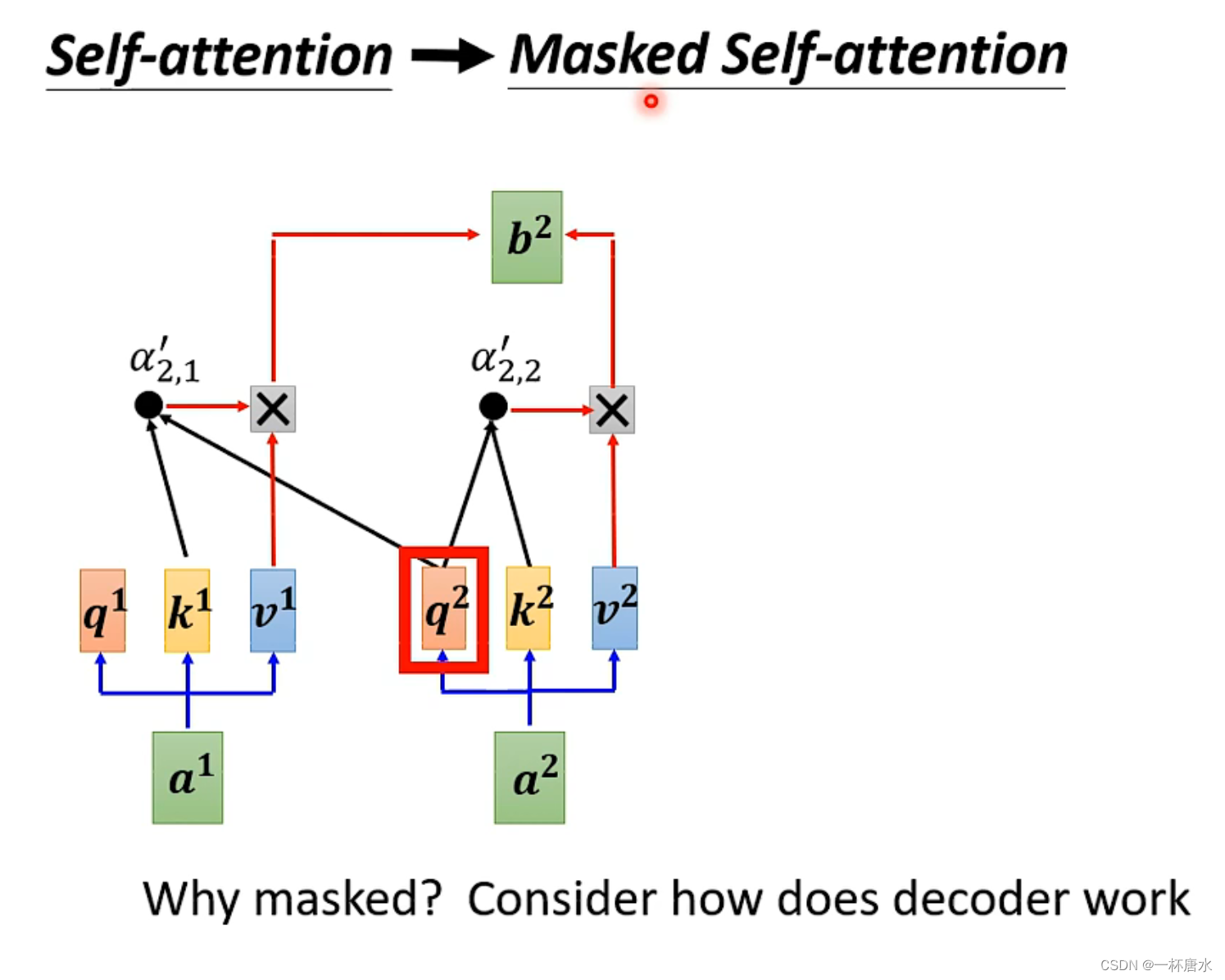
而在Masked Self-attention中不再考虑整体的信息,而是只考虑已有的向量,相当于a3、a4在计算b2时是未知的,同理,当产生b3时,a4相当于是未知的,就是说当前时刻是看不到未来的信息的
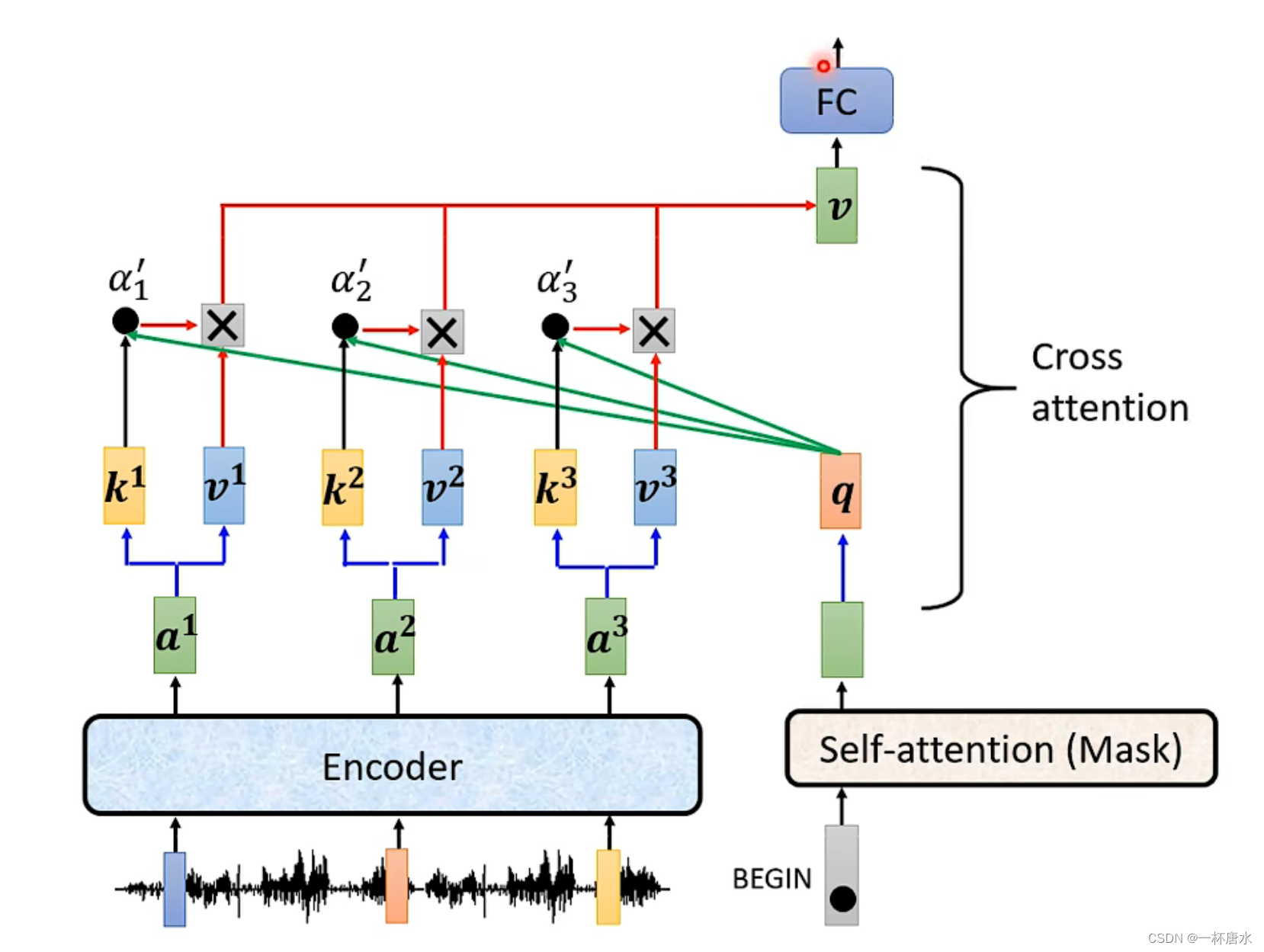
2.3.2 cross attention
连接encoder与decoder
运行开始后,decoder输入一个BEGIN信号,输出一个vector,将这个vector与权重矩阵相乘,得到q,将Encoder的输出,乘以权重矩阵,得到k与v,将decoder的q与encoder输出值的v与k相乘并经过softmax运算得到a值,与v值进行残差运算后加权,得到v,进而将v输出到后续的feedforward
decoder其他部分与encoder类似,就不再赘述
2.2.3 代码实现
decoder整体代码实现:
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.tgt_emb = nn.Embedding(
tgt_vocab_size, d_model) # Decoder输入的embed词表
self.pos_emb = PositionalEncoding(d_model)
self.layers = nn.ModuleList([DecoderLayer()
for _ in range(n_layers)]) # Decoder的blocks
def forward(self, dec_inputs, enc_inputs, enc_outputs):
"""
dec_inputs: [batch_size, tgt_len]
enc_inputs: [batch_size, src_len]
enc_outputs: [batch_size, src_len, d_model] # 用在Encoder-Decoder Attention层
"""
dec_outputs = self.tgt_emb(
dec_inputs) # [batch_size, tgt_len, d_model]
dec_outputs = self.pos_emb(dec_outputs.transpose(0, 1)).transpose(0, 1).to(
device) # [batch_size, tgt_len, d_model]
# Decoder输入序列的pad mask矩阵(这个例子中decoder是没有加pad的,实际应用中都是有pad填充的)
dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs).to(
device) # [batch_size, tgt_len, tgt_len]
# Masked Self_Attention:当前时刻是看不到未来的信息的
dec_self_attn_subsequence_mask = get_attn_subsequence_mask(dec_inputs).to(
device) # [batch_size, tgt_len, tgt_len]
# Decoder中把两种mask矩阵相加(既屏蔽了pad的信息,也屏蔽了未来时刻的信息)
dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequence_mask),
0).to(device) # [batch_size, tgt_len, tgt_len]; torch.gt比较两个矩阵的元素,大于则返回1,否则返回0
# 这个mask主要用于encoder-decoder attention层
# get_attn_pad_mask主要是enc_inputs的pad mask矩阵(因为enc是处理K,V的,求Attention时是用v1,v2,..vm去加权的,要把pad对应的v_i的相关系数设为0,这样注意力就不会关注pad向量)
# dec_inputs只是提供expand的size的
dec_enc_attn_mask = get_attn_pad_mask(
dec_inputs, enc_inputs) # [batc_size, tgt_len, src_len]
dec_self_attns, dec_enc_attns = [], []
for layer in self.layers:
# dec_outputs: [batch_size, tgt_len, d_model], dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len], dec_enc_attn: [batch_size, h_heads, tgt_len, src_len]
# Decoder的Block是上一个Block的输出dec_outputs(变化)和Encoder网络的输出enc_outputs(固定)
dec_outputs, dec_self_attn, dec_enc_attn = layer(dec_outputs, enc_outputs, dec_self_attn_mask,
dec_enc_attn_mask)
dec_self_attns.append(dec_self_attn)
dec_enc_attns.append(dec_enc_attn)
# dec_outputs: [batch_size, tgt_len, d_model]
return dec_outputs, dec_self_attns, dec_enc_attns
单层decoder实现:
class DecoderLayer(nn.Module):
def __init__(self):
super(DecoderLayer, self).__init__()
self.dec_self_attn = MultiHeadAttention()
self.dec_enc_attn = MultiHeadAttention()
self.pos_ffn = PoswiseFeedForwardNet()
def forward(self, dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask):
"""
dec_inputs: [batch_size, tgt_len, d_model]
enc_outputs: [batch_size, src_len, d_model]
dec_self_attn_mask: [batch_size, tgt_len, tgt_len]
dec_enc_attn_mask: [batch_size, tgt_len, src_len]
"""
# dec_outputs: [batch_size, tgt_len, d_model], dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len]
dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs, dec_inputs,
dec_self_attn_mask) # 这里的Q,K,V全是Decoder自己的输入
# dec_outputs: [batch_size, tgt_len, d_model], dec_enc_attn: [batch_size, h_heads, tgt_len, src_len]
dec_outputs, dec_enc_attn = self.dec_enc_attn(dec_outputs, enc_outputs, enc_outputs,
dec_enc_attn_mask) # Attention层的Q(来自decoder) 和 K,V(来自encoder)
# [batch_size, tgt_len, d_model]
dec_outputs = self.pos_ffn(dec_outputs)
# dec_self_attn, dec_enc_attn这两个是为了可视化的
return dec_outputs, dec_self_attn, dec_enc_attn

















 1020
1020

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









