









实例链接
之前List会创建iterator(迭代器),通过对象依次访问list种元素。这个设计理念是在单核机器上产生的。1
之前集合操作,或多或少会出现中间存储,增加垃圾回收的成本。代码冗长,以后维护非常耗时间,并且极易出错。
从集合到流
流与集合不同,因为它提供了一个可选的有序值序列而无须为这些值提供任何存储;它们是“移动种的数据”,这是一种表示批量数据操作的方式。流的目的是处理值。

图中的矩形表示称为map的操作,通过系统规则转换每一个流元素。
intList.stream().map(i -> new Point(i%3,i/3)).mapToDouble(p -> p.distance()).max();
从串行到并行
intList.parallelStream().map(i -> new Point(i%3,i/3)).mapToDouble(p -> p.distance()).max();
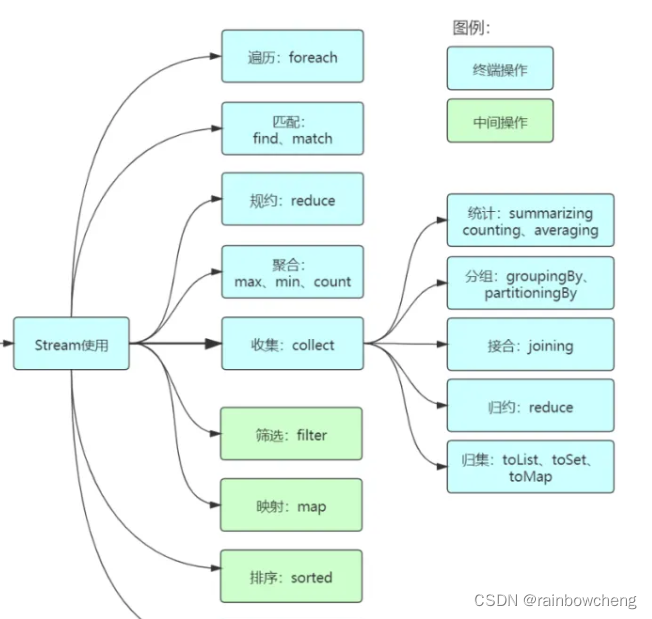
特性与优点
- 无存储:Stream不是一种数据结构,它只是某种数据源的一个视图,数据源可以是一个数组,java容器或I/O channel等。
- 为函数式编程:Stream任何修改不会修改背后的数据源。
- 惰式执行:Stream上操作不会立即执行,等用户真正需要结果的时候才会执行。
- 可消费性:Stream只能被“消费”一次,一旦遍历过就会失效。

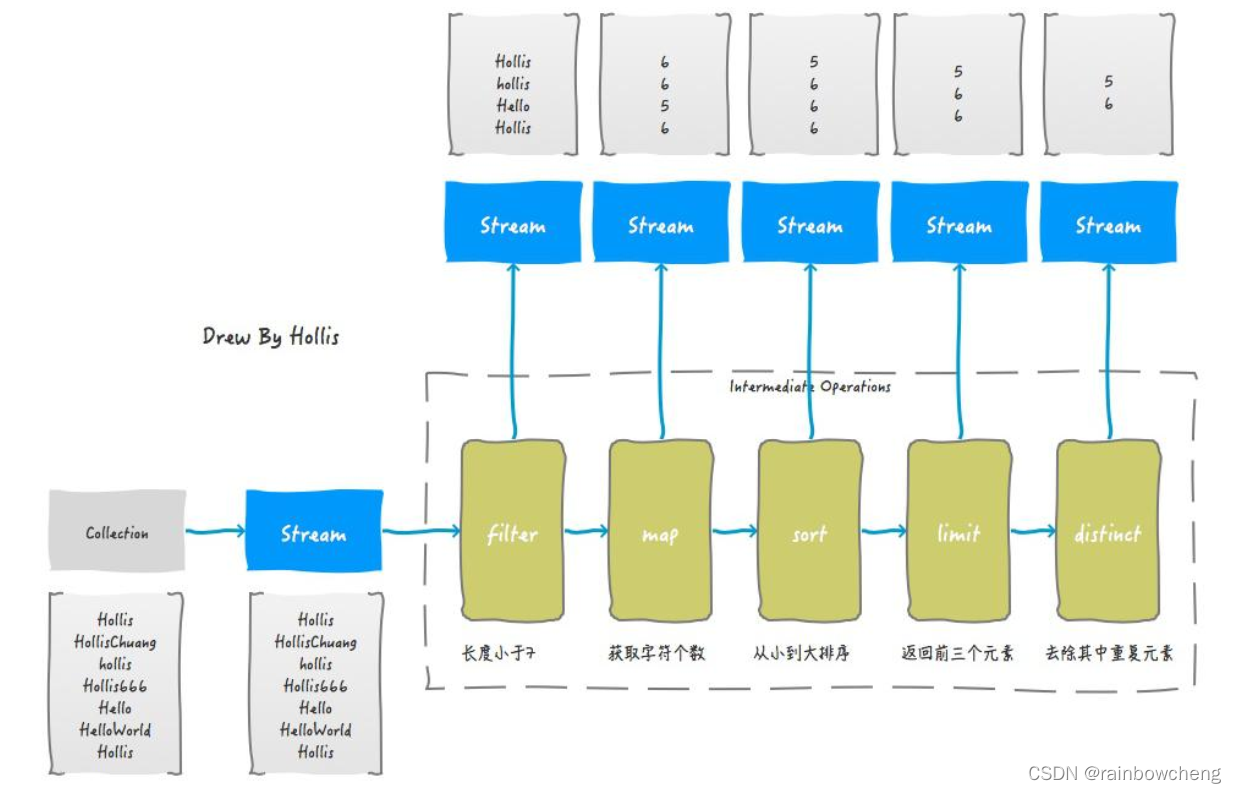
List<String> strings = Arrays.asList("Hollis", "HollisChuang", "hollis", "Hello", "HelloWorld", "Hollis");
Stream s = strings.stream().filter(string -> string.length()<=6)
.map(String::length).sorted().limit(3).distinct();
注意:flatMap接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流。
List<String> list = Arrays.asList("m,k,l,a", "1,3,5,7"); List<String> listNew = list.stream().flatMap(s -> { // 将每个元素转换成一个stream String[] split = s.split(","); Stream<String> s2 = Arrays.stream(split); return s2; }).collect(Collectors.toList());
常用组合
排序
intList.stream().map(i -> new Point(i%3,i/3)).sorted(comparing(p -> p.distance());
users.stream().sorted(Comparator.comparing(user::getChildrens,Comparator.comparing(list::size)));
// 按工资倒序排序
List<String> newList2 = personList.stream()
.sorted(Comparator.comparing(Person::getSalary).reversed())
.map(Person::getName).collect(Collectors.toList());
// 先按工资再按年龄升序排序
List<String> newList3 = personList.stream()
.sorted(Comparator.comparing(Person::getSalary)
.thenComparing(Person::getAge))
.map(Person::getName).collect(Collectors.toList());
// 先按工资再按年龄自定义排序(降序)
List<String> newList4 = personList.stream().sorted((p1, p2) -> {
if (p1.getSalary() == p2.getSalary()) {
return p2.getAge() - p1.getAge();
} else {
return p2.getSalary() - p1.getSalary();
}
}).map(Person::getName).collect(Collectors.toList());
最值(小、大)
users.stream().min(Comparator.comparingInt(User::getAge))
users.stream().max(new Comparator<User>(){
public int compare(User o1,User o2) {
return o1.getAge().compareTo(o2.getAge());
}
})
Integer max2 = list.stream().reduce(1, Integer::max)
Integer maxSalary = personList.stream().reduce(0,
(max, p) -> max > p.getSalary() ? max : p.getSalary(),
Integer::max);
Optional<Integer> max = list.stream().reduce((x, y) -> x > y ? x : y);
ProductLimitPrice::getLowestPrice 等于 (meta) -> meta.getLowestPrice()
ClsName::new 等于 (args) -> new ClsName(args)
RefType::staticMethod 等于 (args)->RefType.staticMethod(args)
求和
integerList.stream().mapToInt(Integer::intValue).sum();
integerList.stream().reduce(Integer::sum);
integerList.stream().mapToInt(Integer::intValue).reduce(0,(a,b) -> a+b);
integerList.stream().reduce(0, Integer::sum)
汇聚方法:sum、min、max、count、average;
如果对数据做一次遍历后得到多个结果需要:summaryStatistics
DoubleSummaryStatistics collect = personList.stream().collect(Collectors.summarizingDouble(Person::getSalary))
平均值
Double average = personList.stream().collect(Collectors.averagingDouble(Person::getSalary));
分组
Map<String, List<User>> map=users.stream().collect(Collectors.groupingBy(User::getState, Collectors.toList()));
list转map
users.stream().collect(Collectors.toMap(User::getId, user -> user));
过滤
users.stream().filter(u -> u.getStatus==1).collect(Collectors.toList());
collect将流值积聚到容器中,toList、toSet 、toMap、joining(拼接)、toCollection(Object::new)自定义
去重
users.stream().map(User::getName).distinct().collect(Collectors.toList());
List<String> newList = Stream.concat(stream1, stream2).distinct().collect(Collectors.toList());
limit(100)前 ,skip(100)除去前。 Collectors.toSet()集合
// concat:合并两个流 distinct:去重
List newList = Stream.concat(stream1, stream2).distinct().collect(Collectors.toList());
// limit:限制从流中获得前n个数据 [1, 3, 5, 7, 9, 11, 13, 15, 17, 19]
List collect = Stream.iterate(1, x -> x + 2).limit(10).collect(Collectors.toList());
// skip:跳过前n个数据[3, 5, 7, 9, 11]
List collect2 = Stream.iterate(1, x -> x + 2).skip(1).limit(5).collect(Collectors.toList());
汇聚 reduce
- reduce(BinaryOperator);
- reduce(T,BinaryOperator);
- reduce(U,BiFunction<U,T,U>,BinaryOperatorU);
列子:
// 求工资之和方式1:
Optional<Integer> sumSalary = personList.stream().map(Person::getSalary).reduce(Integer::sum);
// 求工资之和方式2:
Integer sumSalary2 = personList.stream().reduce(0,
(sum, p) -> sum += p.getSalary(),
(sum1, sum2) -> sum1 + sum2);
Integer sum = personList.stream().collect(Collectors.reducing(0, Person::getSalary, (i, j) -> i + j ));
// 求工资之和方式3:
Integer sumSalary3 = personList.stream().reduce(0, (sum, p) -> sum += p.getSalary(), Integer::sum);
第三个相对与增加map(函数转换),对集合某个属性聚合。
三个方法可以用与stream、collectors
//流对象用法
Stream<BigInteger> bgStream = LongStream.of(1,2,3).mapToObj(BigInteger::valueOf);
Optional<BigInteger> obgSum = bgStream.reduce(BigInteger::add);
BigInteger bgSum= bgStream.reduce(BigInteger.ZERO,BigInteger::add);
//积聚对象用法
Comparator<Book> htComp=Comparator.comparing(Book::getHeight);
Map<Topic,Optional<Book>> maxHeightByTopic = libraty.stream().collect(Collectors.groupingBy(Book::getTopic,reducing(Binaryoperator.maxBy(htComp))));
SDK包
java.util.function.Function 接口
非lambda表达式集合分组
package com.huaying.chuhai;
import java.util.Collection;
import java.util.LinkedHashMap;
import java.util.LinkedList;
import java.util.List;
import java.util.Map;
/**
* @author rainbow
* @date 2021-01-26 12:48
*/
public class ListUtil {
/**
* list 集合分组
*
* @param list 待分组集合
* @param groupBy 分组Key算法
* @param <K> 分组Key类型
* @param <V> 行数据类型
* @return 分组后的Map集合
*/
public static <K, V> Map<K, List<V>> groupBy(List<V> list, GroupBy<K, V> groupBy) {
return groupBy((Collection<V>) list, groupBy);
}
/**
* list 集合分组
*
* @param list 待分组集合
* @param groupBy 分组Key算法
* @param <K> 分组Key类型
* @param <V> 行数据类型
* @return 分组后的Map集合
*/
public static <K, V> Map<K, List<V>> groupBy(Collection<V> list, GroupBy<K, V> groupBy) {
Map<K, List<V>> resultMap = new LinkedHashMap<K, List<V>>();
for (V e : list) {
K k = groupBy.groupBy(e);
if (resultMap.containsKey(k)) {
resultMap.get(k).add(e);
} else {
List<V> tmp = new LinkedList<V>();
tmp.add(e);
resultMap.put(k, tmp);
}
}
return resultMap;
}
/**
* List分组
*
* @param <K> 返回分组Key
* @param <V> 分组行
*/
public interface GroupBy<K, V> {
K groupBy(V row);
}
}
Map<Integer,List<CouponClassify>> CouponClassifyMap = ListUtil.groupBy(couponClassifies,new ListUtil.GroupBy<Integer,CouponClassify>(){
@Override
public Integer groupBy(CouponClassify row){
return row.getCouponId();
}
});</pre>
Map CouponClassifyMap = ListUtil.groupBy(couponClassifies,new ListUtil.GroupBy(){
@Override
public Integer groupBy(CouponClassify row){
return row.getCouponId();
}
});
Optional.ofNullable(describe).map(String::toString).orElse(“默认值”)















 1475
1475











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











