






一行命令实现看图说话|Google的im2txt模型

1.项目介绍
这次给大家介绍一个google的深度学习模型im2txt,这个模型的作用跟它的名字一样,image-to-text,把图像转为文字,也就是图片描述。
这个模型是使用 2015 MSCOCO Image Captioning Challenge 的数据集训练出来的
我对原始googel的项目做了很多简化,减少了项目前期准备,优化了效果展示。
im2txt模型是一个深度神经网络模型,可以实现如下图像描述的效果:

对于生活中常见的一些场景,它还是可以比较正确地描述出图片中的情况。
该模型是一个encoder-decoder模型。encoder是编码器,它是一个CNN模型,常用于图像识别,目标检测等领域。各种常见的卷积网络都可以,比如,VGG,Inception,ResNet等等。这里我们用的是使用 ILSVRC-2012-CLS数据集训练出来的Inception-V3模型。把图片输入Inception-V3中,可以得到一个固定长度的向量,这个向量可以看成是从图像中提取出来的特征。
decoder是解码器,它是一个LSTM模型,常用于语言模型或机器翻译等领域。我们把encoder中输出的固定长度的向量输入到decoder中,获得关于图像的描述。如下图所示:
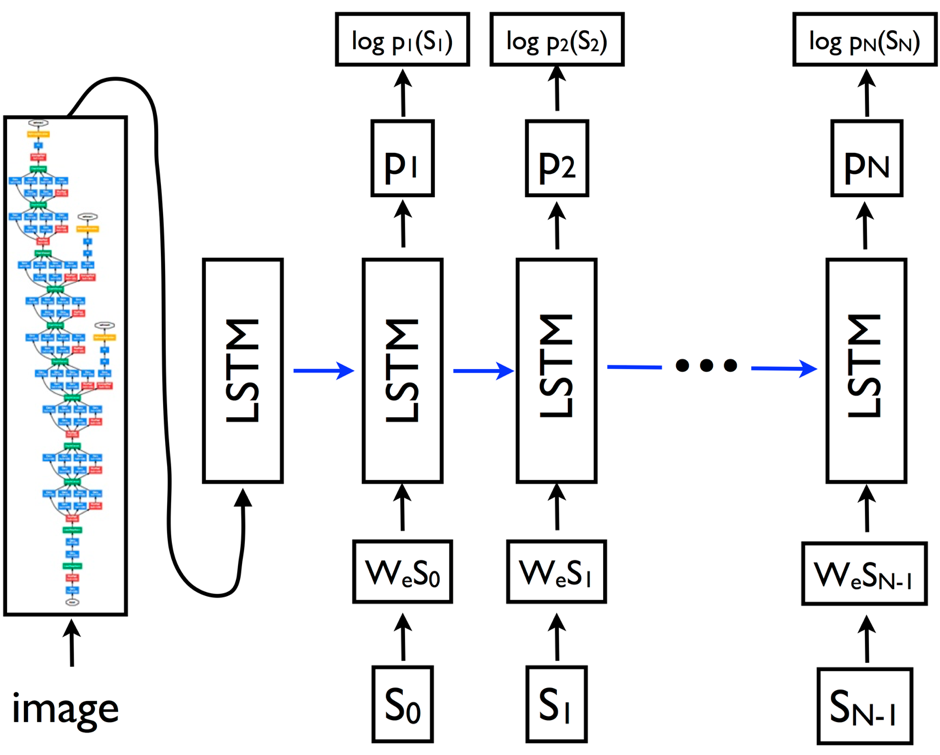
图中的{s0, s1, …, sN-1} 表示图像的描述,每个s代表一个词,图中的{wes0, wes1, …, wesN-1} 是每个词的词向量,比如word2vec。输出的{p1, p2, …, pN} 表示LSTM模型预测句子中的下一个词所对应的概率分布。{log p1(s1), log p2(s2), …, log pN(sN)}表示正确词的对数似然估计。
2.环境准备
我的实验环境为:
- Python-3.6
- Tensorflow-1.12
其他版本的软件基本上也适用。
Python的安装建议使用Anaconda
Anaconda下载
Tensorflow的安装在Anaconda安装完以后使用命令 pip install tensorflow 安装。
3.模型准备
因为github上放模型不方便,所以训练好的模型我存放在我的百度云盘上,大家可以通过云盘下载。
百度云盘链接
密码:khtx
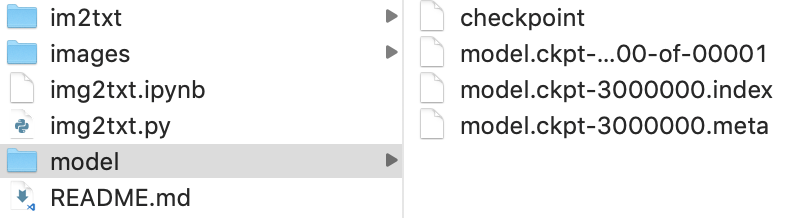
模型下载好之后解压,然后把几个模型相关的文件存入项目文件夹的根目录中的model文件夹中,如下图:
4.运行模型
- im2txt文件夹中是项目主要程序
- images文件夹中是需要测试的图片
- model文件夹中是训练好的模型
- img2txt.py是可以直接执行的python文件
- img2txt.ipynb是jupyter文件,推荐使用
显示看图说话只需要执行一行命令,在项目文件根目录执行:python img2txt.py或者用jupyter打开img2txt.ipynb,在jupyter中运行可以更方便查看运行结果。
5.运行效果
我随机着了一些照片来测试,其中包含一张我养的猫的照片。图片的标题为模型给出的预测结果。

这张照片识别效果还是很好的,正确描述了图片中的主要物体鸟,并且正确识别了鸟的数量两只,图片的背景水也识别出来了。
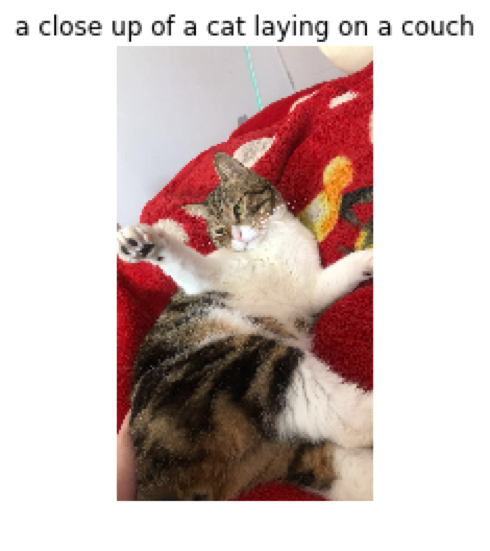
我家的猫,模型给出的描述是“一张猫的特写图片,一只猫躺在沙发上”,描述基本上也算是比较正确。

预测结果是“一个年轻的男孩在草地上踢足球”,这个描述完全正确。

预测结果是“一个男人在冲浪板上冲浪”,描述也比较正确。
上面都是一些好的结果,当然也会很多识别不好的结果,比如下面这些:

预测结果为“一个女人穿着粉红色的雨伞站在人行道上”,因为模型本身没有日常的生活常识,所以它不知道人是不会穿着粉红色雨伞在身上的。同时它对动作的描述不够准确,这个人穿着芭蕾舞裙,并且她是在跳舞。

预测结果为“水上冲浪板上的人”,这次模型的预测结果就错得离谱了。因为图中没有人,也没有冲浪板。我们看到这幅图第一感觉应该是被图中漂亮的极光所吸引,不过模型还不具备欣赏美景的能力,所以它的没有注意到天上绿绿的光,和漫天星空,它只看到了这个石头有点像人,石头旁边的陆地有点像冲浪板。
总的看来,这个模型可以比较好的识别比较简单的场景的,不过由于它不具备推理能力,没有生活常识,欣赏能力,所以一些复杂情况的图片它就不能很好的判断了。
6.视频描述
既然AI可以做图像描述,那么视频描述肯定也是可以的。
video2txt.py是可以直接执行的python文件,可以传入一个视频并生成一个带有描述的新的视频
video2txt.ipynb是对应的jupyter文件
我找到星爷的经典电影大话西游来做测试,我们理想的效果应该是:

但实际上是:



很显然AI现在还看不懂电影,大家纯属娱乐就可以。
视频:
视频链接
完整项目代码可以到我的github下载
我的github
喜欢的朋友,记得star和follow哦。
7.作者介绍



















 3197
3197

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











