







本文经授权转载自机器之心(almosthuman2014),未经授权禁止二次转载与摘编。
本文长度为3200字,建议阅读9分钟
本文带你了解亚马逊AI实验室的开源机器学习工具。
[ 摘要 ]最近,来自亚马逊上海 AI 实验室、亚马逊 AI 北美、明尼苏达大学、俄亥俄州立大学、湖南大学等机构的团队,正式开源了大规模药物重定位知识图谱 DRKG和一套完整的用于进行药物重定位研究的机器学习工具,助力新冠及其他疾病的药物重定位研究。
自 2019 年 12 月至今,新型冠状病毒在全球迅速扩散已导致近 760 万人感染,40 余万人死亡。目前急需快速有效的新冠病毒有效药物的发现路径。药物重定位是一种将现有药物用于治疗新的适应症的药物发现方式。相比较传统的新药开发,它可以有效缩短药物研发周期,降低成本,规避风险,是一种非常有前景的新冠肺炎治疗策略。
近日,亚马逊上海 AI 实验室联合来自亚马逊 AI 北美、明尼苏达大学、俄亥俄州立大学、湖南大学的研究者,共同构建了大规模药物重定位知识图谱 DRKG(Drug Repurposing Knowledge Graph),以及一套完整的用于进行药物重定位研究的机器学习工具,并将其在 github 上开源给全世界研究机构,帮助相关研究人员更有效地对新冠病毒及其它疾病(如阿尔茨海默病)进行药物重定位研究。
项目地址:
https://github.com/gnn4dr/DRKG
如下图所示,DRKG 是一个综合型生物医药知识图谱,包含人类基因、化合物、生物过程、药物副作用、疾病和症状等六个主要方面的数据。DRKG 从六个公开的大型医药数据库以及近期新冠病毒的相关医学文献中挖掘并数据,并进行整理和规范。DRKG 知识图谱包含分属于 13 种实体类型 97238 个实体,以及分属于 107 种关系类型 5874261 个三元组数据。
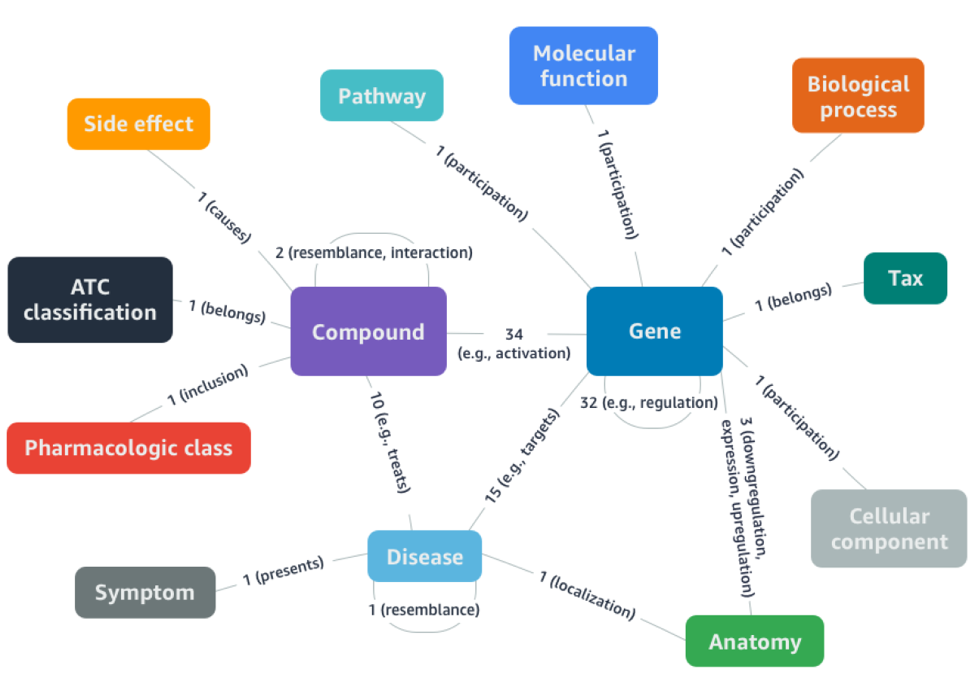 Drug Repurposing Knowledge Graph
Drug Repurposing Knowledge Graph
机器学习工具使用了先进的深度图学习方法(DGL-KE)来学习 DRKG 中实体和关系的低维向量表示(embeddings), 并使用这些 embedding 来预测药物治疗疾病的可能性或药物与疾病靶点结合的可能性。
DGL-KE 是亚马逊上海 AI 实验室开源的一款专门针对大规模知识图谱嵌入表示的训练工具,同时支持单机多 GPU 和多机分布式训练。在 AWS EC2 平台上,一台 p3.16xlarge(8 GPUs)可以在 100 分钟内训练完成 Freebase 数据集(8600 万节点,3 亿条边)。4 台 r5dn.24xlarge(4*48 CPUs) 可以在 30 分钟内完成训练。
项目地址:
https://github.com/awslabs/dgl-ke
DRKG 在其开源代码仓库中提供了使用 DGL-KE 来生成 DRKG 知识图谱中实体和关系的低纬嵌入向量表示的案例以及基于预训练的 DRKG 知识图谱嵌入向量表示预测新冠病毒候选药物的案例。
案例链接:
https://github.com/gnn4dr/DRKG/blob/master/embedding_analysis/Train_embeddings.ipynb
https://github.com/gnn4dr/DRKG/blob/master/drug_repurpose/COVID-19_drug_repurposing.ipynb
初步的实验结果表明:使用此类机器学习工具进行冠状病毒的药物发现,能以较高的分数识别出目前正在进行临床试验的多种冠状病毒候选药物。
使用 DGL-KE 生成 DRKG 知识图谱的低纬嵌入向量表示
DGL-KE 是一个基于 DGL 图深度学习框架(https://github.com/dmlc/dgl),面向知识图谱嵌入学习方法领域的高性能、高可扩展的开源软件库,DRKG 利用 DGL-KE 软件包进行 DRKG 知识图谱的低纬嵌入向量表示的生成。
下载 DRKG 知识图谱,DRKG 知识图谱已开源:
https://dgl-data.s3-us-west-2.amazonaws.com/dataset/DRKG/drkg.tar.gz
import sys
sys.path.insert(1, '../utils')
from utils import
download_and_extractdownload_and_extract()
drkg_file = '../data/drkg/drkg.tsv'
DRKG 知识图谱包含一个 tsv 格式文件 drkg.tsv,其中包含了知识图谱的所有三元组,在训练之前,我们将数据集随机按照 0.9:0.05:0.05 的比例划分成训练集、验证集和测试集。
import pandas as pd
import numpy as np
df = pd.read_csv(drkg_file, sep="\t")
triples = df.values.tolist()
seed = np.arange(num_triples)
np.random.shuffle(seed)
train_cnt = int(num_triples * 0.9)
valid_cnt = int(num_triples * 0.05)
train_set = seed[:train_cnt]
train_set = train_set.tolist()
valid_set = seed[train_cnt:train_cnt+valid_cnt].tolist()
test_set = seed[train_cnt+valid_cnt:].tolist()
with open("train/drkg_train.tsv", 'w+') as f:
for idx in train_set:
f.writelines("{}\t{}\t{}\n".format(triples[idx][0], triples[idx][1], triples[idx][2]))
with open("train/drkg_valid.tsv", 'w+') as f:
for idx in valid_set:
f.writelines("{}\t{}\t{}\n".format(triples[idx][0], triples[idx][1], triples[idx][2]))
with open("train/drkg_test.tsv", 'w+') as f:
for idx in test_set:
f.writelines("{}\t{}\t{}\n".format(triples[idx][0], triples[idx][1], triples[idx][2]))
随后直接调用 DGL-KE 软件包的命令行进行 DRKG 知识图谱的低纬嵌入向量表示训练,案例中我们选用 TransE_l2 知识图谱嵌入算法,并使用了 AWS p3.16xlarge 实例进行多 GPU 并行进行训练(使用其他知识图谱嵌入算法以及其他机型可以参考 https://aws-dglke.readthedocs.io/en/latest/index.html 中的说明)。
!DGLBACKEND=pytorch dglke_train --dataset DRKG --data_path ./train --data_files
drkg_train.tsv drkg_valid.tsv drkg_test.tsv --format 'raw_udd_hrt' --model_name
TransE_l2 --batch_size 2048 \--neg_sample_size 256 --hidden_dim 400 --gamma
12.0 --lr 0.1 --max_step 100000 --log_interval 1000 --batch_size_eval 16 -adv --
regularization_coef 1.00E-07 --test --num_thread 1 --gpu 0 1 2 3 4 5 6 7 --
num_proc 8 --neg_sample_size_eval 10000 --async_update
训练完成后我们将得到两个文件: 1) DRKG_TransE_l2_entity.npy, DRKG 中实体的低维向量表示和 2)DRKG_TransE_l2_relation.npy,DRKG 中关系的低维向量表示。后续我们可以使用训练好的实体和关系的低维向量表示进行药物预测。
node_emb = np.load('./ckpts/TransE_l2_DRKG_0/DRKG_TransE_l2_entity.npy')
relation_emb =
np.load('./ckpts/TransE_l2_DRKG_0/DRKG_TransE_l2_relation.npy')
完整案例可以在此获取:
https://github.com/gnn4dr/DRKG/blob/master/embedding_analysis/Train_embeddings.ipynb
使用预训练的 DRKG 知识图谱的嵌入向量预测新冠病毒候选药物
在论文《Repurpose Open Data to Discover Therapeutics for COVID-19 using Deep Learning》中,亚马逊 AI、湖南大学、克里夫兰诊所勒纳中心基因组医学研究所、明尼苏达大学的研究者提出了结合使用知识图谱的嵌入和基因集富集分析的方法来进行新冠病毒老药新用药物的预测。DRKG 基于该论文的思路,提供了基于预训练的 DRKG 知识图谱嵌入向量表示进行新冠病毒候选药物预测案例。
论文地址:
https://arxiv.org/abs/2005.10831
首先我们将基于 DRKG 知识图谱的新冠病毒的药物预测问题定义为预测药物和新冠病毒实体之间存在'Hetionet::CtD::Compound:Disease'和‘GNBR::T::Compound:Disease'关系(即治疗 treatment 关系)的置信度评估问题。
首先,我们选取 DRKG 中来自 Drugbank 的分子量 (molecule weight) 大于 250 的 FDA 获准药物实体作为可选药物集,同时选取 DRKG 知识图谱中存在的 34 个新冠病毒相关实体作为目标病毒集。然后,我们预测所有可能的(药物,治疗,病毒)三元组组合在 TrainsE_l2 算法下的分数(score),并最终对分数进行排序,并选取分数最高的 100 个药物作为推荐药物。具体方法实施如下:
设定目标病毒实体、药物实体和治疗关系。
# 目标新冠病毒相关实体
COV_disease_list = ['Disease::SARS-CoV2 E','Disease::SARS-CoV2 M', ...]
# 药物疾病治疗相关关系
treatment = ['Hetionet::CtD::Compound:Disease','GNBR::T::Compound:Disease']
# 获取来自 Drugbank 的分子量 (molecule weight) 大于 250 的 FDA 获准药物实体(已在 infer_drug.tsv 中提供
drug_list = []
with open("./infer_drug.tsv", newline='', encoding='utf-8') as csvfile:
reader = csv.DictReader(csvfile, delimiter='\t', fieldnames=['drug','ids'])
for row_val in reader:
drug_list.append(row_val['drug'])
获取预训练 DRKG 知识图谱的嵌入表示
# 读取预训练 embedding
entity_emb = np.load('../data/drkg/embed/DRKG_TransE_l2_entity.npy')
rel_emb = np.load('../data/drkg/embed/DRKG_TransE_l2_relation.npy')
drug_ids = th.tensor(drug_ids).long()
disease_ids = th.tensor(disease_ids).long()
treatment_rid = th.tensor(treatment_rid)
drug_emb = th.tensor(entity_emb[drug_ids])
treatment_embs = [th.tensor(rel_emb[rid]) for rid in treatment_rid]
所有可能(的药物,治疗,病毒)三元组组合在 TrainsE_l2 算法下的分数(score),计算公式如下:
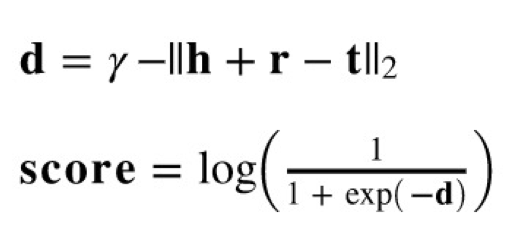
其中,h 为 head 即药物,r 为关系,t 为 tail 即病毒。gamma 为训练中使用的常数。
import torch.nn.functional as fn
gamma=12.0
def transE_l2(head, rel, tail):
score = head + rel - tail
return gamma - th.norm(score, p=2, dim=-1)
scores_per_disease = []
dids = []
# 针对两种治疗关系分别计算(药物,治疗,病毒)三元组的分数,并最终合并
for rid in range(len(treatment_embs)):
treatment_emb=treatment_embs[rid]
for disease_id in disease_ids:
disease_emb = entity_emb[disease_id]
score = fn.logsigmoid(transE_l2(drug_emb, treatment_emb, disease_emb))
scores_per_disease.append(score)
dids.append(drug_ids)
scores = th.cat(scores_per_disease)
对分数进行排序
idx = th.flip(th.argsort(scores), dims=[0])
scores = scores[idx].numpy()
dids = dids[idx].numpy()
获取最终 topk 的药物推荐
topk=100
_, unique_indices = np.unique(dids, return_index=True)
topk_indices = np.sort(unique_indices)[:topk]
# top100 的药物 ID
proposed_dids = dids[topk_indices]
# top100 的分数
proposed_scores = scores[topk_indices]
最终得到的药物中,目前已经处于临床实验的有 6 例,具体结果如下(排名,药物名称,相关分数)
[0] Ribavirin -0.21416784822940826[4] Dexamethasone -0.9984006881713867[8] Colchicine -1.080674648284912[16] Methylprednisolone -1.1618402004241943[49] Oseltamivir -1.3885014057159424[87] Deferoxamine -1.513066053390503
完整案例可以在此处获取:
https://github.com/gnn4dr/DRKG/blob/master/drug_repurpose/COVID-19_drug_repurposing.ipynb
编辑:黄继彦



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









