







作者:王可汗
本文约2700字,建议阅读5分钟本文分析了训练过程里内存开销。在上一篇介绍数据并行的文章中,我们介绍了常见的数据并行策略—DP和DDP,详细讨论了他们的基本工作原理和区别。而在实践中并不需要手动实现这样的分布式训练或者内存优化算法,已经有很多开源的训练框架将其实现并封装成软件包,比如常见的就是微软的DeepSpeed,他可以和LlamaFactory这样的训练工具集成使用。DeepSpeed集成了零冗余优化器(ZeRO Redundancy Optimizer, ZeRO)。具体来说,零冗余优化器将参数内存占用分成3类,分别对应3个阶段的优化。在介绍DeepSpeed的三阶段优化之前,首先需要分析一下训练过程里内存开销。
内存开销主要分为两部分:Model States和Residual States。Model States指和模型本身直接相关的,包括:(1)模型参数:神经网络权重;(2)优化器状态:例如Adam优化算法里的动量(momentum)和方差(variance);(3)模型梯度。Residual States是训练过程中额外会产生的内容,包括前向计算得到的激活中间结果,存储待反向传播时计算梯度使用,还有临时存储,即模型实现中的其他计算临时变量,这些用完后尽快释放。

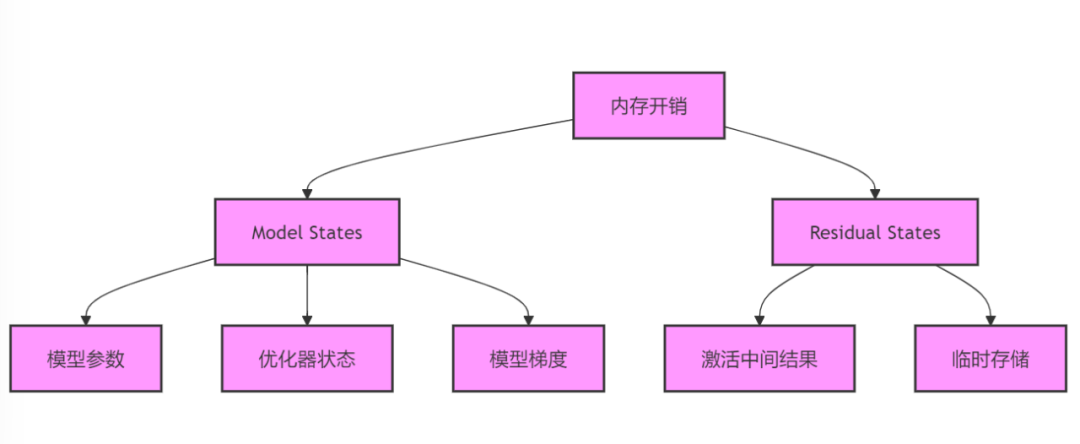
图1 内存开销的组成
知道了内存开销的组成,如果想知道一个参数量为Φ的模型占用多少内存,就需要了解另一项技术——混合精度训练。
所谓混合精度训练,并不是简单地将模型参数和激活精度直接降低到半精度(FP16),这么做会导致严重地模型精度损失或参数溢出问题,其过程一般如图2所示。
混合精度训练它结合使用单精度(fp32)和半精度(fp16)计算来加速模型训练,同时减少内存使用。在这种训练方法中,模型参数、优化器的动量和方差最初以单精度(fp32)格式存储,以确保数值稳定性。在前向传播之前,这些fp32参数被转换为半精度(fp16)格式,以减少内存使用并加速计算。使用fp16格式的参数进行前向传播,计算激活值,同样以fp16格式存储。这些激活值用于计算损失函数,评估模型预测与实际标签之间的差异。随后,损失函数的结果用于反向传播,计算梯度,这些梯度也是以fp16格式存储的。最后,计算得到的fp16梯度用于更新原本的fp32格式的模型参数、动量和方差,这一步确保了参数更新的精度。通过在大部分计算中使用fp16来加速训练,同时保留fp32来确保参数更新的精度,混合精度训练在不牺牲模型性能的情况下,显著提高了训练速度和减少了内存消耗。

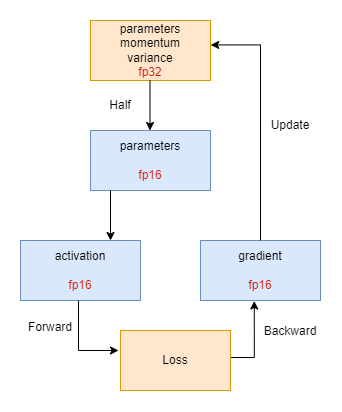
图2 混合精度训练示意图
现在,可以来计算模型在训练时需要的存储大小了,假设模型的参数大小是 Φ ,以byte为单位,存储如下(这里暂不将activation纳入统计范围内):
在“必要存储”这一类别中,包含了模型的参数、优化过程中的动量以及方差,这些数据均采用32位浮点数(即fp32格式)进行存储,每项数据占用的空间为4Φ,整体累计占用空间为12Φ。“临时存储”类别则涵盖了以16位浮点数(即fp16格式)存储的模型参数和计算过程中产生的梯度信息,每项数据占用的空间为2Φ,累计占用空间为4Φ。综合所有类别,总的存储空间需求为16Φ。需要指出的是,因为我们一直使用Adam优化方法,因此涉及到了动量和方差的存储。如果选用其他的优化算法,这些数据可能就不需要存储。为了表述的普适性,必须将模型存储的数据量定义为KΦ,这样,总的内存消耗可以表示为2Φ+2Φ+KΦ。
在了解了哪些元素占用存储空间以及它们各自占用的存储大小之后,我们便可以探讨如何优化存储使用。可以观察到,在训练过程中,并非所有数据都需要持续保留。例如:
在使用Adam算法时,优化器的状态(optimizer state)仅在执行参数更新步骤时才需要。
模型参数(parameters)仅在前向传播(forward)和反向传播(backward)过程中需要。
基于这些观察,ZeRO优化技术采取了一种直接的方法:如果某些数据在计算完成后就不再需要,那么在需要时再从其他来源重新获取这些数据,从而节省存储空间。下面我们就可以讨论3个阶段是如何通过减少不必要的数据保留,优化了存储资源的使用。
Stage 1 优化器参数划分,每个节点仅更新自己分片的参数。
如图3所示,整体流程如下:

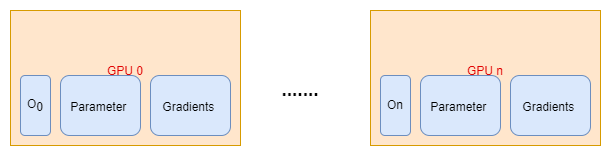
图3 优化器优化示意图
(1) 每个GPU保存完整的模型参数W。将一个batch的数据分成n份,分给各个GPU。做完一轮的前向和反向计算后,每个GPU会得到一份梯度。
(2) 对梯度做一次环状全归约,得到完整的梯度,对All-Reduce不熟悉的朋友可以去看数据并行的上一篇文章,这个过程里产生的单卡通信量是2Φ。
(3) 得到完整的梯度,我们就可以对参数W进行更新。参数W的更新依赖于优化器状态O和梯度。所以每个GPU只能更新对应的参数W。我们需要对参数W进行一次All-Gather,使得所有GPU完成所有参数的更新。产生的单卡通讯量是Φ。
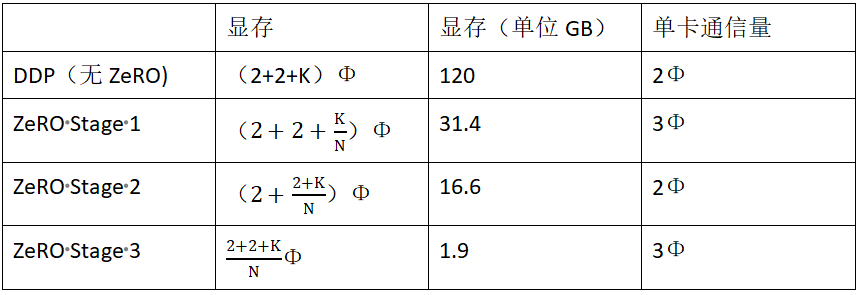
设GPU的个数为N, 我们可以列表去比较一下DDP和优化器优化两者的显存和单卡通讯量,这里我们假设将模型必须存储的数据量为12Φ(K=12),模型参数7.5B,N=64.

在我们的假设下,我们单卡显存降低了4倍,但是单卡通信量只增加1.5倍。看起来是一个不错的改进,那么还可以做的更好吗 ?
Stage 2 梯度划分,每个节点仅保留需要更新自己优化器状态对应的梯度
答案是可以!我们可以将梯度拆分到各个GPU上。
我们刚刚Stage1的分析中,发现由于W的更新依赖于优化器状态和梯度,所以在更新时只能更新相应的参数W。所以Stage 1得到完整的梯度会有一部分的内存冗余,Stage 2对此进行了改进。整体流程如下:
(1)每个GPU保存完整的模型参数W。将一个batch的数据分成n份,分给各个GPU。做完一轮的前向和反向计算后,每个GPU会得到一份梯度。
(2)每个GPU中我们只维护一部分梯度(图4中的绿色部分),所以此时我们只进行Reduce-Scatter操作。目的是使得GPU维护的对应的梯度得到聚合结果。黄色的梯度部分无用,可以丢弃。这个过程的单卡通讯量为Φ。
(3)每个GPU用自己对应的优化器状态和梯度去更新相应的W。此时对W做一次All-Gather,使得所有GPU完成所有参数的更新。产生的单卡通信量是Φ
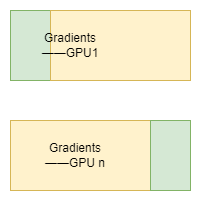
图4 梯度划分示意图
我们接着讨论显存和通信量:

Stage 2的优化将存储降了近8倍,而单卡通信量持平,实现内存开销的进一步优化,那么还可以进一步优化吗?
Stage 3 模型参数划分,在前向和后向计算时将模型参数自动分配到不同节点。
(1)每个GPU保存部分的模型参数W。将一个batch的数据分成n份,分给各个GPU。
(2)做前向计算时,需要完整的W计算输出。对W做一次All-Gather,取回分布在别的GPU 上的W,得到一份完整的W。单卡通信量为Φ。前向计算做完,立刻把不是自己维护的W抛弃。(是不是和梯度划分很类似?)
(3)做反向计算时,对W做一次All-Gather, 取回完整的W,单卡通信量Φ。反向计算做完,立刻把不是自己维护的W抛弃。
(4)做完反向计算后,得到梯度G,对G做一次Reduce-Scatter,从别的GPU上聚合自己维护的那部分梯度,单卡通信量Φ。聚合操作结束后,立刻把不是自己维护的G抛弃。
(5)用自己维护的优化器状态和梯度G更新W。由于只维护部分W,因此无需再对W做任何All-Reduce操作。
最后我们列表一起比较一下ZeRO三个阶段的显存和单卡通信量情况:
编辑:于腾凯
校对:林亦霖
作者简介
王可汗,清华大学博士,人工智能算法研发工程师。对数据科学产生浓厚兴趣,对机器学习AI充满好奇。期待着在科研道路上,人工智能与工业界应用碰撞出别样的火花。希望结交朋友分享更多数据科学的故事,用数据科学的思维看待世界。
数据派研究部介绍
数据派研究部成立于2017年初,以兴趣为核心划分多个组别,各组既遵循研究部整体的知识分享和实践项目规划,又各具特色:
算法模型组:积极组队参加kaggle等比赛,原创手把手教系列文章;
调研分析组:通过专访等方式调研大数据的应用,探索数据产品之美;
系统平台组:追踪大数据&人工智能系统平台技术前沿,对话专家;
自然语言处理组:重于实践,积极参加比赛及策划各类文本分析项目;
制造业大数据组:秉工业强国之梦,产学研政结合,挖掘数据价值;
数据可视化组:将信息与艺术融合,探索数据之美,学用可视化讲故事;
网络爬虫组:爬取网络信息,配合其他各组开发创意项目。
点击文末“阅读原文”,报名数据派研究部志愿者,总有一组适合你~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派THUID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
未经许可的转载以及改编者,我们将依法追究其法律责任。
关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU
点击“阅读原文”拥抱组织


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









