







本文约4600字,建议阅读9分钟本文将介绍在风控实践中积累起来的一些标准化的工作,包括遇到的问题和采取的解决方案,以期构建一个好的智能风控工具体系。本文由融360高级数据算法工程师王欢老师带来“构建智能风控工具体系”的分享,将介绍在风控实践中积累起来的一些标准化的工作,包括遇到的问题和采取的解决方案,以期构建一个好的智能风控工具体系。主要内容包括:
智能风控体系概览
智能风控体系详细拆解
01 智能风控体系概览
1. 风控服务体系的演进
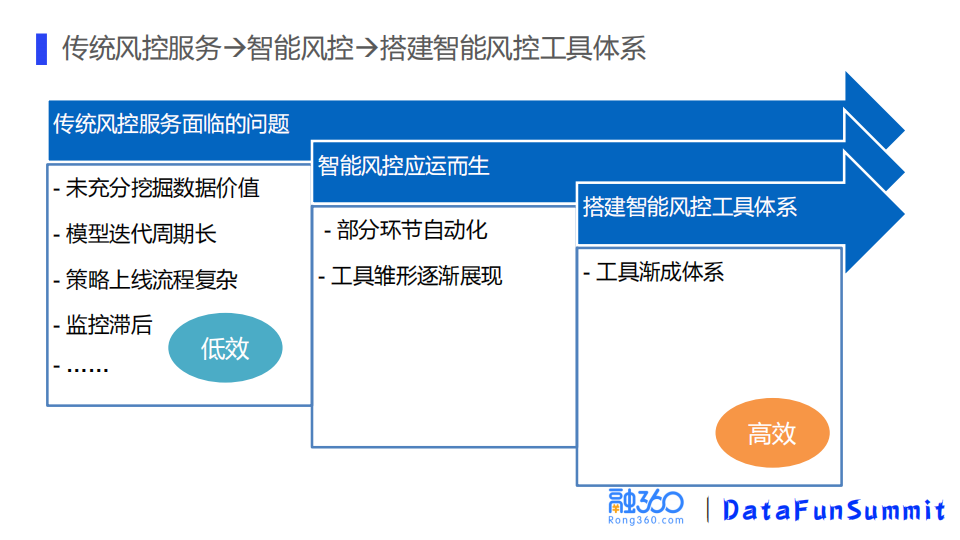
风控服务体系的搭建,我们经历了从纯手工,到一部分环节自动化,再到逐渐形成工具体系的一个过程。
最初在做风控的特征和模型的时候,是人工逐个根据业务逻辑来解析特征,特征上线的过程就是研发工程师根据需求里边的sql进行特征翻译上线。模型建模就是人工手动调参建模,然后将模型文件和预处理的逻辑提供给研发工程师进行上线。这样会带来下面两个问题:
特征线上线下的一致性难以保证
模型上线的时间相对较长
后来我们将一些常用的操作进行抽取,将其形成一些自动化的工具或函数,比如批量特征衍生的工具和模型建模的一些通用函数,逐渐形成工具雏形。再经过后续迭代优化,以及决策引擎的上线,逐渐构成了智能风控的工具体系。
2. 智能风控体系的构成
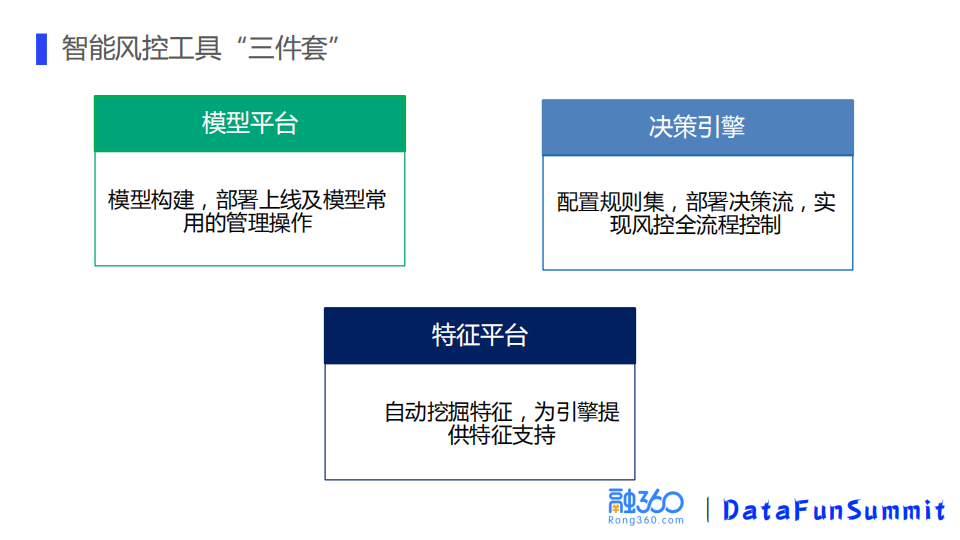
① “三件套”
智能风控工具核心三件套,包括模型平台,决策引擎和特征平台。
② 两个支撑
除核心三件套之外,还有两个支撑,分别是数据平台和监控平台。
数据平台可以实现数据接入的部分自动化操作,为特征平台提供数据支持;
监控平台可以做日常监控各个业务指标,包括日常监控和预警。

图中示意了部分交互过程:
数据平台给特征平台提供源数据的支持
特征平台利用这些源数据进行特征挖掘,为模型平台和决策引擎提供特征支持
模型平台构建的决策模型输出模型分给决策引擎
在决策引擎里实现风控全流程的控制
监控平台和其他几个平台都有交互,或者是使用其他平台存储的一些数据来生成监控报表,或者是调用一些其他平台的一些功能来实现监控功能
以上五部分内容——三件套加两个支撑,一起构成了我们智能风控的一套完整的工具体系。接下来从下向上,依次详细介绍每个工具。
02 智能风控体系详细拆解
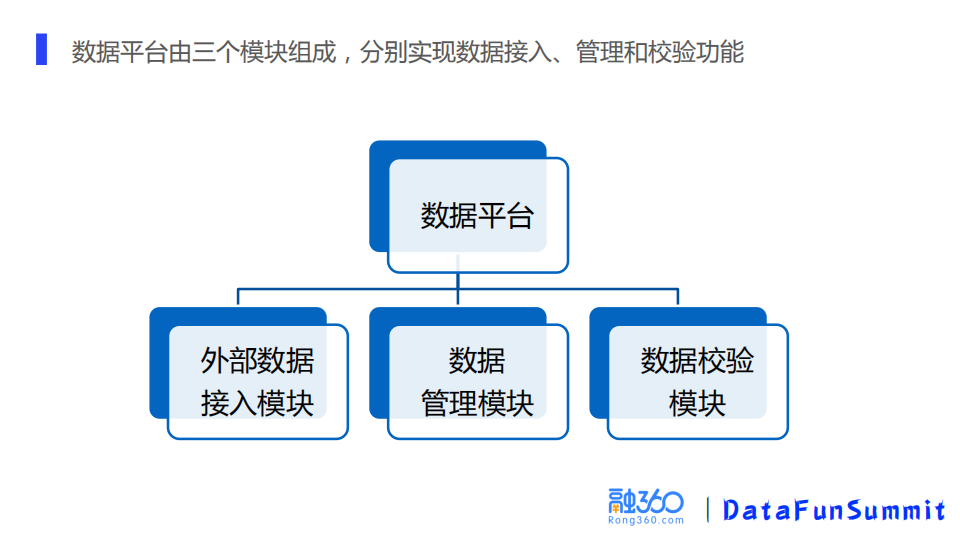
1. 数据平台
数据平台是由三个模块构成的,分别实现外部数据的接入、数据的管理以及数据的校验。
① 外部数据接入模块
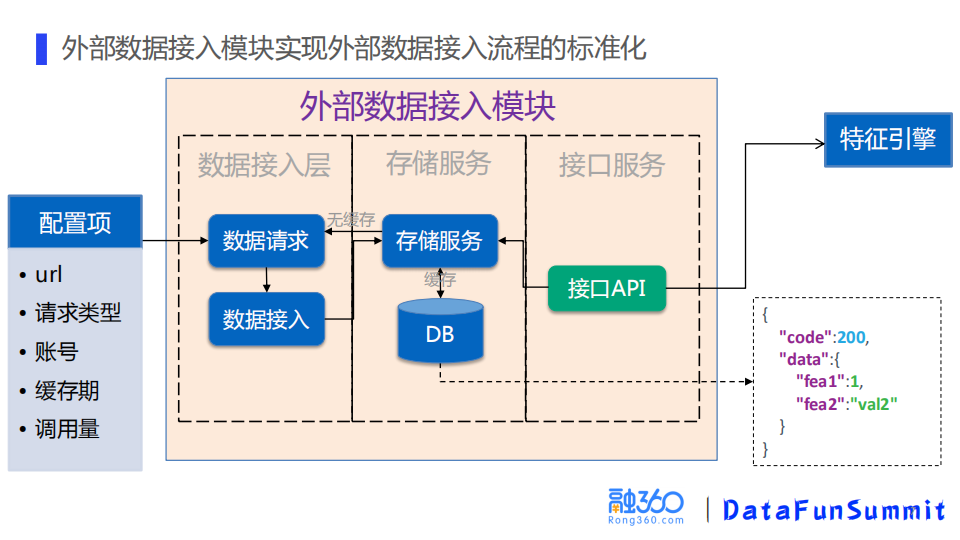
外部数据接入模块主要是实现外部数据接入标准化的工作。一些通用的参数(如URL、请求类型、账号、缓存期和调用量等)通过配置项的方式传到外部数据接入模块,然后存储服务实现源数据存储到数据库中的功能,存储的源数据可以用于建模特征开发、问题定位、以及与数据源公司对账等。该模块还会提供一个数据接口服务供特征引擎调用。具体取数逻辑是先去查缓存,有缓存则直接取数据返回;否则由数据接入层去实时请求数据存储到数据库,并且提供给决策引擎使用。
② 数据管理模块

数据管理模块是为了保证数据的规范存储和顺畅流转,包含线上和离线两部分。线上部分会对业务数据做初步的清洗和转换后存储到数据库,并提供在线接口服务。任务调度将线上数据同步到离线,供离线特征开发和回溯使用。
部署时如果离线批量回溯与线上业务系统共用同一套服务,可能会对线上的业务系统产生影响,所以理想的是设计在线和离线两套接口服务。但是实际操作中为了平衡成本,有时候也会共用一套,对离线回溯做限速,并尽量与线上错峰使用。
③ 数据校验模块
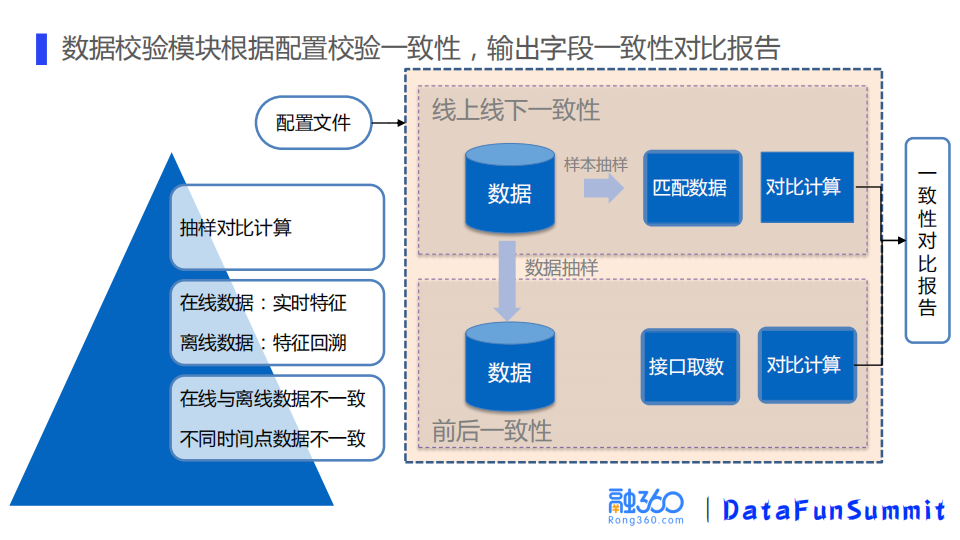
数据校验模块主要用来校验数据的一致性。为什么要保证数据的在线和离线以及在不同时点的一致性呢?我们在实际中发现特征不一致,大多数情况下是数据不一致造成的,线下建模和线上实际使用的特征不一致会直接导致模型效果的衰减。
如何校验数据一致性呢?主要是抽样对比计算来做的。根据配置文件去抽样数据、解析,对比线上落表的数据,输出一致性对比的结果。前后一致性的校验也是类似的,主要区别点在另一份数据是通过接口来取得的,从而判断接口两次返回的数据是否一致。
2. 特征平台
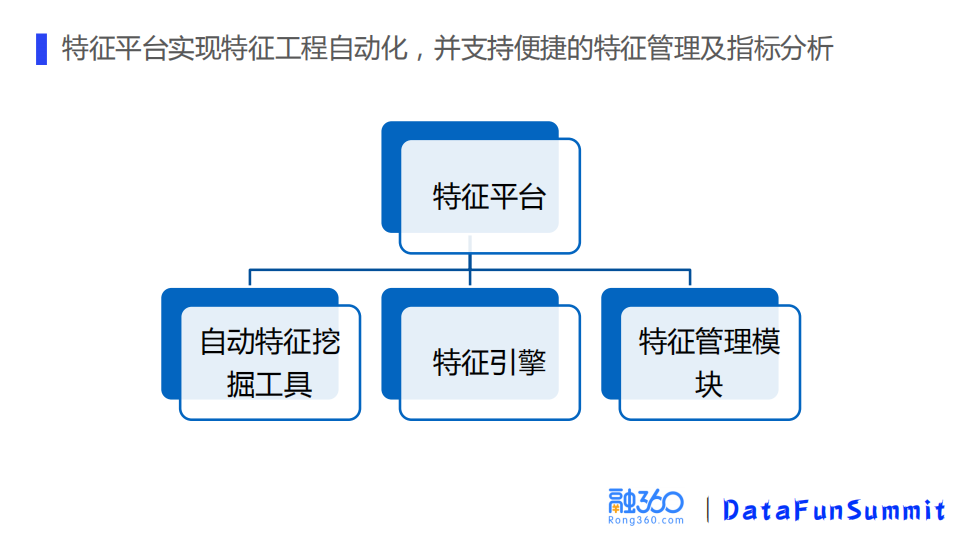
特征平台主要是实现了特征工程自动化,支持便捷的特征管理和指标分析。由三个模块构成:自动特征挖掘工具,特征引擎和特征管理模块。
① 自动特征挖掘工具

一套完整的自动特征挖掘工具可以方便的实现从源数据到特征的转化。这套工具的输入是原始数据加上参数配置文件(excel文件),基于这两个文件进行数据标准化、自动切分组合、汇总计算来提取特征,再进行效果评估,最终输出特征模块。

自动特征挖掘工具针对结构化数据,使用RFM思路构建特征。先确定时间窗口(比如近180天),然后用分类变量进行筛选(比如上午),再对数值变量(申请金额)做聚合和统计(比如取最大值),这样组合起来就能得到一个特征:近180天_上午_最大申请金额。
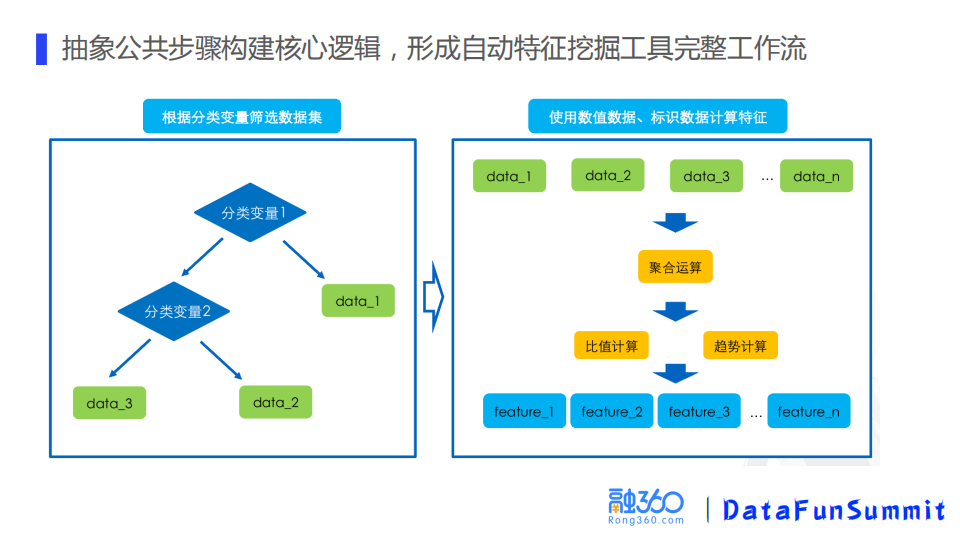
具体到工具层面就是根据这个思路,把公共步骤抽取出来,构建核心逻辑。首先根据分类变量对数据集做筛选,但筛选的过细,可能导致特征过于稀疏,所以分类变量个数的设置需要考虑特征粒度和整体稀疏度的平衡。然后基于数值变量汇总计算特征包括聚合、比值和趋势性变量的计算。把功能步骤抽取出来之后,就形成了自动特征挖掘工具的一个完整工作流。
最终使用时将分类变量、数值变量,组合方式的描述作为参数配置文件,输入自动特征挖掘的工具,自动生成一组特征。
② 特征引擎
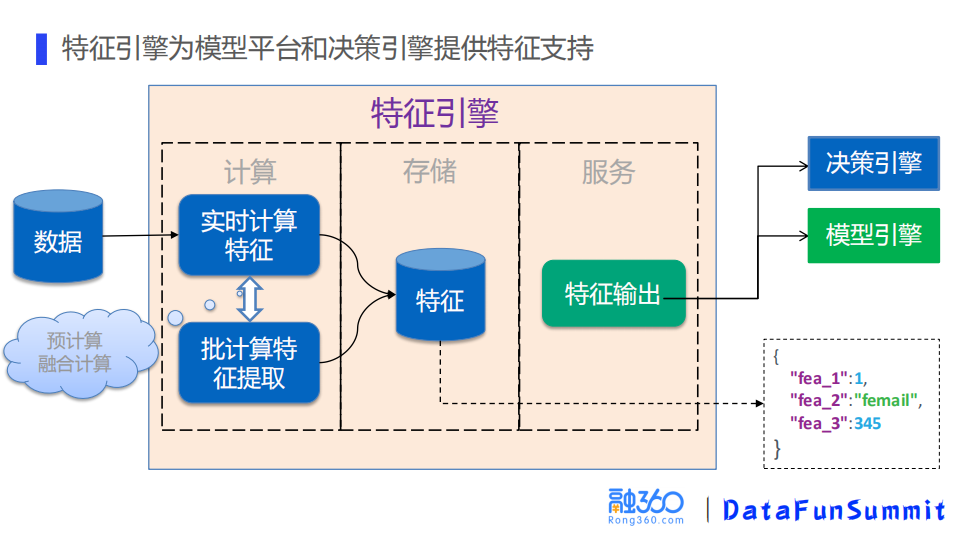
特征引擎是为模型引擎和决策引擎提供特征支持,其功能分为计算、存储、服务三块。最复杂的是特征计算,原始数据来自业务系统,实时特征对计算的资源要求较高,对实时计算有困难的数据采取提前离线跑批,实际授信时请求预计算好的特征。
计算完成之后,会把特征存储下来并定期同步到离线,用于建模及特征一致性的校验使用。最后,服务模块将特征输出给模型引擎和决策引擎使用。
③ 特征管理模块
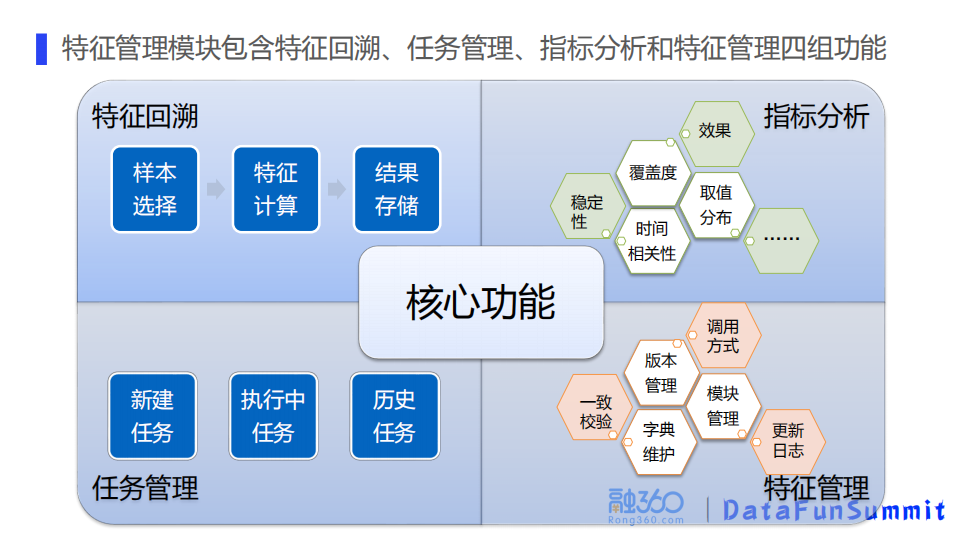
特征管理模块包含特征回溯,回溯任务的管理,指标分析和特征模块本身的管理。
为了方便特征复用,我们进行了回溯任务的管理,包括新建任务、执行中的任务、历史已经回溯任务列表等。指标分析平台是为了方便查看回溯特征的效果。选择结果表之后,指标分析平台可以展示特征的覆盖度、取值分布、效果、时间相关性,以及它在时间维度上的稳定性等。特征管理模块,主要是做特征版本的管理,以及模块的更新和字典维护。
特征管理模块使用示例:
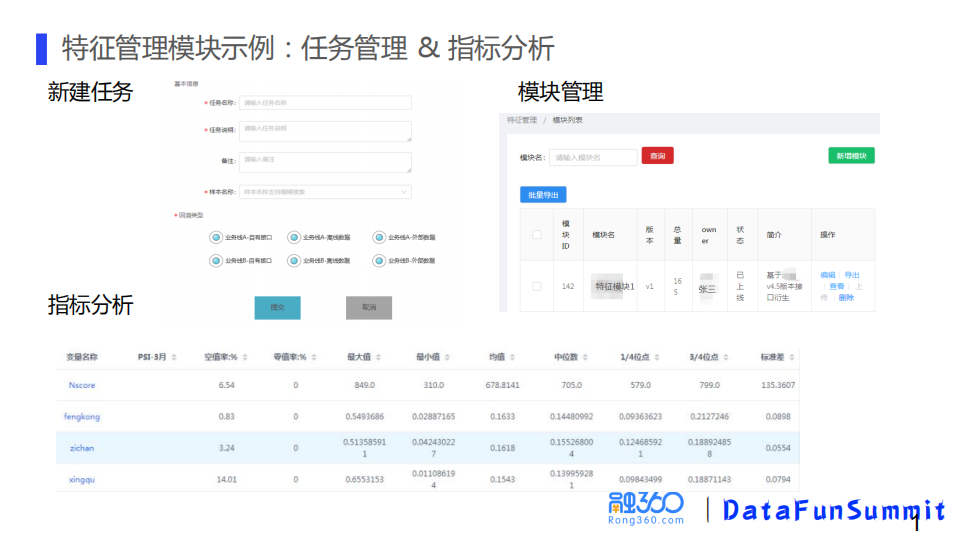
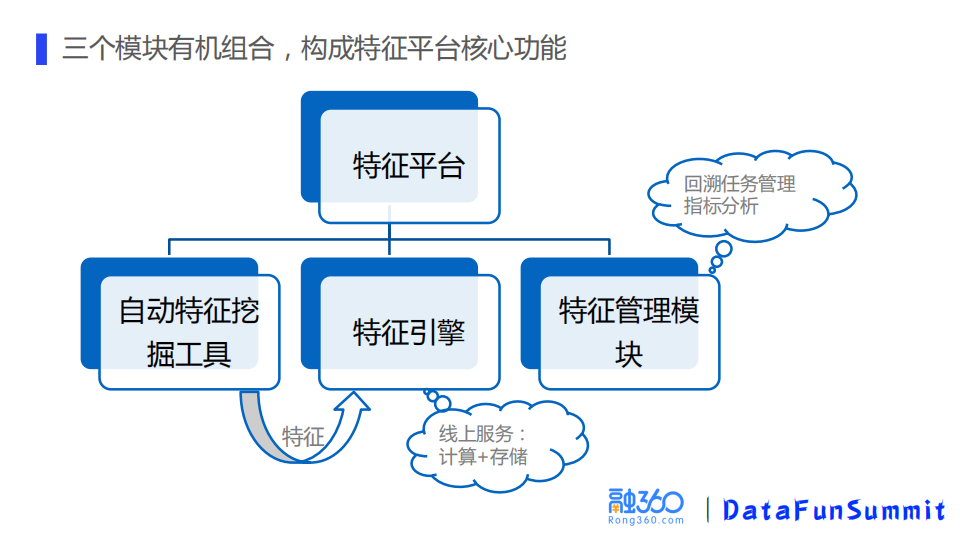
用自动特征挖掘工具挖掘特征,挖掘出的特征部署到决策引擎使用,决策引擎会提供线上的服务,包括计算和存储,特征管理模块负责回溯任务的管理和指标的分析,这样这三个模块结合起来就构成了特征平台的核心功能。
3. 模型平台
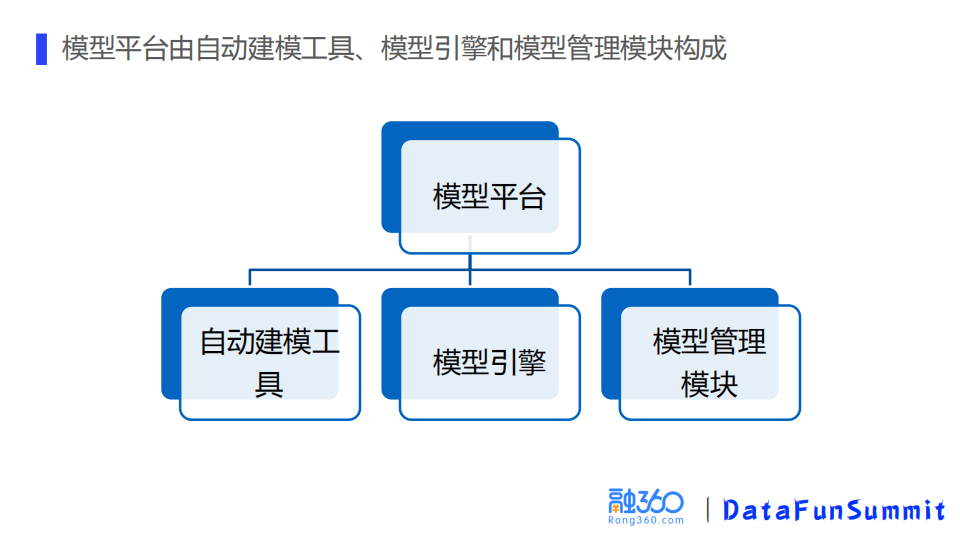
模型平台由自动建模工具、模型引擎和模型管理模块这三个模块组成。
① 自动建模工具

通用的建模流程,首先是样本的设计,取值分析,EDA,特征选择,模型构建,之后会做效果评估,并把所有评估结果整理到报告中。我们在建模的过程中将EDA、特征选择、模型构建等常用操作提取出通用函数,生成标准化报告,然后将取数及建模过程封装,从而形成了自动建模平台的雏形。
首先从Hive获取数据及样本,然后去特征集市取特征,样本和特征拼接形成数据宽表之后调用标准建模模块,走建模的流程(EDA、特征选择,建模以及效果评估),之后根据我们设计的指标,挑选最优模型部署上线,同时输出模型文件和对比报告。
自动建模适用的场景,比如有新样本需要快速迭代,已确定新样本对模型的增益。自动建模工具主要目的是快速迭代一个baseline出来,具体最终的模型怎么做、样本的设计、标签的选取,这些是需要结合业务做一些判断的,是自动工具无法直接完成的。
② 模型引擎

模型引擎主要完成模型打分、存储以及对外输出的工作。模型打分会区分决策模型和陪跑模型,所有模型打分及模型依赖的特征都会存到模型跑批结果表里,并同步到离线。
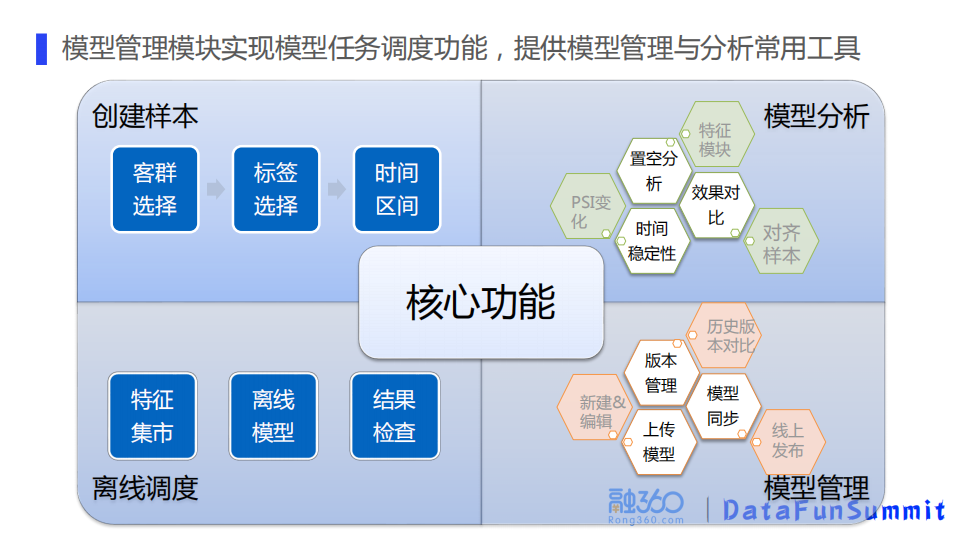
模型管理模块实现了模型的任务调度以及模型的一些管理和分析功能,主要包含创建样本、离线调度、模型分析和模型管理。
创建样本模块可以支持方便地选择建模样本,比如可以勾选标准样本,或自定义sql来创建样本。
离线调度模块实现离线特征的批量调度功能。一般是将昨天过授信的用户的所有特征模块的特征存储下来,按天分区存储,形成离线特征集市方便后续建模使用。跑批和实际建模使用之间预留一定时间差,并添加结果检查功能,方便特征跑批失败时及时修补,保证自动建模任务稳定运行。除此之外离线调度模块还支持离线模型任务的调度,比如营销模型、部分贷中模型,是离线批量跑批的形式。
模型分析的功能是基于抽取平时建模中的常用操作,组合而成的工具集。比如模型置空分析、效果对比、时间维度上的稳定性等。
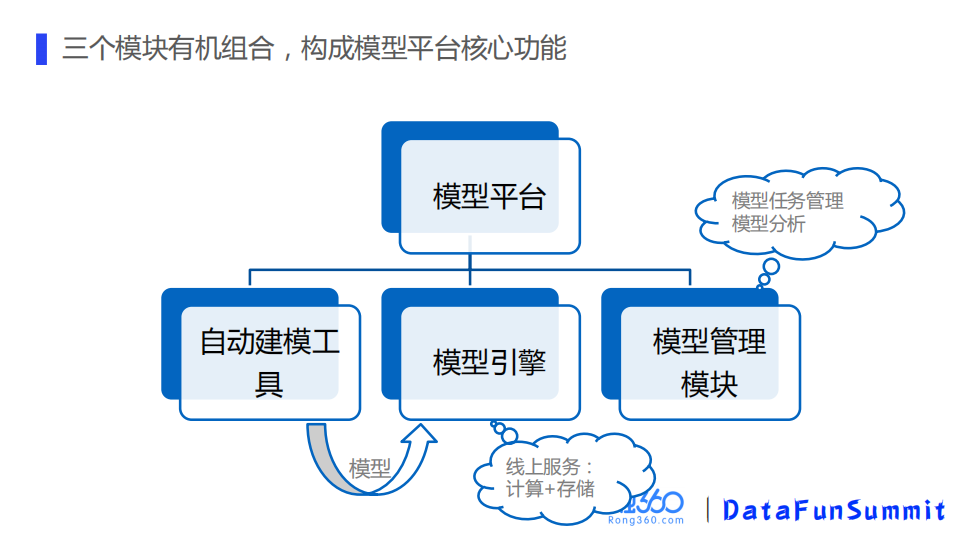
模型平台的三大模块之间的交互关系,自动建模工具用来建模,模型最终部署到模型引擎里提供线上服务,同时模型管理模块提供在线和离线需要的一些模型管理常用的操作和指标分析功能。
4. 决策引擎
决策引擎极大地方便了我们配规则以及决策的上线。决策引擎里边会有规则集配置、决策流配置和上线审批管理这三大模块。


决策引擎的工作流程:
在规则集配置里,可以新建规则集,每个规则集里可以添加多个规则,还可以做一些额度和输出矩阵的配置。
规则集配置完后,配置的规则就可以在决策流中去使用。在决策流里边有不同的节点,支持Atest或者是条件分流。部署规则集,绘制流程线,形成决策流,绘制完成之后保存。修策流修改后,可以做版本对比,确认之后会发起上线审批的操作。
上线审批通过之后,会自动上线。
决策引擎三个模块之间的交互关系如下:
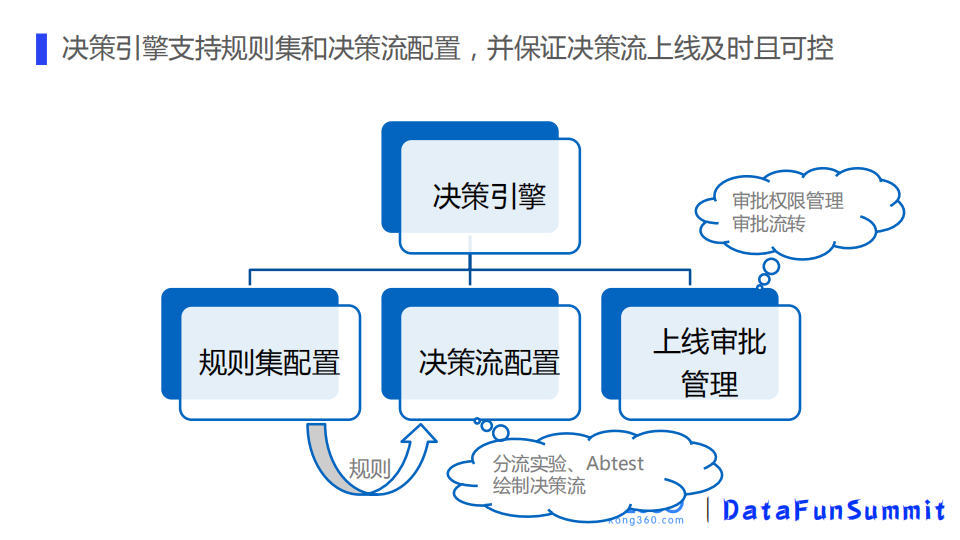

上图是我们决策引擎配置的一个简单界面,会有不同的节点,开始和结束节点,条件节点,以及一些网关和决策节点,可以通过连接线方便地绘制决策流。
5. 监控平台
监控平台,包含日常监控和预警,主要是为了提供稳定的风控服务。包括业务监控、模型监控、特征监控、数据字段监控,以及数据服务监控。


这里列了一些主要的监控报表以及监控预警的方式,除此之外,实际业务中还有分级的监控预警。下图是一个监控报表应用示例。

我们会监控特征PSI的变化,模型打分的异常等。还有一个分级预警,如果遇到比较严重的模型打分偏移的情况,会做电话通知,甚至熔断授信。以模型分为例,模型上线之前会对模型用到的每个外部数据做重要性的判断。假如数据缺失之后,模型分会偏低,但是对模型排序影响不大,那么我们可能会发一个预警提示,由策略同学评估是否需要调整风控策略,以维持通过率的稳定。但是假如某个数据源对模型很重要,缺失之后模型打分大幅偏高,那么这个数据源缺失对模型的影响就会比较严重,可能会导致风险升高。在这种情况下,我们可能会去设置、做授信的熔断,并且及时发出电话预警,去做数据源的跟进或策略的调整。
03 总结
以上就是几个模块的介绍。我们再来看一下整体的智能风控工具体系的构成。
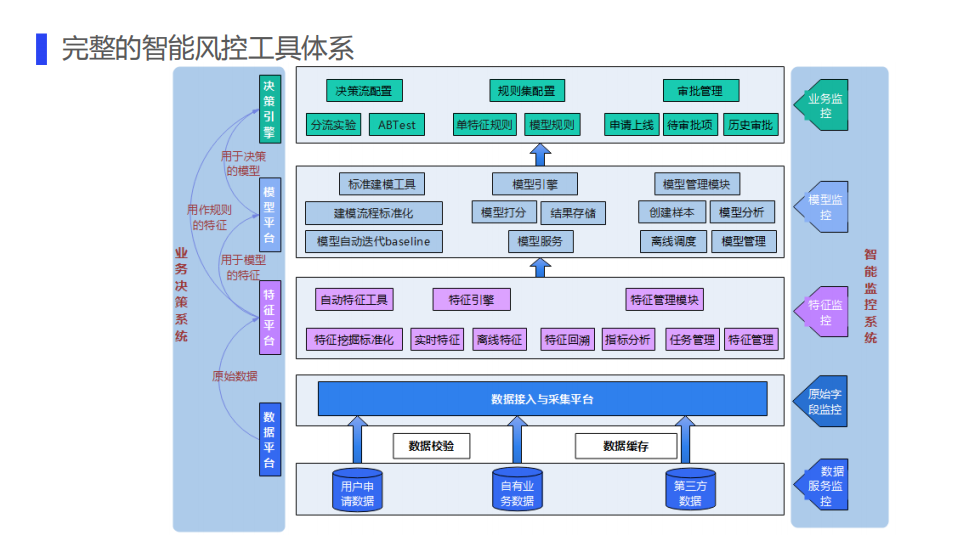
左边是业务决策系统,中间是决策系统部分模块的展示,右边是监控系统。
自底向上,决策系统的数据平台给特征平台提供原始数据支持,特征平台给模型平台和决策引擎提供运作规则和运作模型用到的特征支持,模型平台把决策模型分输出给决策引擎,在引擎里去配置模型的网关和决策节点。决策引擎里边去配置决策流、规则集,以及做审批管理以实现整个风控流程的全流程控制。针对每个模块都有相应的监控数据服务,原始字段、特征模型和业务。这些模块就构成了一个完整的智能风控的工具体系。
04 精彩问答
Q:请问决策引擎是如何保证数据一致性和准确性的,是否有做一些比如温度发布分流实验和流量回放等功能?
A:这个是在特征上线之前之后都会有一些相应的校验测试,上线之前可能首先是case级别的校验,case级别校验通过之后会有一些流量的回放,发布的时候也是逐渐分流发布的,因为我们在决策引擎里可以配置分流。
Q:自动特征挖掘工具是用来自动挖掘新特征的吗?
A:自动挖掘工具根据我们的原始数据,去做一些批量特征的衍生,出来的都是新特征。
今天的分享就到这里,谢谢大家。
编辑:王菁
校对:龚力
















 2098
2098











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









