







来源:AI数据研习社
本文约2500字,建议阅读7分钟本文介绍了节点分类。本篇我们来说一下节点分类,对节点进行分类,例如判断这个节点是否欺诈。一般的结构型数据分类预测任务,我们通过数据特征和标签作为训练集训练模型。而知识图谱网络中的节点特征是网状结构不是向量结构,我们需要找到从网络中抽取特征的方法,即通过特殊的表达手段,将网络中的节点空间关系抽象为一个向量。
1 朴素节点分类
朴素节点分类的思想非常简单,只需根据节点与其他节点是否相连,进行one-hot编码后,排列成列向量,和标签一起代入分类器进行训练。
假设网络结构如图1所示,节点的向量可以表示为:
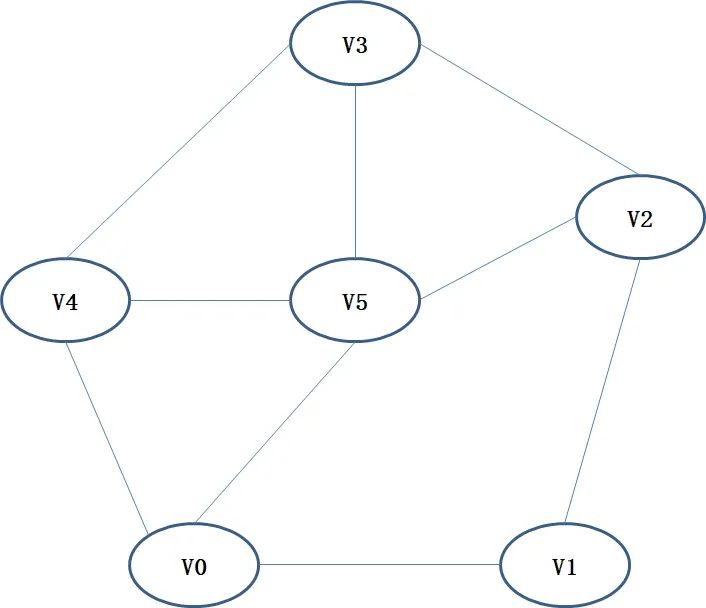
因为 与、、相连,所以在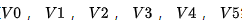
组成的向量中,、、位置的向量元素值取1,其余取值为0。于是得到常规的结构化数据,其中每一个元素代表当前节点的一个特征。
【例】朴素节点分类。首先,将网络结构转化为一个邻接矩阵(Adjacency Matrix),然后使用线性核SVM模型进行训练。
首先,看一下数据在网络中的结构
import networkx as nx
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
# 数据网络结构
G = nx.karate_club_graph()
plt.figure(figsize=(15,10))
nx.draw(
G,
with_labels=True,
edge_color='grey',
node_color='pink',
node_size=500,
font_size=40,
pos=nx.spring_layout(G,k=0.2)
)
plt.show()网络结构图如下图2所示:
# 给定真实标签groundTruth = [0,0,0,0,0,0,0,0,1,1,0,0,0,0,1,1,0,0,1,0,1,0,1,1,1,1,1,1,0,0,0,0,1,1]
# 定义邻接矩阵,将网络节点转换成n X n 的方阵
def graphmatrix(G):
n = G.number_of_nodes()
temp = np.zeros([n,n])
for edge in G.edges():
temp[int(edge[0])]
[int(edge[1])] = 1
temp[int(edge[1])][int(edge[0])] = 1
return temp
edgeMat = graphmatrix(G)
x_train,x_test,y_train,y_test = train_test_split(edgeMat,groundTruth,test_size=0.6,random_state=0)
# 使用线性核SVM分类器进行训练
clf = SVC(kernel="linear")
clf.fit(x_train,y_train)
predicted = clf.predict(x_test)
print(predicted)
score =clf.score(x_test,y_test)
print(score)输出结果是:
[0 1 1 0 0 1 1 0 0 1 1 1 1 1 0 1 0 1 1 1 0]
0.8095238095238095
2 邻节点加权投票
在知识图谱中,通常认为,用户的信息会由边进行传播并不断衰减。而在朴素节点分类中,并没有考虑到节点间的相互作用。一般来说,相连的用户可能具有相同的标签,比如一个用户被打上欺诈标签,那么他的一度联系人会转变成欺诈用户的概率会大大提高,这种情况下,可以使用一种叫共生节点分类的半监督学习方法对节点进行分类。
邻节点加权投票(Weighted-Vote Relational Neighbor,WVRN)是一种典型的共生节点分类方法,该方法不需要训练过程, 每一个无标签节点的标签都由其邻居进行加权投票得到:
其中,是节点的标签。当节点的邻居节点标签确认之后,节点的标签也随之确定。权重体现在节点的邻居节点标签的概率上。
【例】使用WVRN算法对节点进行分类
将样本的标签值初始化为0.5,即每个样本属于正负样本的概率各有50%。使用WVRN算法对节点进行迭代,得到最终结果。
import networkx as nx
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 二值化,默认0.5作为阈值,可以根据业务标签分布调整
def binary(nodelist,threshold=0.5):
for i in range(len(nodelist)):
if (nodelist[i]>threshold):nodelist[i]=1.0
else
:
nodelist[i]=0
return nodelist
G = nx.karate_club_graph()
plt.figure(figsize=(15,10))
nx.draw(
G,
with_labels=True,
edge_color='grey',
node_color='pink',
node_size=500,
font_size=40,
pos=nx.spring_layout(G,k=0.2)
)
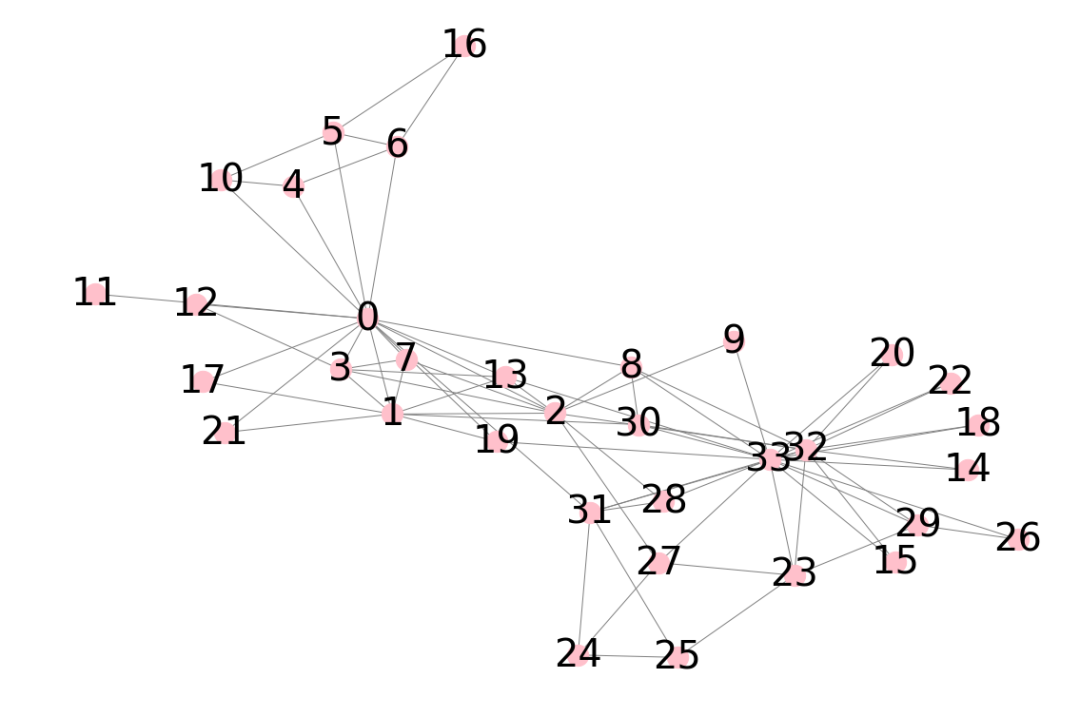
plt.show()网络结构图如下图3所示:
groundTruth = [0,0,0,0,0,0,0,0,1,1,0,0,0,0,1,1,0,0,1,0,1,0,1,1,1,1,1,1,0,0,0,0,1,1] max_iter = 10 #迭代次数
nodes = list(G.nodes())
nodes_list = {nodes[i]: i for i in range(0,len(nodes))}
vote = np.zeros(len(nodes))
# x_train,x_test分割的有标签和无标签的节点,里面的数值代表节点号
x_train, x_test, y_train, y_test = train_test_split(nodes,
groundTruth, test_size=0.7, random_state=1)
# vote[x_train]赋值真实标签,vote[x_test]初始化成0.5
vote[x_train] = y_train
vote[x_test] = 0.5 #初始化概率为0.5
for i in range(max_iter):
# 只用前一次迭代的值
last = np.copy(vote)
for u in G.nodes():
if (u in x_train):
continue
temp =0.0
for item in G.neighbors(u):
# 对所有邻居求和
temp = temp+last[nodes_list[item]]
vote[nodes_list[u]] = temp/len(list(G.neighbors(u)))
# 二值化得到分类标签
temp = binary(vote)
pred = temp[x_test]
# 计算准确率
print(accuracy_score(y_test, pred))运行结果0.7916666666666666,即当前模型预测准确率为0.79。
3 一致性标签传播
根据邻居节点概率加权投票的方式,虽然考虑了节点信息的流转,但是在每一次更新的时候都没有将当前自身的信息考虑尽量。简单来说,一个节点在经历一次更新时,相比自身原本的标签不应该有太大的改变。
如果想把每个节点自身的信息考虑进去,可以使用一致性标签传播(CLPM),一致性标签传播也是一种半监督的学习方法,可以根据网络中部分有标签样本的标记,迭代得到其余无标签样本的标签。
【例】使用CLPM算法对节点进行分类
import networkx as nx
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn import preprocessing
from scipy import sparse
G = nx.karate_club_graph()
groundTruth = [0,0,0,0,0,0,0,0,1,1,0,0,0,0,1,1,0,0,1,0,1,0,1,1,1,1,1,1,0,0,0,0,1,1]
def graphmatrix(G):
#节点抽象成边
n = G.number_of_nodes()
temp = np.zeros([n,n])
for edge in G.edges():
temp[int(edge[0])][int(edge[1])] = 1
temp[int(edge[1])][int(edge[0])] = 1
return temp
def propagation_matrix(G):
#矩阵标准化
degrees = G.sum(axis=0)
degrees[degrees==0] += 1 # 避免除以0
D2 = np.identity(G.shape[0])
for i in range(G.shape[0]):
D2[i,i] = np.sqrt(1.0/degrees[i])
S = D2.dot(G).dot(D2)
return S
#定义取最大值的函数
def vec2label(Y):
return np.argmax(Y,axis=1)
edgematrix = graphmatrix(G)
S = propagation_matrix(edgematrix)
Ap = 0.8
cn = 2
max_iter = 10
#定义迭代函数
F = np.zeros([G.number_of_nodes(),2])
X_train, X_test, y_train, y_test = train_test_split(list(G.nodes()),
groundTruth, test_size=0.7, random_state=1)
for (node, label) in zip(X_train, y_train):
F[node][label] = 1
Y = F.copy()
for i in range(max_iter):
F_old = np.copy(F)
F = Ap*np.dot(S, F_old) + (1-Ap)*Y
temp = vec2label(F)
pred = temp[X_test]
print(accuracy_score(y_test, pred))运行结果0.75,即当前模型预测准确率为0.75。
编辑:王菁















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









