







目录
1.引言
图神经网络根据学习到不同的特征,可以进行不同的下游任务,如下表所示:
| 图神经网络输出的特征 | 下游任务 | 应用 |
| 节点特征 | 节点分类、节点聚类 | 词向量学习、商品/好友推荐、实体识别...... |
| 连边特征 | 链路预测 | 路况预测、商品推荐....... |
| 图级别特征 | 图分类、图聚类 | 文本分类、新药物的发现、化合物筛选、蛋白质相互作用点检测...... |
本文就将介绍如何利用图神经网络学习节点特征并进行节点分类任务,看完后应该可以回答以下几个问题:
- 节点分类任务是什么?
- 节点分类的基本步骤?
- 有什么方法可以学习图中的节点特征?
- 如何利用图神经网络学习图中的节点特征?
- 如何利用图神经网络学习到的节点特征进行节点分类任务?
2.节点分类任务&步骤
节点分类定义
根据节点的属性(可以是类别型、也可以是数值型)、边的信息、边的属性(如果有的话)、已知的节点预测标签,对未知标签的节点做类别预测。
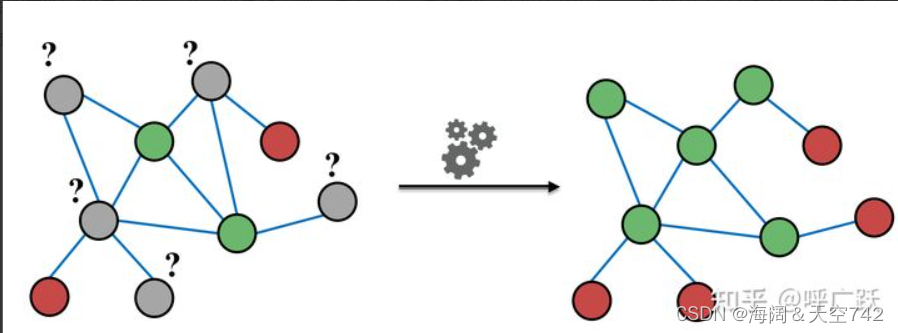
步骤
- 利用某种方法学习节点的特征;
- 基于节点特征利用分类方法分类。
3. 图中节点特征的学习方法
图中节点特征的学习时图嵌入任务的一个部分。
图嵌入(Graph Embedding/Network Embedding,GE),属于表示学习的范畴,也可以叫做网络嵌入,图表示学习,网络表示学习等等。通常有两个层次的含义:
- 将图中的节点表示成低维、实值、稠密的向量形式,使得得到的向量形式可以在向量空间中具有表示以及推理的能力,这样的向量可以用于下游的具体任务中。例如用户社交网络得到节点表示就是每个用户的表示向量,再用于节点分类等;
- 将整个图表示成低维、实值、稠密的向量形式,用来对整个图结构进行分类;
图嵌入的方式主要有三种:
- 矩阵分解:基于矩阵分解的方法是将节点间的关系用矩阵的形式加以表达,然后分解该矩阵以得到嵌入向量。通常用于表示节点关系的矩阵包括邻接矩阵,拉普拉斯矩阵,节点转移概率矩阵,节点属性矩阵等。根据矩阵性质的不同适用于不同的分解策略。
- DeepWalk:DeepWalk 是基于 word2vec 词向量提出来的。word2vec 在训练词向量时,将语料作为输入数据,而图嵌入输入的是整张图,两者看似没有任何关联。但是 DeepWalk 的作者发现,预料中词语出现的次数与在图上随机游走节点被访问到底的次数都服从幂律分布。因此 DeepWalk 把节点当做单词,把随机游走得到的节点序列当做句子,然后将其直接作为 word2vec 的输入可以节点的嵌入表示,同时利用节点的嵌入表示作为下游任务的初始化参数可以很好的优化下游任务的效果,也催生了很多相关的工作;
- Graph Neural Network:图结合deep learning方法搭建的网络统称为图神经网络GNN,也就是下一小节的主要内容,因此图神经网络GNN可以应用于图嵌入来得到图或图节点的向量表示;
此外,在利用数据进行图神经网络时,其中一个输入参数为节点特征,也就是节点的初始特征。如果节点初始特征未知的话,我们可以依靠以上的知识推测,至少有两种方案获取节点初始特征:
-
基于矩阵分解:分解节点邻接矩阵获取节点初始特征;
-
基于DeepWalk+word2vec:利用图进行deep walk,再输入word2vec生成节点初始特征;
此外,深度学习新星 | 图卷积神经网络(GCN)有多强大?
 https://www.sohu.com/a/234894712_741733 中提到,还可以:
https://www.sohu.com/a/234894712_741733 中提到,还可以: -
将节点数量大小的单位矩阵作为节点的初始特征。
4.利用图神经网络进行节点分类任务
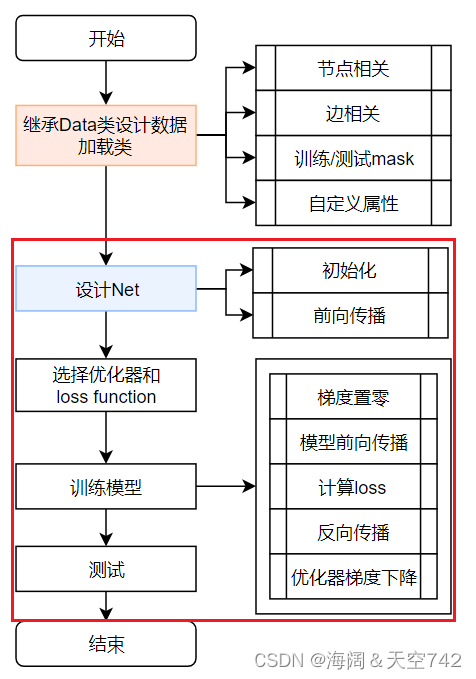
数据及介绍
PyG内置了大量常用的基准数据集,以PyG内置的Planetoid数据集为例。Planetoid数据集类的官方文档为torch_geometric.datasets.Planetoid。
我们在这里使用的是其中的Cora 数据,数据加载代码如下:
from torch_geometric.datasets import Planetoid
dataset = Planetoid(root='dataset/Cora', name='Cora')#包括数据集的下载,若root路径存在数据集则直接加载数据集
data = dataset[0] #该数据集只有一个图len(dataset):1
# Data(edge_index=[2, 10556], test_mask=[2708],
# train_mask=[2708], val_mask=[2708], x=[2708, 1433], y=[2708])该数据包含 2708 篇科学出版物(节点),总共分为7类。引文网络由 5429 个引用链接(边)组成。数据集中的每个出版物都由一个 0/1 值的词向量描述,指示字典中相应词的缺失/存在。该词典由 1433 个独特的词组成,相对于一个one hot编码的词袋向量,此向量为节点的初始特征向量(data.x,维度为[2708,1433])。训练数据为120个带类别标签的节点,测试数据为1000个未标记的节点。
实验
前面提到,节点分类任务是根据已知类别标签的节点和节点特征的映射,对未知类别标签节点进行类别标签标注。事实上仅仅利用Cora数据中节点的初始特征向量信息,将它们扔进分类器就可以进行节点分类了。
设计了3个模型(多层感知机、基于GCNConv的图卷积神经网络GCN、基于TransformerConv的模型)分别进行对比,其中多层感知机只利用了节点特征,而GCN利用了节点自身属性与周围邻居节点的属性,基于TransformerConv的模型考虑了不同邻居对节点自身属性的不同影响。
设计Net
MLP多层感知机
设计这个MLP为两个线性(Linear)层、一个ReLU非线性层和一个dropout操作。第一个Linear层将1433维的特征向量嵌入(embedding)到低维空间中(hidden_channels=16),经过ReLU层激活,再经过dropout操作,输入第二个Linear层——将低维节点表征嵌入到类别空间中(num_classes=7)。
import torch
from torch.nn import Linear
import torch.nn.functional as F
#设计Net
class MLP(torch.nn.Module):
def __init__(self, hidden_channels):
super(MLP, self).__init__()
torch.manual_seed(12345) #设定随机种子,可省略
self.lin1 = Linear(dataset.num_features, hidden_channels)
self.lin2 = Linear(hidden_channels, dataset.num_classes)
def forward(self, x):
x = self.lin1(x)
x = x.relu()
x = F.dropout(x, p=0.5, training=self.training)
x = self.lin2(x)
return x
model = MLP(hidden_channels=16)
print(model)
#MLP(
# (lin1): Linear(in_features=1433, out_features=16, bias=True)
# (lin2): Linear(in_features=16, out_features=7, bias=True)
#)利用交叉熵损失和Adam优化器来训练这个简单的MLP网络。
#选择优化器
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
#定义损失函数
criterion = torch.nn.CrossEntropyLoss()
#训练函数
def train(model,data,optimizer,criterion):
model.train()
optimizer.zero_grad() # 梯度置零
out = model(data.x) # 模型前向传播
loss = criterion(out[data.train_mask],data.y[data.train_mask]) # 计算loss
loss.backward() # 反向传播
optimizer.step() # 优化器梯度下降
return loss
#训练
for epoch in range(1, 201):
loss = train(model,data,optimizer,criterion)
print(f'Epoch: {epoch:03d}, Loss: {loss:.4f}')1433
7
tensor([3, 4, 4, ..., 3, 3, 3])
tensor([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]])
tensor([[ 0, 0, 0, ..., 2707, 2707, 2707],
[ 633, 1862, 2582, ..., 598, 1473, 2706]])
tensor([ True, True, True, ..., False, False, False])
tensor([False, False, False, ..., False, False, False])
tensor([False, False, False, ..., True, True, True])
Epoch: 001, Loss: 1.9589
Epoch: 002, Loss: 1.9115
Epoch: 003, Loss: 1.8296
Epoch: 004, Loss: 1.7399
Epoch: 005, Loss: 1.6110
Epoch: 006, Loss: 1.5677
Epoch: 007, Loss: 1.4014
Epoch: 008, Loss: 1.3110
Epoch: 009, Loss: 1.2361
Epoch: 010, Loss: 1.1290
Epoch: 011, Loss: 1.0854
Epoch: 012, Loss: 0.9861
Epoch: 013, Loss: 0.8618
Epoch: 014, Loss: 0.8257
Epoch: 015, Loss: 0.6789
Epoch: 016, Loss: 0.7199
Epoch: 017, Loss: 0.6508
Epoch: 018, Loss: 0.6374
Epoch: 019, Loss: 0.5672
Epoch: 020, Loss: 0.4760
Epoch: 021, Loss: 0.4683
Epoch: 022, Loss: 0.4964
Epoch: 023, Loss: 0.4768
Epoch: 024, Loss: 0.4000
Epoch: 025, Loss: 0.4318
Epoch: 026, Loss: 0.4132
Epoch: 027, Loss: 0.3652
Epoch: 028, Loss: 0.3459
Epoch: 029, Loss: 0.3336
Epoch: 030, Loss: 0.2924
Epoch: 031, Loss: 0.3015
Epoch: 032, Loss: 0.3098
Epoch: 033, Loss: 0.2611
Epoch: 034, Loss: 0.3010
Epoch: 035, Loss: 0.3030
Epoch: 036, Loss: 0.2753
Epoch: 037, Loss: 0.2880
Epoch: 038, Loss: 0.2475
Epoch: 039, Loss: 0.3480
Epoch: 040, Loss: 0.2840
Epoch: 041, Loss: 0.2460
Epoch: 042, Loss: 0.2328
Epoch: 043, Loss: 0.2823
Epoch: 044, Loss: 0.2764
Epoch: 045, Loss: 0.2499
Epoch: 046, Loss: 0.2484
Epoch: 047, Loss: 0.1934
Epoch: 048, Loss: 0.2447
Epoch: 049, Loss: 0.2996
Epoch: 050, Loss: 0.2027
Epoch: 051, Loss: 0.2117
Epoch: 052, Loss: 0.2768
Epoch: 053, Loss: 0.2412
Epoch: 054, Loss: 0.2718
Epoch: 055, Loss: 0.2121
Epoch: 056, Loss: 0.2141
Epoch: 057, Loss: 0.1650
Epoch: 058, Loss: 0.1940
Epoch: 059, Loss: 0.2132
Epoch: 060, Loss: 0.2434
Epoch: 061, Loss: 0.2275
Epoch: 062, Loss: 0.2181
Epoch: 063, Loss: 0.2108
Epoch: 064, Loss: 0.2885
Epoch: 065, Loss: 0.2733
Epoch: 066, Loss: 0.2295
Epoch: 067, Loss: 0.2137
Epoch: 068, Loss: 0.1910
Epoch: 069, Loss: 0.1976
Epoch: 070, Loss: 0.1925
Epoch: 071, Loss: 0.1759
Epoch: 072, Loss: 0.1807
Epoch: 073, Loss: 0.2383
Epoch: 074, Loss: 0.2678
Epoch: 075, Loss: 0.1691
Epoch: 076, Loss: 0.2342
Epoch: 077, Loss: 0.2449
Epoch: 078, Loss: 0.2295
Epoch: 079, Loss: 0.1922
Epoch: 080, Loss: 0.1877
Epoch: 081, Loss: 0.1478
Epoch: 082, Loss: 0.3092
Epoch: 083, Loss: 0.2516
Epoch: 084, Loss: 0.2297
Epoch: 085, Loss: 0.2340
Epoch: 086, Loss: 0.2011
Epoch: 087, Loss: 0.1954
Epoch: 088, Loss: 0.1358
Epoch: 089, Loss: 0.1931
Epoch: 090, Loss: 0.1997
Epoch: 091, Loss: 0.2019
Epoch: 092, Loss: 0.2169
Epoch: 093, Loss: 0.2297
Epoch: 094, Loss: 0.2696
Epoch: 095, Loss: 0.2314
Epoch: 096, Loss: 0.1912
Epoch: 097, Loss: 0.1882
Epoch: 098, Loss: 0.1861
Epoch: 099, Loss: 0.2286
Epoch: 100, Loss: 0.1952
Epoch: 101, Loss: 0.1993
Epoch: 102, Loss: 0.1805
Epoch: 103, Loss: 0.1790
Epoch: 104, Loss: 0.2351
Epoch: 105, Loss: 0.2028
Epoch: 106, Loss: 0.2563
Epoch: 107, Loss: 0.1705
Epoch: 108, Loss: 0.2488
Epoch: 109, Loss: 0.2107
Epoch: 110, Loss: 0.2103
Epoch: 111, Loss: 0.1936
Epoch: 112, Loss: 0.2465
Epoch: 113, Loss: 0.2114
Epoch: 114, Loss: 0.1804
Epoch: 115, Loss: 0.1583
Epoch: 116, Loss: 0.2320
Epoch: 117, Loss: 0.1907
Epoch: 118, Loss: 0.1655
Epoch: 119, Loss: 0.1628
Epoch: 120, Loss: 0.2009
Epoch: 121, Loss: 0.2256
Epoch: 122, Loss: 0.1467
Epoch: 123, Loss: 0.1694
Epoch: 124, Loss: 0.2198
Epoch: 125, Loss: 0.2615
Epoch: 126, Loss: 0.1827
Epoch: 127, Loss: 0.2317
Epoch: 128, Loss: 0.2128
Epoch: 129, Loss: 0.1932
Epoch: 130, Loss: 0.1573
Epoch: 131, Loss: 0.2172
Epoch: 132, Loss: 0.2212
Epoch: 133, Loss: 0.1581
Epoch: 134, Loss: 0.2442
Epoch: 135, Loss: 0.1935
Epoch: 136, Loss: 0.1534
Epoch: 137, Loss: 0.2068
Epoch: 138, Loss: 0.2021
Epoch: 139, Loss: 0.1527
Epoch: 140, Loss: 0.2218
Epoch: 141, Loss: 0.2132
Epoch: 142, Loss: 0.2286
Epoch: 143, Loss: 0.1247
Epoch: 144, Loss: 0.1884
Epoch: 145, Loss: 0.3079
Epoch: 146, Loss: 0.1953
Epoch: 147, Loss: 0.1522
Epoch: 148, Loss: 0.1883
Epoch: 149, Loss: 0.2121
Epoch: 150, Loss: 0.2331
Epoch: 151, Loss: 0.2584
Epoch: 152, Loss: 0.2291
Epoch: 153, Loss: 0.1664
Epoch: 154, Loss: 0.1612
Epoch: 155, Loss: 0.1995
Epoch: 156, Loss: 0.1784
Epoch: 157, Loss: 0.2056
Epoch: 158, Loss: 0.1389
Epoch: 159, Loss: 0.2069
Epoch: 160, Loss: 0.1611
Epoch: 161, Loss: 0.1985
Epoch: 162, Loss: 0.2206
Epoch: 163, Loss: 0.2127
Epoch: 164, Loss: 0.1387
Epoch: 165, Loss: 0.1783
Epoch: 166, Loss: 0.2027
Epoch: 167, Loss: 0.2000
Epoch: 168, Loss: 0.1428
Epoch: 169, Loss: 0.1612
Epoch: 170, Loss: 0.1645
Epoch: 171, Loss: 0.1827
Epoch: 172, Loss: 0.1695
Epoch: 173, Loss: 0.1982
Epoch: 174, Loss: 0.1666
Epoch: 175, Loss: 0.2227
Epoch: 176, Loss: 0.1387
Epoch: 177, Loss: 0.2401
Epoch: 178, Loss: 0.1746
Epoch: 179, Loss: 0.1654
Epoch: 180, Loss: 0.2129
Epoch: 181, Loss: 0.1977
Epoch: 182, Loss: 0.1844
Epoch: 183, Loss: 0.1594
Epoch: 184, Loss: 0.1931
Epoch: 185, Loss: 0.1278
Epoch: 186, Loss: 0.1569
Epoch: 187, Loss: 0.2111
Epoch: 188, Loss: 0.2226
Epoch: 189, Loss: 0.1711
Epoch: 190, Loss: 0.2065
Epoch: 191, Loss: 0.1657
Epoch: 192, Loss: 0.1696
Epoch: 193, Loss: 0.1986
Epoch: 194, Loss: 0.1548
Epoch: 195, Loss: 0.1295
Epoch: 196, Loss: 0.1705
Epoch: 197, Loss: 0.1748
Epoch: 198, Loss: 0.1519
Epoch: 199, Loss: 0.2498
Epoch: 200, Loss: 0.2374
Test Accuracy: 0.5660
Process finished with exit code 0训练完模型后,我们可以进行测试,以检验这个简单的MLP模型在未知标签的节点上表现如何。
#测试函数
def test(model,data):
model.eval()
out = model(data.x)
pred = out.argmax(dim=1) # 使用最大概率的类别作为预测结果
test_correct = pred[data.test_mask] == data.y[data.test_mask] # 获取正确标记的节点
test_acc = int(test_correct.sum()) / int(data.test_mask.sum()) # 计算正确率
return test_acc
#精度评价
test_acc = test(model,data)
print(f'Test Accuracy: {test_acc:.4f}')Test Accuracy: 0.5660
Process finished with exit code 0正如我们所看到的,我们的MLP表现相当糟糕,只有大约57%的测试准确性。
如此糟糕的原因是,用于训练此神经网络的有标签节点数量过少,此神经网络被过拟合,它对未见过的节点泛化性很差。
为了实现节点表征分布的可视化,我们先利用TSNE将高维节点表征嵌入到二维平面空间,然后在二维平面空间画出节点。
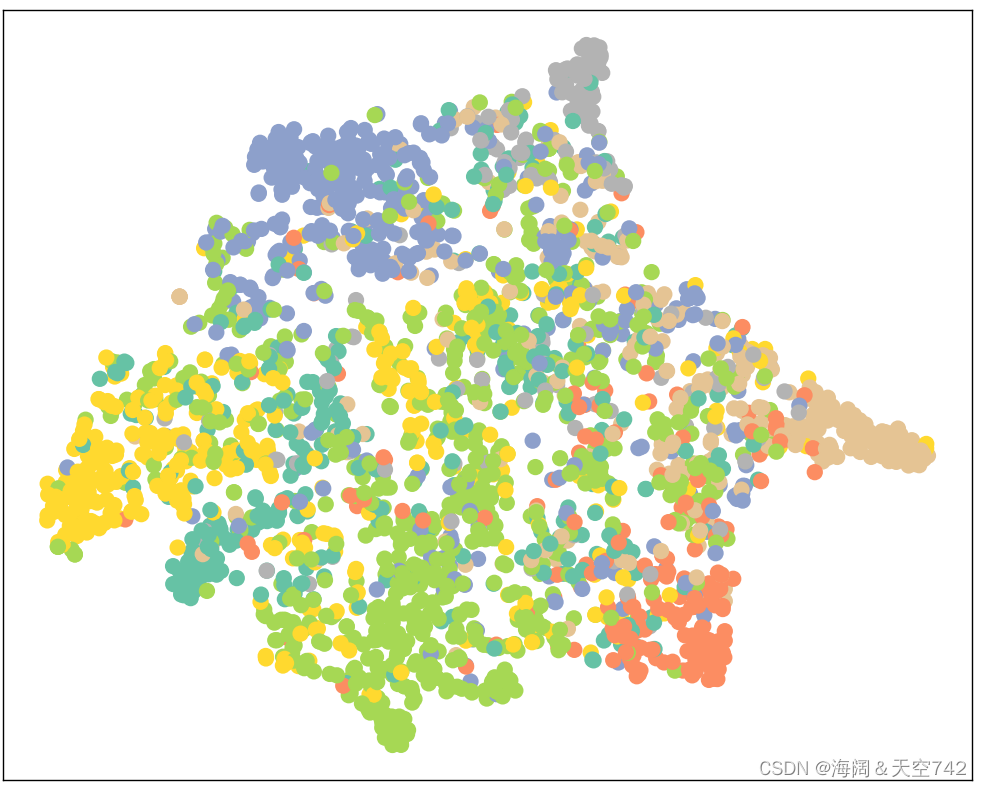
使用决策树分类器
当仅考虑节点自身特征信息,使用决策树进行节点分类时,以下是对应的Python代码示例:
from matplotlib import pyplot as plt
from sklearn.manifold import TSNE
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from CoraCls import dataset
data = dataset[0]#只有一个图
# 假设特征数据保存在 X 中,标签数据保存在 y 中
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(data.x, data.y, test_size=0.2, random_state=42)
# 初始化决策树分类器
clf = DecisionTreeClassifier()
# 在训练集上训练决策树模型
clf.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = clf.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("Decision Tree Accuracy:", accuracy)
# 可视化
def visualize(out, color):
z = TSNE(n_components=2).fit_transform(out.detach().cpu().numpy())
plt.figure(figsize=(10, 10))
plt.xticks([])
plt.yticks([])
plt.scatter(z[:, 0], z[:, 1], s=70, c=color, cmap="Set2")
plt.show()
visualize(y_pred, color=data.y)Decision Tree Accuracy: 0.6439114391143912
当仅考虑节点自身特征信息,使用SVM进行节点分类时,以下是对应的Python代码示例:
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from CoraCls import dataset
data = dataset[0]#只有一个图
# 假设特征数据保存在 X 中,标签数据保存在 y 中
# 假设特征数据保存在 X 中,标签数据保存在 y 中
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(data.x, data.y, test_size=0.2, random_state=42)
# 初始化支持向量机分类器
clf = SVC()
# 在训练集上训练支持向量机模型
clf.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = clf.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("SVM Accuracy:", accuracy)SVM Accuracy: 0.7527675276752768
GCN及其在图节点分类任务中的应用
GCN的定义
根据DataWhale的学习资料,GCN的定义来自论文:https://arxiv.org/abs/1609.02907;数学定义如下: 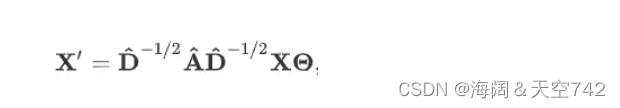
它的节点式表述为:

PyG中GCNConv 模块说明
GCNConv构造函数接口:

通过将torch.nn.Linear layers 替换为PyG的GNN Conv Layers,我们可以轻松地将MLP模型转化为GNN模型。在下方的例子中,我们将MLP例子中的linear层替换为GCNConv层。
import torch
from torch_geometric.datasets import Planetoid
import torch.nn.functional as F
from torch_geometric.nn import GCNConv
#设计Net
class GCN(torch.nn.Module):
#初始化
def __init__(self, hidden_channels):
super(GCN, self).__init__()
torch.manual_seed(12345)
self.conv1 = GCNConv(dataset.num_features, hidden_channels)
self.conv2 = GCNConv(hidden_channels, dataset.num_classes)
#前向传播
def forward(self, x, edge_index):
x = self.conv1(x, edge_index)
x = x.relu()
x = F.dropout(x, p=0.5, training=self.training)
x = self.conv2(x, edge_index)
#注意这里输出的是节点的特征,维度为[节点数,类别数]
return x
#实例化模型
model = GCN(hidden_channels=16)
print(model)
#GCN(
# (conv1): GCNConv(1433, 16)
# (conv2): GCNConv(16, 7)
#)首先可视化未训练的GCN网络的节点表征。
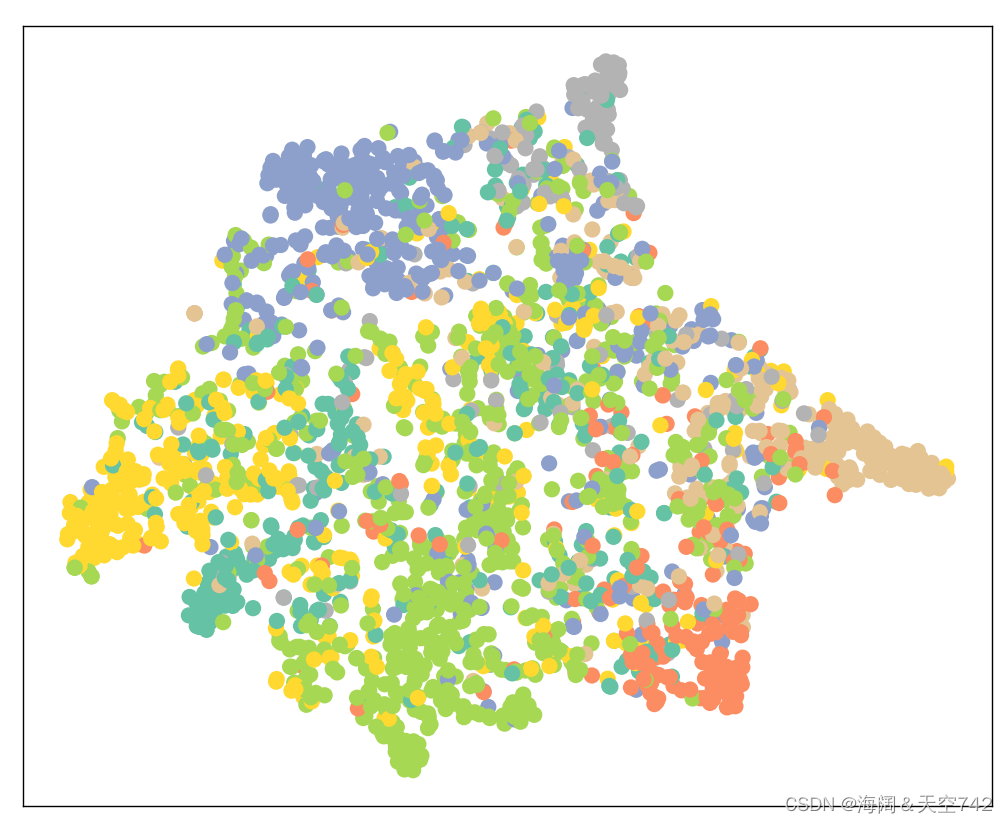
接着训练GCN节点分类器:
#实例化模型
model = GCN(hidden_channels=16)
#print(model)
#GCN(
# (conv1): GCNConv(1433, 16)
# (conv2): GCNConv(16, 7)
#)
#选择优化器
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
#定义损失函数
criterion = torch.nn.CrossEntropyLoss()
#训练函数
def train(model,data,optimizer,criterion):
model.train()
optimizer.zero_grad() # 梯度置零
out = model(data.x, data.edge_index) # 模型前向传播
loss = criterion(out[data.train_mask],data.y[data.train_mask]) # 计算loss
loss.backward() # 反向传播
optimizer.step() # 优化器梯度下降
return loss
#训练
for epoch in range(1, 201):
loss = train(model,data,optimizer,criterion)
print(f'Epoch: {epoch:03d}, Loss: {loss:.4f}')在训练过程结束后,我们检测GCN节点分类器在测试集上的准确性:
# 测试函数
def test(model, data):
model.eval()
out = model(data.x, data.edge_index)
pred = out.argmax(dim=1) # 使用最大概率的类别作为预测结果
test_correct = pred[data.test_mask] == data.y[data.test_mask] # 获取正确标记的节点
test_acc = int(test_correct.sum()) / int(data.test_mask.sum()) # 计算正确率
return test_acc
# 精度评价
test_acc = test(model, data)
print(f'Test Accuracy: {test_acc:.4f}')Test Accuracy: 0.8100
Process finished with exit code 0现在的准确率达到了81%,比之前有着巨大的提升。这表明节点的邻接信息在取得更好的准确率方面起着关键作用。
最后我们还可以通过可视化我们训练过的模型输出的节点表征来再次验证这一点,现在同类节点的聚集在一起的情况更加明显了。
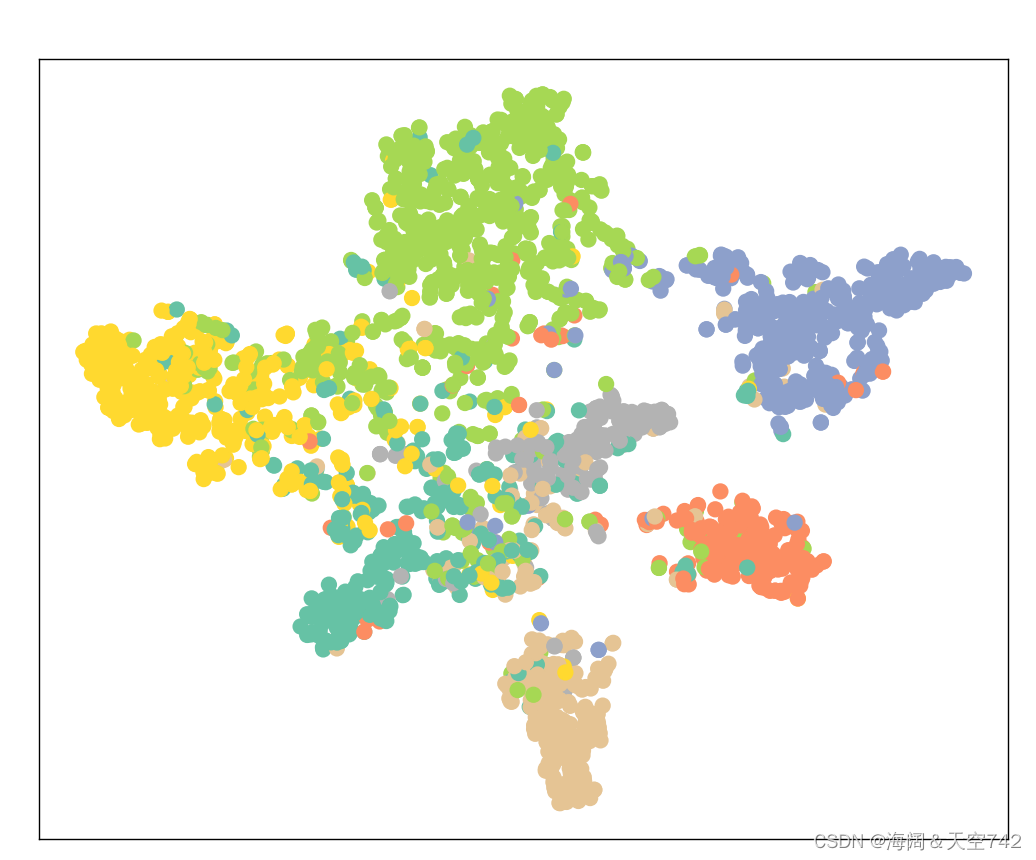
GAT及其在图节点分类任务中的应用

PyG中GATConv 模块说明
GATConv构造函数接口:


class GAT(torch.nn.Module):
def __init__(self, hidden_channels):
super(GAT, self).__init__()
torch.manual_seed(12345)
self.conv1 = GATConv(dataset.num_features, hidden_channels)
self.conv2 = GATConv(hidden_channels, dataset.num_classes)
def forward(self, x, edge_index):
x = self.conv1(x, edge_index)
x = x.relu()
x = F.dropout(x, p=0.5, training=self.training)
x = self.conv2(x, edge_index)
return x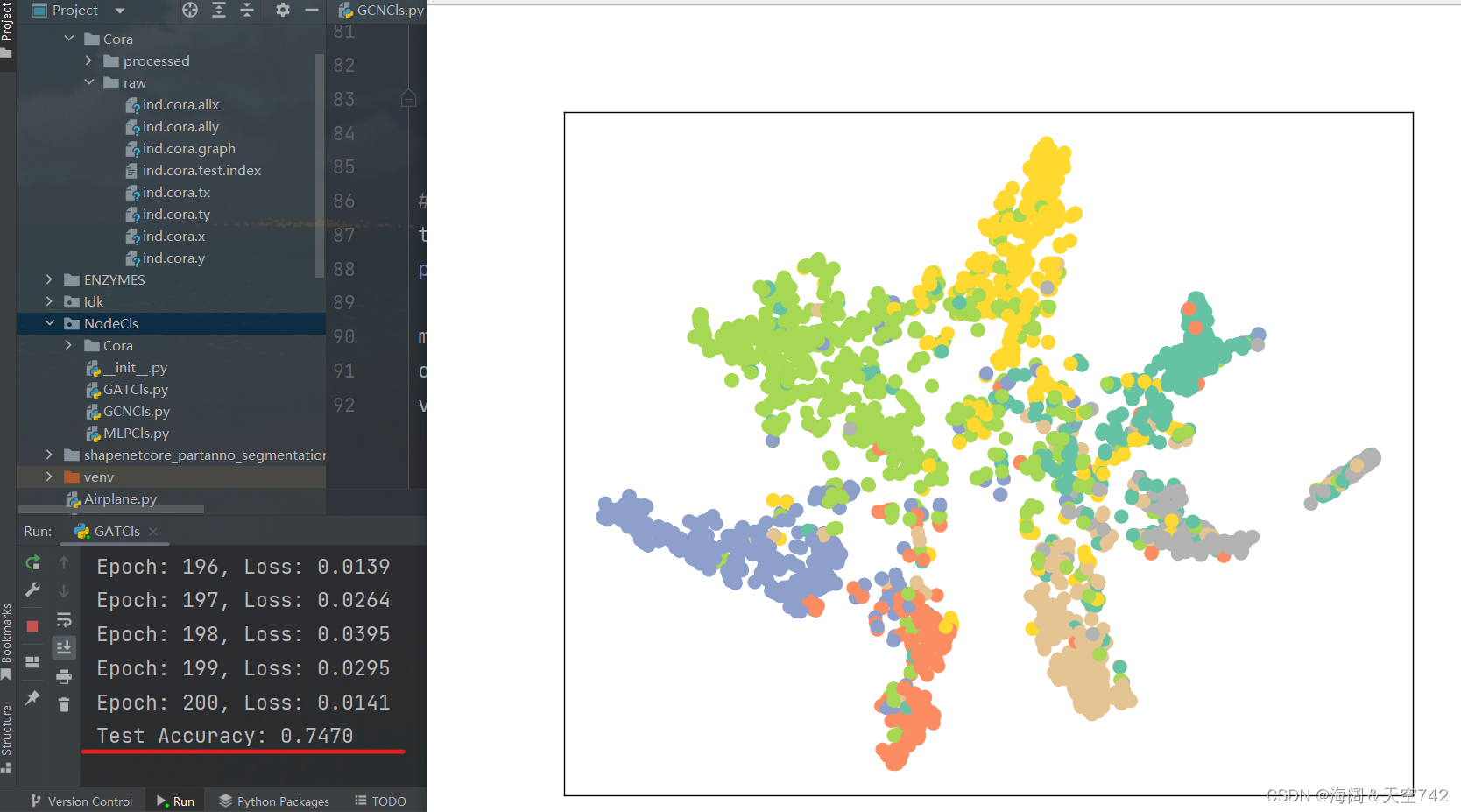
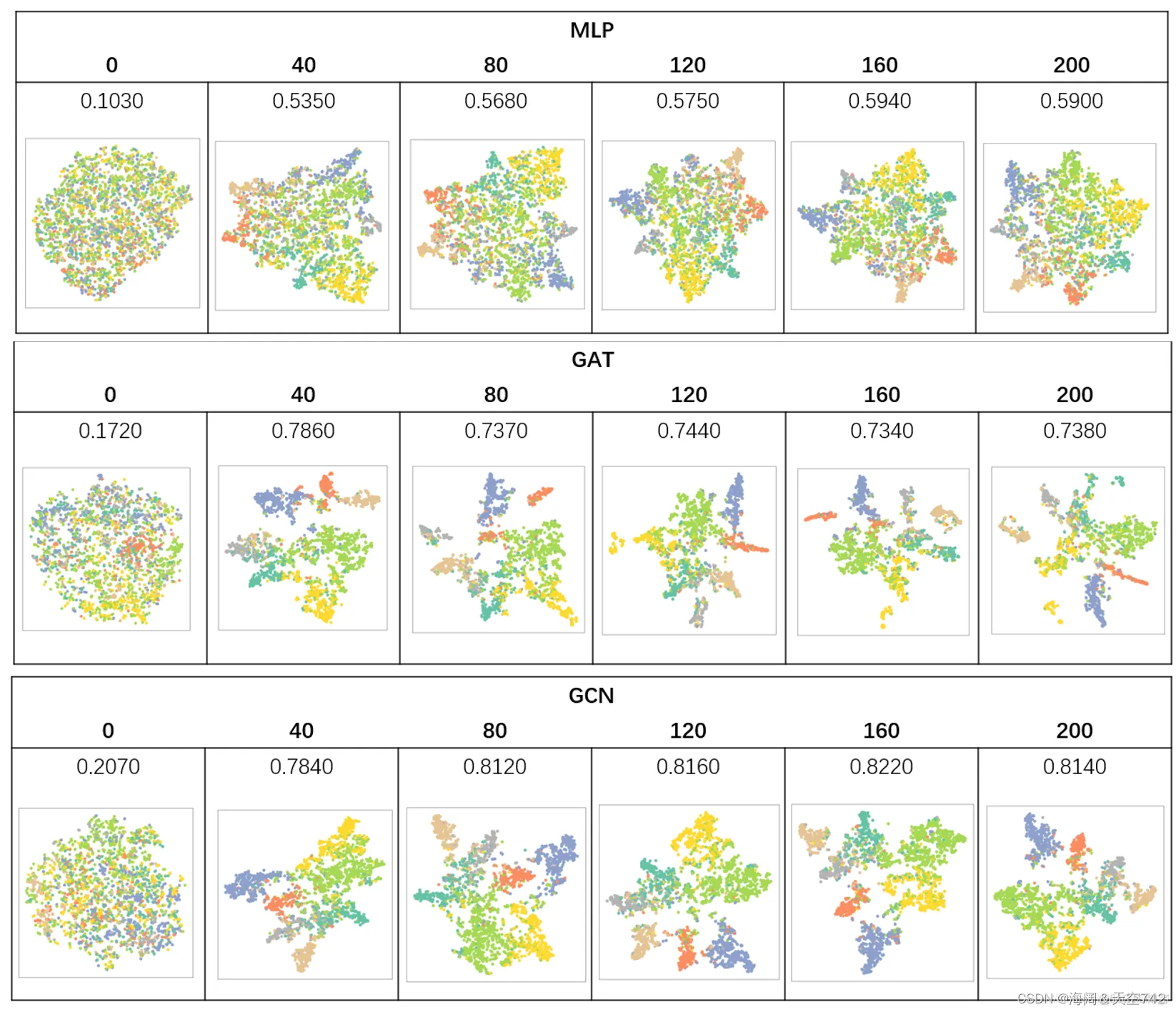
在Cora节点表征分类任务上,GCN表现最好,GAT次之,MLP最差,表明边信息(消息传递机制)对于图节点嵌入影响很大;
GAT所需训练轮次较少,易发生过拟合现象。
5.想法
讨论节点分类,但不考虑结构信息。可以尝试使用各个节点的特征信息进行分类。这种方法通常称为基于节点属性的分类。你可以使用机器学习算法,如决策树、支持向量机(SVM)或神经网络等,来学习训练节点和它们的特征之间的关系。这种方法较为简单直接,但可能会忽略节点之间的潜在关系。可以选择合适的特征表示和合适的分类算法,以获得较好的节点分类结果。
这种分类方法存在哪些问题?
1. 忽略节点之间的相互作用:节点之间的连接和关系通常承载着重要信息,忽略了结构信息可能导致无法准确捕捉到节点之间的相互作用和依赖关系。
2. 信息丢失:如果节点特征缺乏全面的信息,或者特征无法准确描述节点的特性,那么仅依靠这些特征可能会导致分类的不准确性。
为了改进这种情况,可以考虑以下方法:
1. 结合结构信息:引入节点的邻居信息、图的拓扑结构或图神经网络等方法,以捕捉节点之间的关系和上下文信息。通过结合节点特征和结构信息,可以提高节点分类的准确性。
2. 特征工程:通过进行特征工程来提取更多有用的特征。这可能包括从原始特征中提取高级特征、创建特征组合或使用特征选择方法等。
3. 半监督学习:如果只有部分节点有标签,可以考虑使用半监督学习方法。该方法利用已标记节点的信息来学习节点分类模型,并尝试预测未标记节点的标签。
4. 组合多个模型:可以尝试组合多个分类模型,如集成学习方法,以综合考虑节点特征和结构信息,提高分类性能。 记住,具体的改进方法可能根据你的数据和问题的特点而有所不同。试验不同的方法,并根据实验结果进行评估和调整。
针对特征工程,有以下几种方式:
在节点分类中,特征工程可以用于提取更有信息量的特征,从而改善分类性能。下面是几种常见的特征工程方法,可以帮助解决前述提到的问题:
1. 原始特征的转换:根据问题和数据的特点,对原始特征进行适当的转换。例如,对连续特征进行离散化、归一化或标准化,对类别特征进行独热编码或编码映射等。这样可以使特征更具有可比性和表达能力。
2. 特征组合与交互:结合已有的特征,构造新的特征组合或交互特征,以捕捉更丰富的信息。例如,对两个特征进行加减乘除运算,生成新的特征。这可以帮助模型学习更复杂的模式和关系。
3. 统计特征:基于节点自身的属性进行统计计算,生成统计特征。例如,对邻居节点的特征进行统计汇总,如平均值、最大值、最小值、方差等,作为节点的特征之一。
4. 图结构特征:通过分析图的结构信息,提取与节点相关的图结构特征。例如,节点的度中心性、节点所在的网络社区、路径特征(如最短路径长度、网络距离等)等。这些特征可以帮助模型捕捉节点之间的相互作用。
5. 基于领域知识的特征设计:结合领域知识,根据问题的特点和对节点分类的理解,设计并提取更具判断力的特征。这可能需要对数据进行领域专家的咨询和深入分析。
如何用半监督学习方法解决仅根据节点自身特征信息分类导致效果不好的问题?
当仅仅使用节点自身特征信息进行分类时,可能面临样本稀缺或者特征不具有区分度等问题,而半监督学习方法可以帮助解决这些问题。以下是一些常见的半监督学习方法,可用于改善仅使用节点自身特征信息分类效果不好的情况:
1. 标签传播算法:标签传播算法基于已有的有标签样本,利用节点之间的相似性或连接性进行标签的传播。通过将有标签样本的标签逐步传播到无标签样本,可以为无标签样本生成预测标签。这样利用了数据集中的未标签样本信息,提升了分类的性能。
2. 扩展标签传播算法:扩展标签传播算法引入了一种基于图割的方法来找到每个节点的合适标签。通过对连接节点之间的边进行割并,将无标签节点分配到最相关的标签类别中。这种方法结合了特征信息和图结构信息,能够有效地进行半监督分类。
3. 自训练(Self-Training):自训练是一种迭代的半监督学习方法,在训练过程中逐步增加无标签样本的标签。首先使用有标签数据训练一个初始模型,然后使用该模型对无标签数据进行预测,并将预测结果中置信度较高的样本作为伪标签加入到有标签数据中,再次训练模型。通过反复迭代,模型性能可以逐渐提高。
6.结语
在节点表征的学习中,MLP神经网络只考虑了节点自身属性,忽略了节点之间的连接关系,它的结果是最差的;而GCN图神经网络与GAT图神经网络,同时考虑了节点自身信息与周围邻接节点的信息,因此它们的结果都优于MLP神经网络。也就是说,对周围邻接节点的信息的考虑,是图神经网络优于普通深度神经网络的原因。
GCN图神经网络与GAT图神经网络的相同点为:
- 它们都遵循消息传递范式;
- 在邻接节点信息变换阶段,它们都对邻接节点做归一化和线性变换;
- 在邻接节点信息聚合阶段,它们都将变换后的邻接节点信息做求和聚合;
- 在中心节点信息变换阶段,它们都只是简单返回邻接节点信息聚合阶段的聚合结果。
GCN图神经网络与GAT图神经网络的区别在于采取的归一化方法不同:
- 前者根据中心节点与邻接节点的度计算归一化系数,后者根据中心节点与邻接节点的相似度计算归一化系数。
- 前者的归一化方式依赖于图的拓扑结构:不同的节点会有不同的度,同时不同节点的邻接节点的度也不同,于是在一些应用中GCN图神经网络会表现出较差的泛化能力。
- 后者的归一化方式依赖于中心节点与邻接节点的相似度,相似度是训练得到的,因此不受图的拓扑结构的影响,在不同的任务中都会有较好的泛化表现。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}