







本文约3500字,建议阅读8分钟
本文介绍了超参数指模型。超参数指的是模型参数(权重)之外的一些参数,比如深度学习模型训练时控制梯度下降速度的学习率,又比如决策树中分支的数量。超参数通常有两类:
模型:神经网络的设计,比如多少层,卷积神经网络的核大小,决策树的分支数量等。
训练和算法:学习率、批量大小等。
以下内容可在我的电子书网站阅读,效果更佳:
https://scale-py.godaai.org/ch-data-science/hyperparameter.html
搜索算法
确定这些超参数的方式是开启多个试验(Trial),每个试验测试超参数的某个值,根据模型训练结果的好坏来做选择,这个过程称为超参数调优。寻找最优超参数的过程这个过程可以手动进行,手动费时费力,效率低下,所以业界提出一些自动化的方法。常见的自动化的搜索方法有如下几种,下图展示了在二维搜索空间中进行超参数搜索,每个点表示一种超参数组合,颜色越暖,表示性能越好。迭代式的算法从初始点开始,后续试验依赖之前试验的结果,最后向性能较好的方向收敛。
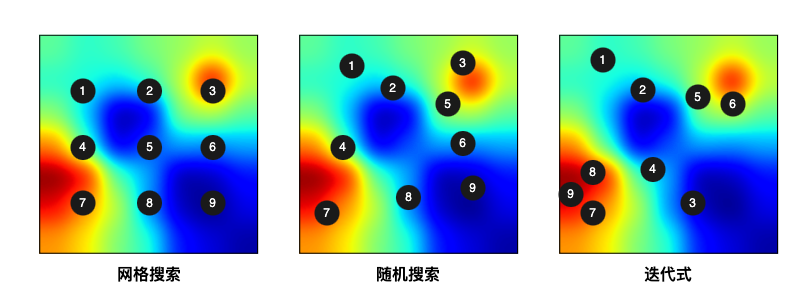
网格搜索(Grid Search):网格搜索是一种穷举搜索方法,它通过遍历所有可能的超参数组合来寻找最优解,这些组合会逐一被用来训练和评估模型。网格搜索简单直观,但当超参数空间很大时,所需的计算成本会急剧增加。
随机搜索(Random Search):随机搜索不是遍历所有可能的组合,而是在解空间中随机选择超参数组合进行评估。这种方法的效率通常高于网格搜索,因为它不需要评估所有可能的组合,而是通过随机抽样来探索参数空间。随机搜索尤其适用于超参数空间非常大或维度很高的情况,它可以在较少的尝试中发现性能良好的超参数配置。然而,由于随机性的存在,随机搜索可能会错过一些局部最优解,因此可能需要更多的尝试次数来确保找到一个好的解。
贝叶斯优化(Bayesian Optimization):贝叶斯优化是一种迭代式超参数搜索技术。它基于贝叶斯定理的技术,它利用概率模型来指导搜索最优超参数的过程。这种方法的核心思想是构建一个贝叶斯模型,通常是高斯过程(Gaussian Process),来近似评估目标函数的未知部分。贝叶斯优化能够在有限的评估次数内,智能地选择最有希望的超参数组合进行尝试,特别适用于计算成本高昂的场景。
超参数调优是一种黑盒优化,所谓黑盒优化,指的是目标函数是一个黑盒,我们只能通过观察其输入和输出来推断其行为。黑盒的概念比较难以理解,但是我们可以相比梯度下降算法,梯度下降算法不是一种黑盒优化算法,我们可以得到目标函数的梯度(或近似值),并用梯度来指导搜索方向,最终找到目标函数的(局部)最优解。黑盒优化算法一般无法找到目标函数的数学表达式和梯度,也无法使用基于梯度的优化技术。贝叶斯优化、遗传算法、模拟退火等都是黑盒优化,这些算法通常在超参数搜索空间中选择一些候选解,运行目标函数,得到超参数组合的实际性能,基于实际性能,不断迭代调整,即重复上述过程,直到满足条件。
贝叶斯优化
贝叶斯优化基于贝叶斯定理,这里不深入探讨详细的数学公式。简单来说,它需要先掌握搜索空间中几个观测样本点(Observation)的实际性能,构建概率模型,描述每个超参数在每个取值点上模型性能指标的均值和方差。其中,均值代表这个点最终的期望效果,均值越大表示模型最终性能指标越大,方差表示这个点的不确定性,方差越大表示这个点不确定,值得去探索。下图 在一个 1 维超参数搜索空间中迭代 3 步的过程,虚线是目标函数的真实值,实线是预测值(或者叫后验概率分布均值),实线上下的蓝色区域为置信区间。贝叶斯优化利用了高斯回归过程,即目标函数是由一系列观测样本点所构成的随机过程,通过高斯概率模型来描述这个随机过程的概率分布。贝叶斯优化通过不断地收集观测样本点来更新目标函数的后验分布,直到后验分布基本贴合真实分布。对应下图中,进行迭代 3 之前只有两个观测样本点,经过迭代 3 和迭代 4 之后,增加了新的观测样本点,这几个样本点附近的预测值逐渐接近真实值。
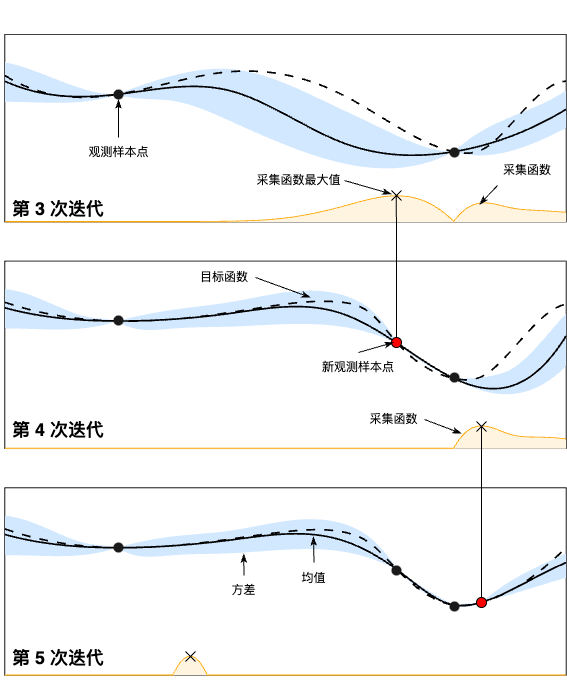
贝叶斯优化有两个核心概念:
代理模型(Surrogate Model):代理模型拟合观测值,预测实际性能,可以理解为图中的实线。
采集函数(Acquisition Function):采集函数用于选择下一个采样点,它使用一些方法,衡量每一个点对目标函数优化的贡献,可以理解为图中橘黄色的线。
为防止陷入局部最优,采集函数在选取下一个取值点时,应该既考虑利用(Exploit)那些均值较大的,又探索(Explore)那些方差较大的,即在利用和探索之间寻找一个平衡。例如,模型训练非常耗时,有限的计算资源只能再跑 1 组超参数了,那应该选择均值较大的,因为这样能选到最优结果的可能性最高;如果我们计算资源还能可以跑上千次,那应该多探索不同的可能性。在上图的例子中,第 3 次迭代和第 2 次迭代都在第 2 次迭代的观测值附近选择新的点,是在探索和利用之间的一个平衡。
相比网格搜索和随机搜索,贝叶斯优化并不容易并行化,因为贝叶斯优化需要先运行一些超参数组合,掌握一些实际观测数据。
调度器
连续减半算法
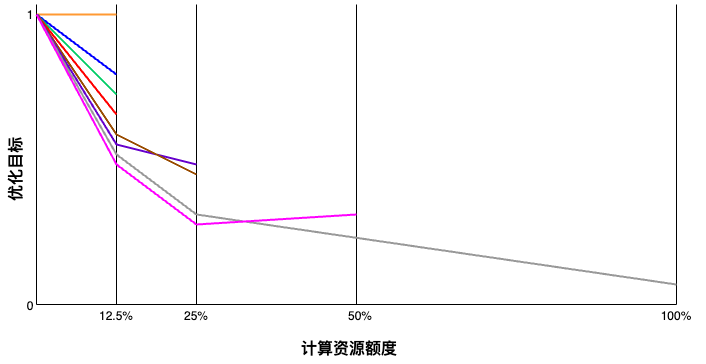
连续减半算法(Successive Halving Algorithm, SHA)的核心思想非常简单,如下图所示:
SHA 最开始给每个超参数组合一些计算资源额度。
将这些超参数组合都训练执行完后,对结果进行评估。
选出排序靠前的超参数组合,进行下一轮(Rung)训练,性能较差的超参数组合早停。
下一轮每个超参数组合的计算资源额度以一定的策略增加。
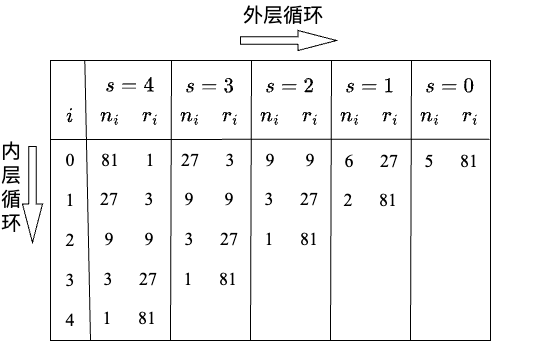
计算资源额度(Budget)可以是训练的迭代次数,或训练样本数量等。更精确地,SHA 每轮丢掉 的超参数组合,留下 进入下一轮,下一轮每个超参数组合的计算资源额度变为原来的 倍。下表中,每轮总的计算资源为 ,总共 81 个超参数组合;第一轮每个试验能分到 的计算资源;假设 为 3,只有 的试验会被提升到下一轮,经过 5 轮后,某个最优超参数组合会被选拔出来。
| 超参数组合数量 | 每个试验所被分配的计算资源 | |
|---|---|---|
| Rung 1 | 81 | B/81 |
| Rung 2 | 27 | B/27 |
| Rung 3 | 9 | B/9 |
| Rung 4 | 3 | B/3 |
| Rung 5 | 1 | B |
SHA 中,需要等待同一轮所有超参数组合训练完并评估结果后,才能进入下一轮;第一轮时,可以并行地执行多个试验,而进入到后几轮,试验越来越少,并行度越来越低。ASHA(Asynchronous Successive Halving Algorithm) 针对 SHA 进行了优化,ASHA 算法不需要等某一轮的训练和评估结束选出下一轮入选者,而是在当前轮进行中的同时,选出可以提升到下一轮的超参数组合,前一轮的训练评估与下一轮的训练评估是同步进行的。
SHA 和 ASHA 的一个主要假设是,如果一个试验在初始时间表现良好,那么它在更长的时间内也会表现良好。这个假设显然太过粗糙,一个反例是学习率:较大的学习率在短期内可能会比较小的学习率表现得更好,但长远来看,较大学习率不一定是最优的,SHA 调度器很有可能导致较小学习率的试验被错误地提前终止。从另外一个角度,为了避免潜在的优质试验提前结束,需要在第一轮时给每个试验更多的计算资源,但由于总的计算资源额度有限(),所以一种折中方式是选择较少的超参数组合,即 的数量要少一些。
Hyperband
SHA/ASHA 等算法面临着 和 相互平衡的问题:如果 太大,每个试验所能分到的资源有限,导致优质试验可能提前结束;如果 太小,可选择的搜索空间有限,也可能导致优质试验未被囊括到搜索空间中。HyperBand 算法在 SHA 基础上提出了一种对冲机制。HyperBand 有点像金融投资组合,使用多种金融资产来对冲风险,初始轮不是一个固定的 ,而是有多个可能的 。如下图所示,算法实现上,HyperBand 使用了两层循环,内层循环直接调用 SHA 算法,外层循环尝试不同的 ,每种可能性是一种 。HyperBand 额外引入了变量 , 指的是某一个超参数组合所能分配的最大的计算资源额度, 是一共多少可能性,它可以被计算出来:;由于额外引入了 ,此时总的计算资源 ,加一是因为 从 0 开始计算。

下图是一个例子:横轴是外层循环,共有 5 个(0 到 4)可能性,初始的计算资源 和每个超参数组合所能获得的计算资源 形成一个组合(Bracket);纵轴是内层循环,对于某一种初始的 Bracket,执行 SHA 算法,一直迭代到选出最优试验。
BOHB
BOHB 是一种结合了贝叶斯优化和 Hyperband 的调度器。
Population Based Training
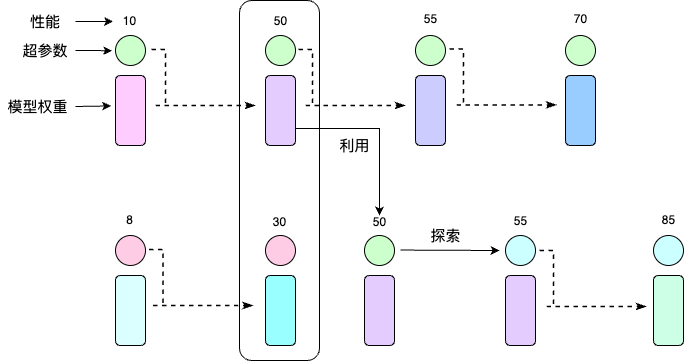
种群训练(Population Based Training,PBT) 主要针对深度神经网络训练,它借鉴了遗传算法的思想,可以同时优化模型参数和超参数。PBT 中,种群可以简单理解成不同的试验,PBT 并行地启动多个试验,每个试验从超参数搜索空间中随机选择一个超参数组合,并随机初始化参数矩阵,训练过程中会定期地评估模型指标。模型训练过程中,基于模型性能指标,PBT 会利用或探索当前试验的模型参数或超参数。当前试验的指标不理想,PBT 会执行“利用”,将当前模型权重换成种群中其他表现较好的参数权重。PBT 也会“探索”:变异生成新的超参数进行接下来的训练。在一次完整的训练过程中,其他超参数调优方法会选择一种超参数组合完成整个训练;PBT 在训练过程中借鉴效果更好的模型权重,或使用新的超参数,因此它被认为同时优化模型参数和超参数。
编辑:王菁
校对:林亦霖
















 1837
1837











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









