







来源:专知
本文约3000字,建议阅读5分钟
这篇论文探讨了如何通过将实体信息纳入神经网络模型来增强自然语言理解。
这篇论文探讨了如何通过将实体信息纳入神经网络模型来增强自然语言理解。它解决了三个关键问题:
利用实体进行理解任务:本文引入了Entity-GCN模型,该模型在一个图上执行多步推理,其中节点代表实体提及,边代表关系。这种方法在一个多文档问答数据集上取得了最先进的结果。
使用大型语言模型识别和消歧实体:该研究提出了一种新颖的系统,通过逐字生成实体名称来检索实体,克服了传统方法的局限性,并显著减少了内存占用。该方法还扩展到了多语言环境,并进一步优化了效率。
解释和控制模型中的实体知识:本文提出了一种事后解释技术,用于分析神经模型各层的决策过程,允许对知识表示进行可视化和分析。此外,提出了一种编辑实体事实知识的方法,使得在无需昂贵的重新训练的情况下能够修正模型预测。
实体在我们表示和汇总知识的方式中处于中心地位。例如,像维基百科这样的百科全书是按实体组织的(例如,每篇维基百科文章对应一个实体)。书面百科全书已有约两千年的历史(例如,《自然史》可以追溯到公元77年),在此期间,它们在形式、语言、风格及许多其他方面都有了很大的发展。《百科全书,或科学、艺术和工艺详解词典》(在1751年至1772年间于法国出版;狄德罗和达朗贝尔,1751)和《大英百科全书》(在1768年至1771年间于苏格兰出版;斯梅利,1768)通常被认为是现代历史上第一部印刷的百科全书,并定义了信息传播的重大变革。尽管内容和语言可能有所不同,但通过实体、类别和交叉引用组织信息的基本方式在几个世纪以来几乎没有改变。以这种方式组织世界知识对人类来说是自然且方便的,但对机器来说如何呢?机器学习算法能否利用我们的分类方式?我们能否构建能够连接不同知识点或区分模糊概念的计算机算法?虽然这些复杂问题目前还没有明确的答案,但在本文中,我们将论证,向自然语言处理(NLP)算法提供关于实体性质的额外信息,可以提高其在许多有用应用中的性能。
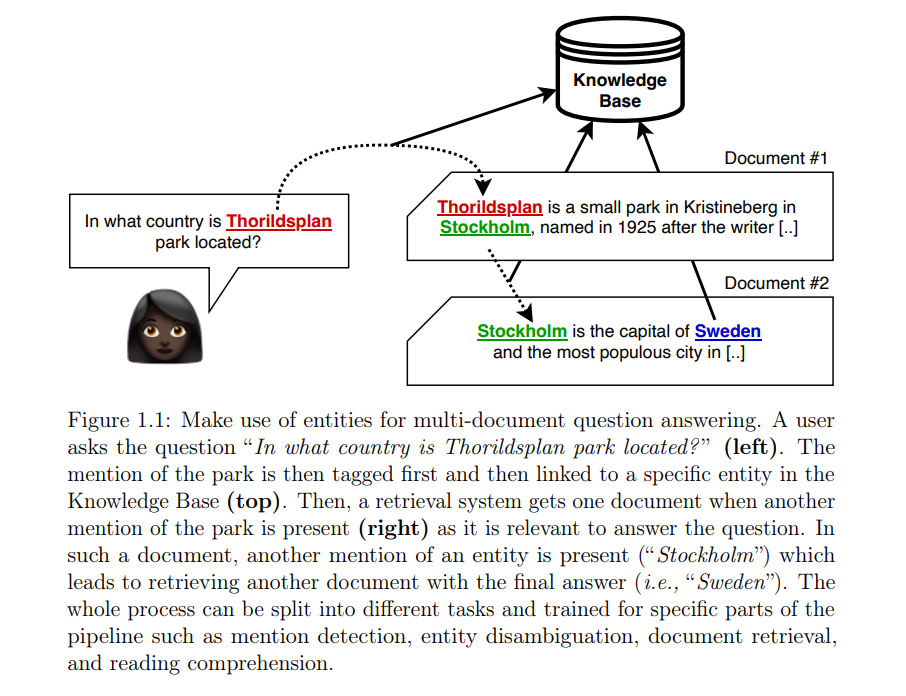
让我们从一个利用实体进行多文档问答的例子开始。在这种情况下,用户向信息系统提出问题,该系统需要在文档库中搜索答案。此外,我们假设需要跨多个文档进行分析和推理,因为在单个文档中找不到简单的答案。图1.1展示了在这种情况下获得答案的机器辅助过程。正如我们从中看到的那样,机器进行的过程旨在模仿人类的行为,这似乎是一种合理的策略。我们假设将这种复杂任务分解为可学习的子步骤会导致整体系统的改进和人类可解释性。我们可以使用客观指标来验证这一任务是否如此。
用于自然语言理解的实体 为了研究上述问题,在第三章中,我们探讨了如何利用实体来解决自然语言理解(NLU)。我们引入了一种依靠在多个文档内外传播的信息进行“推理”的神经模型。我们的假设是,通过引用实体进行“推理”(学习)步骤使模型输出预测,将使其学会处理复杂问题的合理且更具普遍性的策略。文本中出现的实体提及进行了注释,这使得测试我们的假设变得更容易。然后,我们将任务框定为图上的推理问题。这些提及是图的节点,而边则编码了不同提及之间的关系(例如,文档内和跨文档的共指关系)。图卷积网络(GCN)应用于这些图,并经过训练以执行多步推理。我们展示了使用额外的实体信息可以实现一种可扩展且紧凑的方法,在开发时(即2018年)在一个流行的多文档问答数据集WikiHop上取得了最先进的结果。
第三章的发现为更有趣的问题打开了大门,因为我们贡献的一个限制因素是所有实体的提及都作为输入提供给模型。检索文本中实体提及的能力对于知识密集型任务(如开放领域问答和对话)至关重要。因此,一个自然的问题出现了:我们如何利用语言模型来识别和消歧文本中的实体?
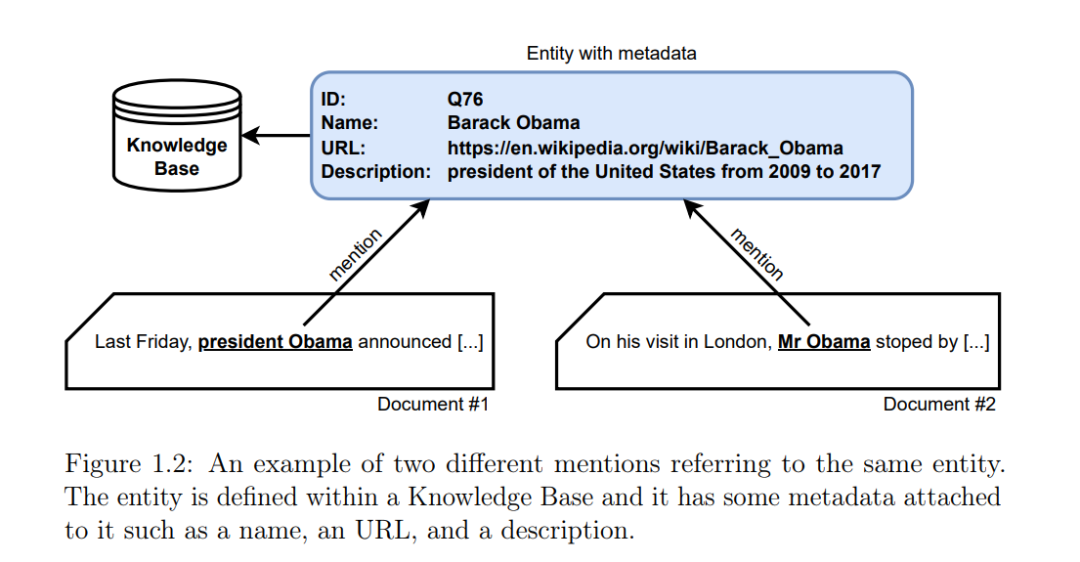
使用语言模型在文本中查找实体 实体链接(EL;Bunescu & Paşca,2006;Cucerzan,2007;Dredze等,2010;Hoffart等,2011;Le & Titov,2018)是NLP中的一项基本任务,用作文本理解的构建模块(Févry等,2020b;Verga等,2020)。它包括将非结构化文本中的实体提及锚定到知识库(KB)标识符(例如,维基百科文章)。实体链接在多个领域有广泛应用,涵盖开放领域问答(De Cao等,2019b;Nie等,2019;Asai等,2020)、对话(Bordes等,2017;Wen等,2017;Williams等,2017;Chen等,2017b;Curry等,2018;Sevegnani等,2021)、生物医学系统(Leaman & Gonzalez,2008;Zheng等,2015)、信息抽取(Sarawagi,2008;Martinez-Rodriguez等,2020)等。在图1.2中,我们展示了将提及链接到知识库中相关实体的例子。
尽管之前有大量关于实体检索的研究(例如,Hoffart等,2011;Piccinno & Ferragina,2014;Huang等,2015;Le & Titov,2018;Logeswaran等,2019;Broscheit,2019;Wu等,2020,仅举几例),但大多数当前解决方案的一个共同设计选择是:实体与唯一的原子标签相关联,可以将检索问题解释为跨这些标签的多类分类。输入和标签之间的匹配通过双编码器(Wu等,2020;Karpukhin等,2020)计算:输入的密集向量编码与实体信息(如标题和描述)的编码之间的点积。这种形式化允许使用现代最大内积搜索库(Johnson等,2019)进行亚线性搜索,从而支持从大型实体数据库中检索。在第四章中,我们提出了一种新颖的方法:第一个通过逐字生成其唯一名称(从左到右,自回归方式)来检索实体的系统。我们的模型缓解了当时广泛采用的现代模型(4)可能忽略文本和知识库中实体之间的细粒度交互的限制。此外,我们显著减少了当前系统的内存占用(最多15倍),因为我们的编码器-解码器架构的参数随词汇量的变化而不是实体数量的变化而变化。我们还将我们的方法扩展到一个包含100多种语言的大型多语言环境(第五章)。在这种环境中,我们对尽可能多语言的实体名称进行匹配,这允许利用源输入和目标名称之间的语言连接。最后,我们还提出了一种非常高效的方法,可以在文本片段中的所有潜在提及上并行化自回归链接。这样的系统依赖于一个浅层且高效的解码器,使得模型速度提高超过70倍且没有性能下降(第六章)。
语言模型的可解释性和可控性 第四、五和六章的发现为许多子领域的许多有趣应用打开了大门。我们研究的一个引人注目的方面是,它表明系统的大部分收益来自模型回忆起其在语言建模预训练和任务特定微调过程中获得的实体名称记忆的能力。不幸的是,这种能力是有代价的。因为大多数(如果不是全部)基于深度学习的语言模型都是黑箱函数。因此,我们不能完全理解它们的预测,也不能确定它们是推理还是记忆。当它们记忆时,我们通常也不能轻松地控制添加、删除或修改这些记忆的方式和位置。这些反思引出了下一个研究问题:我们如何解释和控制模型内部关于实体的知识?
为此,在第七章中,我们介绍了一种新的事后解释技术,用于检查神经模型各层决策的形成方式。我们的系统学习屏蔽向量子集,同时保持可微性。这不仅让我们能够绘制归因热图,还能分析决策在网络层中的形成方式。我们使用该系统研究了BERT模型(Devlin等,2019a)在情感分类和问答任务中的表现,并展示了该技术也可以应用于第三章提出的基于图的模型。最后,我们还提出了一种可以用于编辑语言模型中实体事实知识的方法,从而在无需昂贵的重新训练或微调的情况下修复“错误”或意外预测(第八章)。
贡献 本论文的主要贡献可总结如下:
我们引入了一种依靠在多个文档内外传播的信息进行推理的神经模型。我们将其框定为图上的推理问题。实体提及是该图的节点,而边则编码了不同提及之间的关系。
我们提出了一个系统,通过生成实体的唯一名称(自回归方式)来识别文本中的实体并将其链接到外部知识库中,支持100多种语言。我们采用受限生成方法,将这种生成自回归模型用作分类器。
我们提出了一种新的事后解释技术,用于检查神经模型各层决策的形成方式。
我们开发了一种方法,可以编辑语言模型内部的实体事实知识,从而在无需昂贵的重新训练或微调的情况下修复“错误”或意外预测。
大多数(如果不是全部)研究结果表明,实体在自然语言处理中的核心作用,我们鼓励在更多任务中纳入实体信息的研究。




关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU















 469
469

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









