







本文约2000字,建议阅读9分钟本文讲述了随着多模态大模型的发展,模型能够处理视觉语言输入进行多模态数学推理等现象。
论文题目:
Math-LLaVA: Bootstrapping Mathematical Reasoning for Multimodal Large Language Models
论文链接:
https://arxiv.org/abs/2406.17294
开源链接:
https://github.com/HZQ950419/Math-LLaVA
01 动机和背景
近年来,大语言模型在数学推理中取得优异的表现,随着多模态大模型的发展,模型能够处理视觉语言输入进行多模态数学推理。然而,现有的视觉指令数据集中,每张图像对应有限的问题答案数据对,没有充分利用视觉信息来增强多模态大模型的数学推理能力。
为此,我们从多种数据集中收集 4 万张高质量图像和问答数据对。通过对图像各部分视觉信息充分提问,以及对问题数据进行增强,构建了一个高质量、多样化的合成多模态问答数据集,从而增强多模态大模型数学推理的能力。本项工作强调合成高质量的多模态问答数据集在提高多模态大模型数学推理能力方面的重要性。
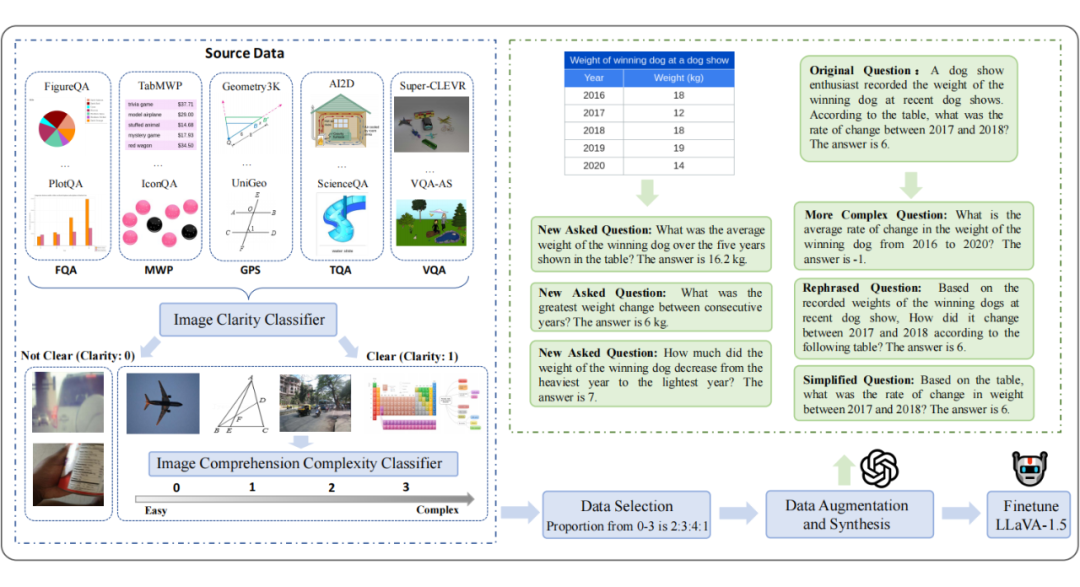
02 数据集合成
2.1 源数据收集
我们针对五种需要高水平推理能力的问题任务类型收集了 24 个多模态视觉问答和数学推理源数据集,任务类型包括 Figure Question Answering(FQA),Geometry Problem Solving(GPS),Math Word Problem(MWP),Textbook Question Answering(TQA),Visual Question Answering(VQA)。
在获取源数据集后,我们根据图像清晰质量和理解复杂度从中挑选高质量,理解难度分布合适的图像集。具体地,我们使用 GPT4-V 对随机均匀采样的 1 万张图像的清晰度和理解复杂度进行标注,对于图像清晰度,标签 0 表示图像模糊质量差,标签 1 表示图像清晰质量好。
图像理解复杂度取决于物体数量、位置关系、细节程度、纹理、材料属性以及是否涉及数学计算,分值设为 0 到 3 分。之后根据图像标注数据微调图像分类器,分别对源数据集的图像清晰度和理解复杂度进行打分。如下表所示,包含每个源数据集的任务类型、视觉背景以及图像清晰度和理解复杂度的分布。
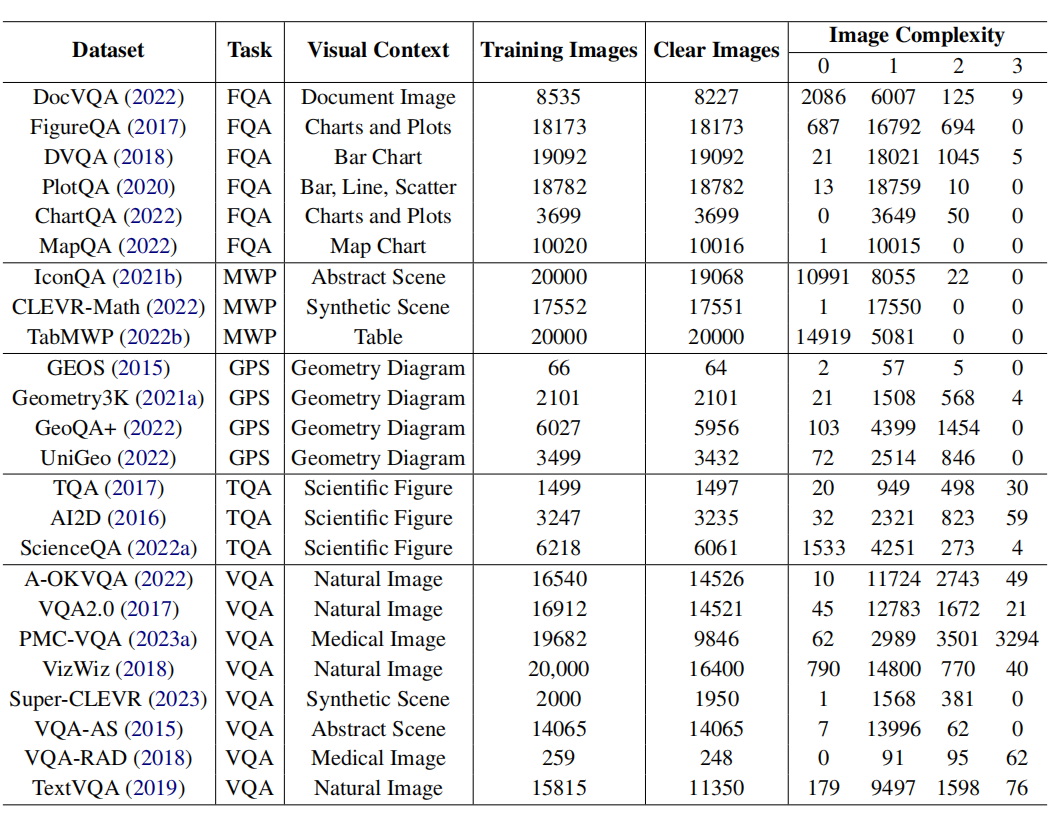
我们过滤掉低质量的图像,按图像理解复杂度从简单到复杂渐进地采样,由于分值为 3 的图像数量最少,因此收集全部。最终我们根据复杂度 2:3:4:1 的比例均匀选取 4 万张图像,这些数据的图像信息多样且难度逐步递增。
2.2 数据增强
在收集的多模态问答数据中,每个图像对应有限的问题,没有充分利用图像的视觉信息。因此,我们使用 GPT-4V 以 few-shot 的方式为每幅图像生成更多问题答案对。具体地,对于属于某任务类别的图像,首先将属于该类别的每个源数据集内部的问题进行聚类,再从每个源数据集的每个聚类中随机采样一个问题来共同构建注释参考。以此,GPT-4V 新合成与原始问题分布接近,多样的 20 万个问答数据对。
我们再使用 GPT-4V 对原始问题进行增强,生成了 4 万个更复杂的问题,4 万个简化的问题和 4 万个逻辑一致的问题,以进一步提高模型的推理能力和鲁棒性。最终我们构建了 36 万高质量、多样化的合成多模态问答数据集 MathV360K.
03 实验结果
我们使用 MathV360K 对 LLaVA-1.5-13B 进行微调得到我们的模型 Math-LLaVA,并在 MathVista 和 MATH-Vision 数据集上进行了测试。其中 Math-LLaVA 在 MathVista minitest 中达到了46.6%,相对于 base model 提升了 19 个百分点。此外,在更困难的 MATH-Vision 数据集上达到 15.69%,超过了 Qwen-VL-Max(15.59%)。
MathVista minitest 数据集上不同方法模型的测试结果如下:
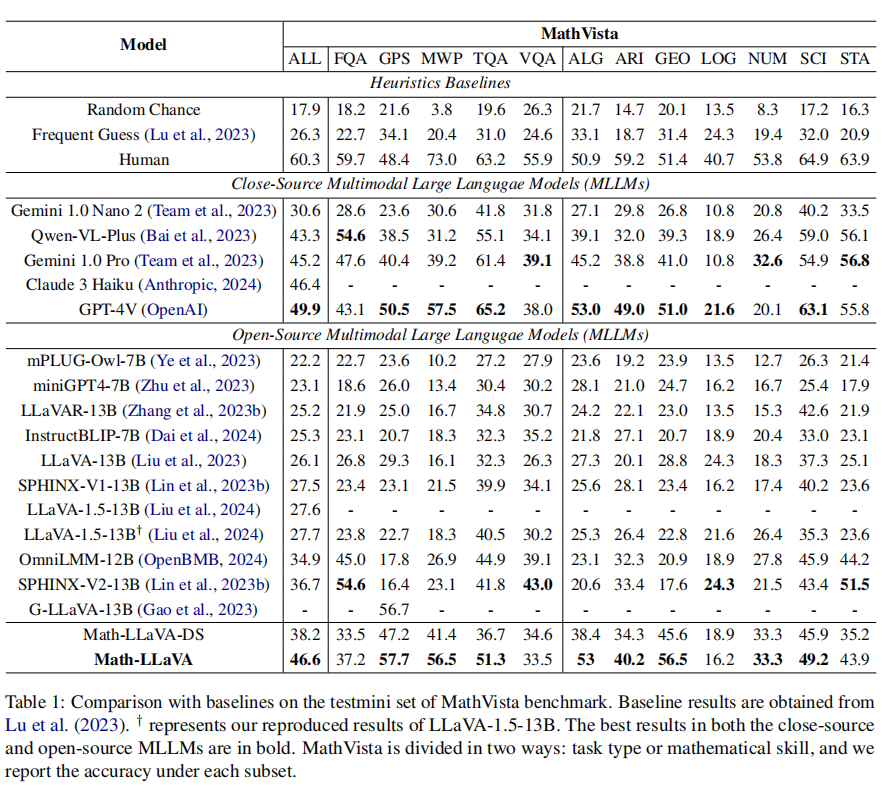
为了验证 Math-LLaVA 的泛化性以及使用我们的合成数据微调不会削弱模型在其他领域的推理能力,我们在 MMMU 数据集上进行验证。MMMU validation 数据集上不同方法模型的测试结果如下:
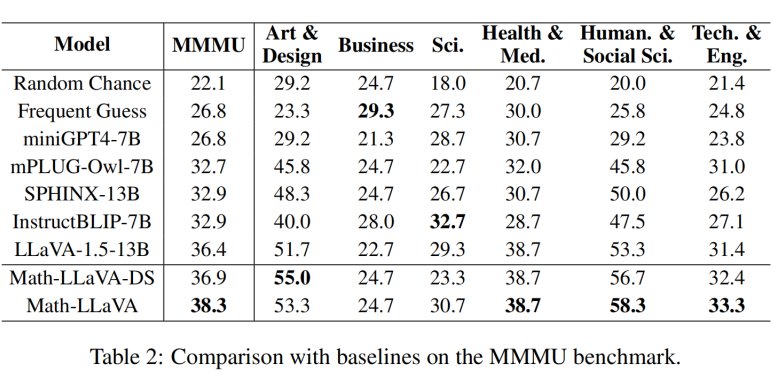
我们对数据收集和增强方式进行消融实验,结果如下,说明我们的数据收集和不同增强方法都能提高多模态大模型的数学推理能力。

此外,为了探究对每种任务类型的源数据进行增强的有效性,结果如下:
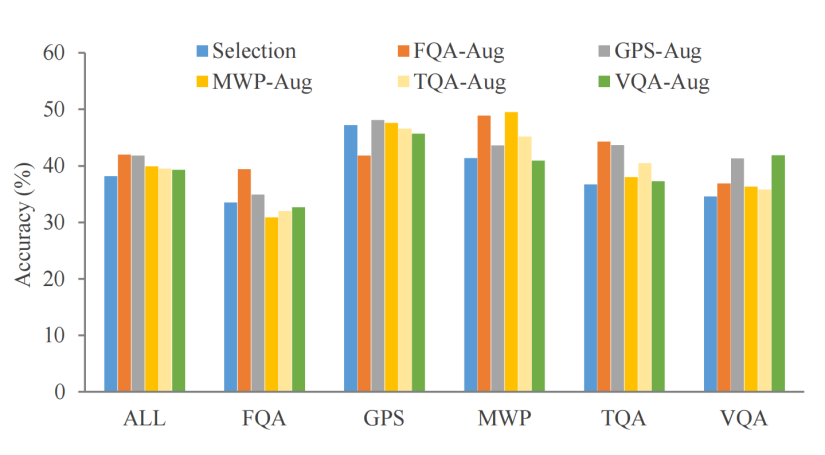
04 总结
我们构建了一个高质量和多样化的多模态问答数据集 MathV360K,可供社区在多模态大模型上使用,我们的合成数据集充分利用了图像的视觉信息进行提问并对原始问题进行增强,提高了多模态数学问题的广度和深度,可进一步提高多模态数学推理能力和模型鲁棒性。
通过使用 MathV360K,我们对 LLaVA-1.5 进行微调得到 Math-LLaVA,显著提高了其多模态数学推理能力,在 MathVista testmini 上取得 46.6% 的准确率,比基础模型提高了 19%。在 MATH-Vision 数据集上达到 15.69%,超过了Qwen-VL-Max 的 15.59%。此外,Math-LLaVA 还在 MMMU 数据集上展现了一定的泛化性。对于未来的工作,我们将引入带注释的中间步骤,构建更全面、更高质量的数据集,进一步增强多模态大模型的推理能力。
编辑:王菁
关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU

















 1243
1243

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









