







来源:DeepHub IMBA
本文约1500字,建议阅读5分钟
本文将探索遍历pandas dataframe的各种方法,检查每个循环方法的相关运行时。循环是我们编程技能中的一项固有技能。当我们熟悉任何编程语言时,循环就会成为一个基本的、易于解释的概念。
在这篇博文中,我们将探索遍历pandas dataframe的各种方法,检查每个循环方法的相关运行时。为了验证循环的有效性,我们将生成百万级别的数据,这也是我们在日常处理中经常遇到的数量级。

实验数据集
我们将生成一个包含600万行和4列的DataFrame。每一列将被分配一个0到50之间的随机整数。
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randint(0, 50, size=(6000000, 4)), columns=('a','b','c','d'))
df.shape
# (6000000, 5)
df.head()
Iterrows
我们通过基于以下标准引入一个新的列' e '来扩展数据框架' df ':
如果' a '等于0,那么' e '取' d '的值。如果' a '在0(不包括)到25(包括)的范围内,' e '计算为' b '减去' c '。如果以上条件都不成立,则计算“e”为“b”+“c”。
首先我们使用pandas提供的' iterrows() '函数遍历DataFrame ' df '。' iterrows() '函数遍历DataFrame的行,在迭代期间返回(index, row)对。
import time
start = time.time()
# Iterating through DataFrame using iterrows
for idx, row in df.iterrows():
if row.a == 0:
df.at[idx,'e'] = row.d
elif (row.a <= 25) & (row.a > 0):
df.at[idx,'e'] = (row.b)-(row.c)
else:
df.at[idx,'e'] = row.b + row.c
end = time.time()
print(end - start)
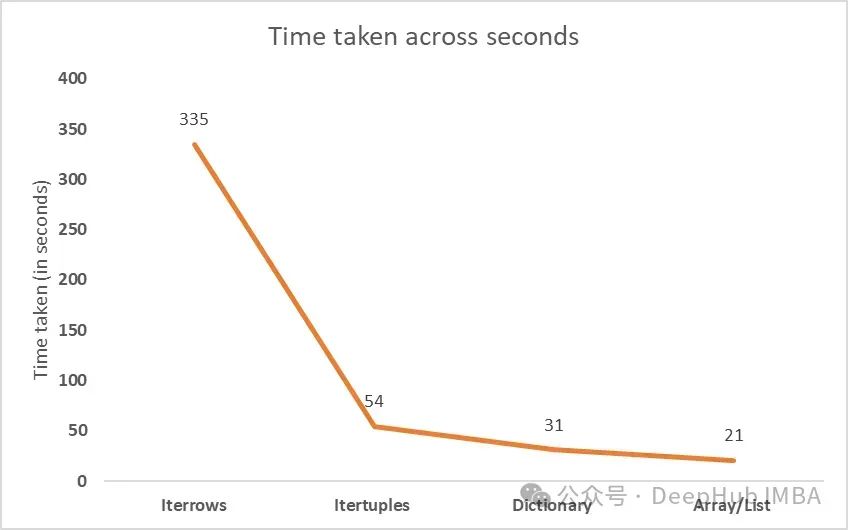
# time taken: 335.212792634964iterrows()函数需要335秒(约5.5分钟)来实现对600万行的操作。
Itertuples
另一种遍历pandas DataFrame的方法是使用' itertuples ',它以命名元组的形式遍历DataFrame行。
下面代码说明了如何使用' itertuples '访问元素。生成的行对象将索引作为第一个字段,然后是数据框的列。
for row in df[:1].itertuples():
print(row) ## accessing the complete row - index following by columns
print(row.Index) ## accessing the index of the row
print(row.a) ## accessing the value of column 'a'
使用下面的代码,使用itertuples()遍历DataFrame df。
start = time.time()
# Iterating through namedtuples
for row in df.itertuples():
if row.a == 0:
df.at[row.Index,'e'] = row.d
elif (row.a <= 25) & (row.a > 0):
df.at[row.Index,'e'] = (row.b)-(row.c)
else:
df.at[row.Index,'e'] = row.b + row.c
end = time.time()
print(end - start)
## Time taken: 41 seconds在DataFrame上执行所需的操作,itertuples()函数耗时约54秒,比iterrows()函数快6倍。
字典
迭代DataFrame行的另一种方法是将DataFrame转换为字典,这是一种轻量级的内置数据类型。我们遍历该字典以执行所需的操作,然后将更新后的字典转换回DataFrame。转换可以使用' to_dict() '函数来实现。
start = time.time()
# converting the DataFrame to a dictionary
df_dict = df.to_dict('records')
# Iterating through the dictionary
for row in df_dict[:]:
if row['a'] == 0:
row['e'] = row['d']
elif row['a'] <= 25 & row['a'] > 0:
row['e'] = row['b']-row['c']
else:
row['e'] = row['b'] + row['c']
# converting back to DataFrame
df4 = pd.DataFrame(df_dict)
end = time.time()
print(end - start)
## Time taken: 31 seconds字典方法大约需要31秒,大约比' itertuples() '函数快11倍。
数组列表
我们还可以将DataFrame转换为一个数组,遍历该数组以对每行(存储在列表中)执行操作,然后将该列表转换回DataFrame。
start = time.time()
# create an empty dictionary
list2 = []
# intialize column having 0s.
df['e'] = 0
# iterate through a NumPy array
for row in df.values:
if row[0] == 0:
row[4] = row[3]
elif row[0] <= 25 & row[0] > 0:
row[4] = row[1]-row[2]
else:
row[4] = row[1] + row[2]
## append values to a list
list2.append(row)
## convert the list to a dataframe
df2 = pd.DataFrame(list2, columns=['a', 'b', 'c', 'd','e'])
end = time.time()
print(end - start)
#Time Taken: 21 seconds花费的时间约为21秒(比iterrows快16倍),这与遍历字典所花费的时间非常接近。
字典和数组是内置的轻量级数据结构,因此迭代DataFrame所需的时间最少。
总结
在文探索了使用循环遍历DataFrame的四种不同方法。
' iterrows '函数在遍历DataFrame时显示出最高的时间消耗。与“iterrows”函数相比,使用“itertuples”函数可以使DataFrame迭代的速度提高6倍。在字典和数组上迭代被证明是最有效的方法,使用循环提供最快的迭代时间和最佳的数据操作。
当然,在处理大型数据集时,最佳实践是矢量化。向量化上述代码将执行时间减少到0.29秒(比遍历数组快72倍)。但是使用矢量化时会增加开发的成本,所以在一些时候为了我们开发方便,可以选择一个比较快速for循环来替代矢量化。当然,如果你对矢量化非常的了解,那还是推荐继续使用。
作者:Anmol Tomar
编辑:黄继彦
关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU















 3926
3926

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









