







来源:专知
本文为论文介绍,建议阅读5分钟
在本论文中,我提出从四个维度使DLG更加实用。
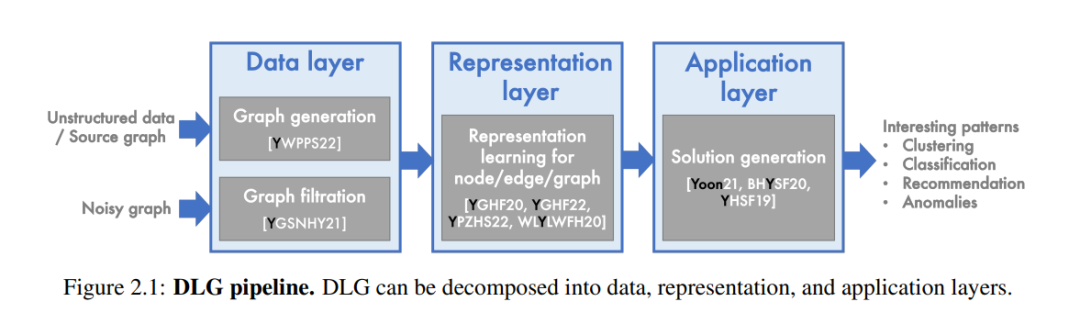
图结构无处不在,从电子商务到知识图谱,抽象出个体数据实体之间的交互。运行在图结构数据上的各种实际应用程序需要为图的每个部分——节点、边、子图和整个图——提供有效的表示,以编码其基本特征。
近年来,图上的深度学习(Deep Learning on Graphs,DLG)通过学习图表示,在各个领域取得了突破性进展,成功捕捉了图中潜在的归纳偏差。然而,这些突破性的DLG算法在应用于实际场景时,有时会面临一些局限性。首先,由于只要在存在实体交互的领域中都可以构建图,因此实际中的图往往是多样化的。因此,每一个新的应用程序都需要领域专家的参与和繁琐的超参数调优工作,以找到最优的DLG算法。其次,实际中的图的规模不断扩大,甚至达到数十亿节点,同时还伴随着未过滤的噪声。这要求在实现DLG应用之前进行冗余的预处理,例如图采样和噪声过滤。接下来,实际中的图大多是专有的,而许多DLG算法往往假设它们可以完全访问外部图,以学习其分布或提取知识,进而转移到其他图。最后,语言和视觉领域的单模态基础模型的出现,促进了多种模态的集成,导致了带有多种模态的节点和边的多模态图的形成。然而,在多模态图上进行学习,同时利用每种模态的基础模型的生成能力,仍然是DLG中的一个开放性问题。
在本论文中,我提出从四个维度使DLG更加实用:1)自动化,2)可扩展性,3)隐私性,4)多模态性。首先,我们在消息传递框架下自动化算法搜索和超参数调优。然后,我们提出对每个节点的邻域进行采样,以调节计算成本,同时自适应地过滤掉针对目标任务的噪声邻居,以应对可扩展性问题。针对隐私问题,我们重新定义了包括图生成和迁移学习在内的传统问题定义,使其意识到实际图的专有性和隐私受限的特点。最后,我提出了一种新的多模态图学习算法,该算法建立在单模态基础模型之上,并基于多模态邻居信息生成内容。
随着人类收集的数据在规模和多样性上的增加,个体元素之间的关系在规模和复杂性上呈指数级增长。通过使DLG更加可扩展、隐私认证和多模态,我们希望能够更好地处理这些关系,并对广泛的领域产生积极的影响。
http://ra.adm.cs.cmu.edu/anon/2024/abstracts/24-139.html
在计算机视觉和自然语言处理领域取得的近期成功中,现实世界数据的一个关键方面——关系信息——在AI模型中仍然未得到充分探索。传统模型主要在训练和推理过程中单独处理单个数据实体,例如一张图片或一句话。相反,许多现实世界的应用本质上涉及富含关系结构的数据,这些数据自然可以表示为图,其中节点代表数据实体,边则编码了它们之间的关系。通过理解图中每个数据实体的关系,我们能够全面了解它与其他实体的相关性或联系。例如,在电子商务中,一个产品的上下文不仅仅通过其描述来解读,还可以通过电子商务图中相邻节点的用户评论、商家信息或共同购买的产品来分析。
图上的深度学习(Deep Learning on Graphs,DLG)提出了多种深度学习方法,通过捕捉图中的潜在归纳偏差来学习节点、边、子图和图的有效表示【20,75】。DLG在多个领域取得了突破,从传统的图应用,如电子商务/社交平台中的产品/好友推荐【88,176】、社交网络中的虚假信息检测【10】、金融交易网络中的欺诈检测【156】等,到新兴的图应用,包括导航应用中的ETA预测【29】、流行病学中的疫情预测【22,112】以及生物学中的药物开发【70】。
1.1 挑战
DLG旨在通过图结构和邻域信息学习理解这个相互关联的世界,并改进对每个数据实体的理解。然而,当我们尝试在实践中实现DLG时,会面临源自现实世界图特征的诸多挑战。
多样性:由于图可以构建在任何存在实体交互的领域中,现实世界的图具有多样性,从电子商务图到知识图谱。这些多样化的图需要针对每个DLG算法寻找不同的最优超参数集。
规模:现实世界图的规模不断增加,达到数十亿或数万亿节点,同时伴随着未过滤的噪声。这要求在实现DLG应用之前进行冗余的图采样和噪声过滤。
隐私:隐私问题的兴起以及相关法律的实施限制了源自各行业的现实世界图的共享。这对DLG研究提出了前所未有的挑战,包括访问感兴趣的图数据集受限以及关于外部图可访问性的研究假设受到干扰。
多模态:语言和视觉领域的单模态基础模型的出现,催生了跨领域多种模态的集成,导致了带有多种模态的节点和边的多模态图的形成。在多模态图上进行学习,同时利用每种模态基础模型的强大生成能力,仍然是DLG中的一个开放性问题。
由于这些挑战,一些DLG研究难以将其在学术环境中展示的影响力完全传递到工业领域中新兴的图应用中。
1.2 贡献
鉴于超参数调优、可扩展性、隐私性和多模态等四个阻碍DLG广泛应用于现实世界中的挑战,我定义了新的问题,旨在解决这些挑战,并提出了可以在现实世界图上部署的实用解决方案。
自动化:为了消除重复工作并使DLG为实践者所用,我自动化了神经架构搜索(即超参数调优),并在给定的图、任务和资源预算下,找到最优的消息传递算法(第3章)。
可扩展性:我对每个节点的邻居进行采样,以调节DLG算法的计算成本。我自适应地采样对于给定任务有信息量的邻居,自动过滤掉噪声邻居(第4章)。
隐私性:我提出了新的迁移学习方法,避免依赖外部(可能是专有的)图,通过在完全自有的异构图内转移知识,从而避免访问外部图(第5章)。此外,我定义了一个新的图生成问题,该问题能够以增强隐私的方式生成遵循专有图分布的替代图,并为DLG研究多样化基准图(第6章)。
多模态:我提出了一种新的多模态图学习算法,该算法基于单模态基础模型构建,并基于多模态邻居信息生成内容。这一范式有望成为需要复杂多模态数据处理的应用(如决策、规划和推荐系统)的基础方法(第7章)。
基于这一系列工作,我们帮助DLG更容易地应用于更广泛的领域,从而为现实世界带来更大的影响。




关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU















 822
822

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









