







来源:专知
本文约3000字,建议阅读5分钟
在本综述中,我们提供了一种自上而下的审视方法,采用了一种原则性框架进行具身规划和推理,并强调了利用基础模型应对VLN挑战的当前方法和未来机会。
视觉与语言导航(VLN)近年来受到越来越多的关注,许多方法已经涌现出来以推动其发展。基础模型的显著成就已经塑造了VLN研究的挑战和提出的方法。在本综述中,我们提供了一种自上而下的审视方法,采用了一种原则性框架进行具身规划和推理,并强调了利用基础模型应对VLN挑战的当前方法和未来机会。我们希望通过深入的讨论提供有价值的资源和见解:一方面,用以标记进展里程碑,探索基础模型在该领域的机会和潜在作用;另一方面,为基础模型研究者整理VLN中的各种挑战和解决方案。

开发能够与人类及其周围环境互动的具身代理是人工智能(AI)的长期目标之一(Nguyen et al., 2021; Duan et al., 2022)。这些AI系统在实际应用中具有巨大的潜力,可以作为多功能助手在日常生活中发挥作用,如家庭机器人(Szot et al., 2021)、自动驾驶汽车(Hu et al., 2023)和个人助理(Chu et al., 2023)。一个推进这一研究方向的正式问题设置是视觉与语言导航(VLN)(Anderson et al., 2018),这是一项多模态和协作任务,要求代理根据人类指令探索三维环境,并在各种模糊情况下进行在场通信。多年来,VLN在仿真环境(Chang et al., 2017; Savva et al., 2019; Xia et al., 2018)和实际环境(Mirowski et al., 2018; Banerjee et al., 2021)中都进行了探索,产生了许多基准测试(Anderson et al., 2018; Ku et al., 2020; Krantz et al., 2020),每个基准测试都提出了稍有不同的问题表述。
近年来,基础模型(Bommasani et al., 2021)从早期的预训练模型如BERT(Kenton and Toutanova, 2019)到当代的大型语言模型(LLMs)和视觉语言模型(VLMs)(Achiam et al., 2023; Radford et al., 2021)展现出了在多模态理解、推理和跨领域泛化方面的非凡能力。这些模型在海量数据上进行了预训练,如文本、图像、音频和视频,并可以进一步适应广泛的具体应用,包括具身AI任务(Xu et al., 2024)。将这些基础模型整合到VLN任务中标志着具身AI研究的一个关键进展,表现出显著的性能提升(Chen et al., 2021b; Wang et al., 2023f; Zhou et al., 2024a)。基础模型还为VLN领域带来了新的机会,例如从多模态注意力学习和策略政策学习扩展到预训练通用的视觉和语言表征,从而实现任务规划、常识推理以及泛化到现实环境。
尽管基础模型对VLN研究产生了最近的影响,以往关于VLN的综述(Gu et al., 2022; Park and Kim, 2023; Wu et al., 2024)来自基础模型时代之前,主要关注VLN基准测试和传统方法,即缺少利用基础模型解决VLN挑战的现有方法和机会的全面概述。特别是随着LLMs的出现,据我们所知,尚未有综述讨论它们在VLN任务中的应用。此外,与以前将VLN任务视为孤立的下游任务的努力不同,本综述的目标有两个:首先,标记进展里程碑,探索基础模型在该领域的机会和潜在作用;其次,在系统框架内为基础模型研究者组织VLN中的不同挑战和解决方案。为建立这种联系,我们采用LAW框架(Hu and Shu, 2023),其中基础模型作为世界模型和代理模型的骨干。该框架提供了基础模型中推理和规划的一般景观,并与VLN的核心挑战紧密相关。
具体而言,在每一步导航中,AI代理感知视觉环境,接收来自人类的语言指令,并基于其对世界和人类的表征进行推理,以规划行动并高效完成导航任务。如图1所示,世界模型是代理理解周围外部环境以及其行动如何改变世界状态的抽象(Ha and Schmidhuber, 2018; Koh et al., 2021)。该模型是一个更广泛的代理模型的一部分,该代理模型还包含一个人类模型,该模型解释其人类伙伴的指令,从而告知代理的目标(Andreas, 2022; Ma et al., 2023)。为了回顾VLN领域不断增长的工作并理解所取得的里程碑,我们采用自上而下的方法进行综述,重点关注从三个角度出发的基本挑战:
学习一个世界模型来表示视觉环境并泛化到未见过的环境。
学习一个人类模型以有效地从基础指令中解释人类意图。
学习一个VLN代理,利用其世界和人类模型来实现语言的基础、沟通、推理和规划,使其能够按指示导航环境。
我们在图2中展示了一个分层和细粒度的分类法,基于基础模型讨论每个模型的挑战、解决方案和未来方向。为了组织本综述,我们首先简要概述该领域的背景和相关研究工作以及可用的基准测试(第2节)。我们围绕提出的方法如何解决上述三个关键挑战进行结构化审查:世界模型(第3节)、人类模型(第4节)和VLN代理(第5节)。最后,我们讨论了当前的挑战和未来的研究机会,特别是在基础模型兴起的背景下(第6节)。
VLN任务定义
一个典型的视觉与语言导航(VLN)代理在指定位置接收来自人类指令者的(一系列)语言指令。代理使用以自我为中心的视觉视角在环境中导航。通过遵循指令,代理的任务是在一系列离散视图或较低级别的动作和控制(例如,前进0.25米)上生成轨迹,以到达目的地。如果代理到达距离目的地指定距离(例如3米)以内的位置,则任务被认为成功。此外,代理可以在导航过程中与指令者交换信息,可以请求帮助或进行自由形式的语言交流。此外,人们对VLN代理集成额外任务(如操作任务(Shridhar et al., 2020)和物体检测(Qi et al., 2020b))的期望也在不断增加。
基准测试
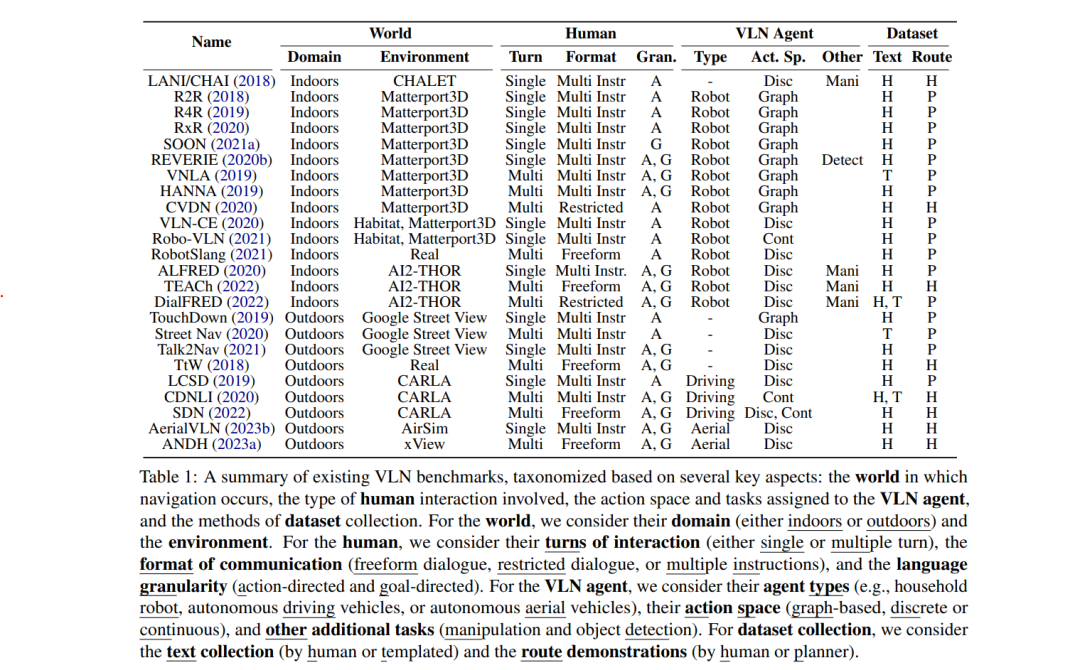
如表1所示,现有的VLN基准测试可以根据几个关键方面进行分类:(1)导航发生的世界,包括领域(室内或室外)和环境的具体情况。(2)涉及的人机交互类型,包括交互回合(单次或多次)、通信格式(自由对话、限制对话或多重指令)和语言粒度(动作导向或目标导向)。(3)VLN代理,包括其类型(如家庭机器人、自动驾驶车辆或自主飞行器)、动作空间(基于图形、离散或连续)和额外任务(操作和物体检测)。(4)数据集的收集,包括文本收集方法(人类生成或模板化)和路径演示(人类执行或规划生成)。有代表性的是,Anderson等人(2018)基于Matterport3D模拟器(Chang et al., 2017)创建了Room-to-Room(R2R)数据集,代理需要遵循精细的导航指令到达目标。Room-across-Room(RxR)(Ku et al., 2020)是一个多语言版本,包括英语、印地语和泰卢固语指令。它提供了更大的样本量,并为虚拟姿态提供了时间对齐的指令,丰富了任务的语言和空间信息。Matterport3D允许VLN代理在离散环境中操作,并依赖预定义的连接图进行导航,代理通过在相邻节点之间的传送在图上移动,被称为VLN-DE。为了使简化的设置更现实,Krantz等人(2020)、Li等人(2022c)、Irshad等人(2021)通过将离散的R2R路径转移到连续空间(Savva等人,2019)提出了连续环境中的VLN(VLN-CE)。Robo-VLN(Irshad等人,2021)通过引入在机器人环境中更现实的连续动作空间的VLN,进一步缩小了模拟到现实的差距。最近的VLN基准测试经历了几次设计变更和期望,我们在第6节中讨论这些变更。
评估指标
三种主要指标用于评估导航路径规划性能(Anderson等人,2018):(1)导航误差(NE),代理最终位置与目标位置之间最短路径距离的平均值;(2)成功率(SR),最终位置足够接近目标位置的百分比;(3)成功率加权路径长度(SPL),通过轨迹长度标准化成功率。一些其他指标用于衡量指令遵循的忠实度和预测轨迹与真实轨迹之间的一致性,例如:(4)按长度加权的覆盖得分(CLS)(Jain等人,2019);(5)归一化动态时间规整(nDTW)(Ilharco等人,2019),对偏离真实轨迹的情况进行惩罚;以及(6)按成功率加权的归一化动态时间规整(sDTW)(Ilharco等人,2019),对偏离真实轨迹的情况进行惩罚,并考虑成功率。

关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









