







来源:专知
本文约1000字,建议阅读5分钟我们提出,通过纳入新的方式整合人类输入,能够改善奖励信号。
我们如何引导人工智能体表现出我们期望的行为?引导智能系统行为的一种方式是通过奖励设计。通过指定要优化的奖励函数,我们可以利用强化学习(Reinforcement Learning, RL)使智能体从自己的经验和互动中学习。因此,在能够手动指定与预期行为良好对齐的奖励函数的环境中(例如,使用分数作为游戏的奖励),RL取得了巨大的成功。然而,随着我们逐步开发能够在复杂、多样的现实世界中学习更复杂行为的智能系统,奖励设计变得越来越困难且至关重要。为应对此挑战,我们提出,通过纳入新的方式整合人类输入,能够改善奖励信号。
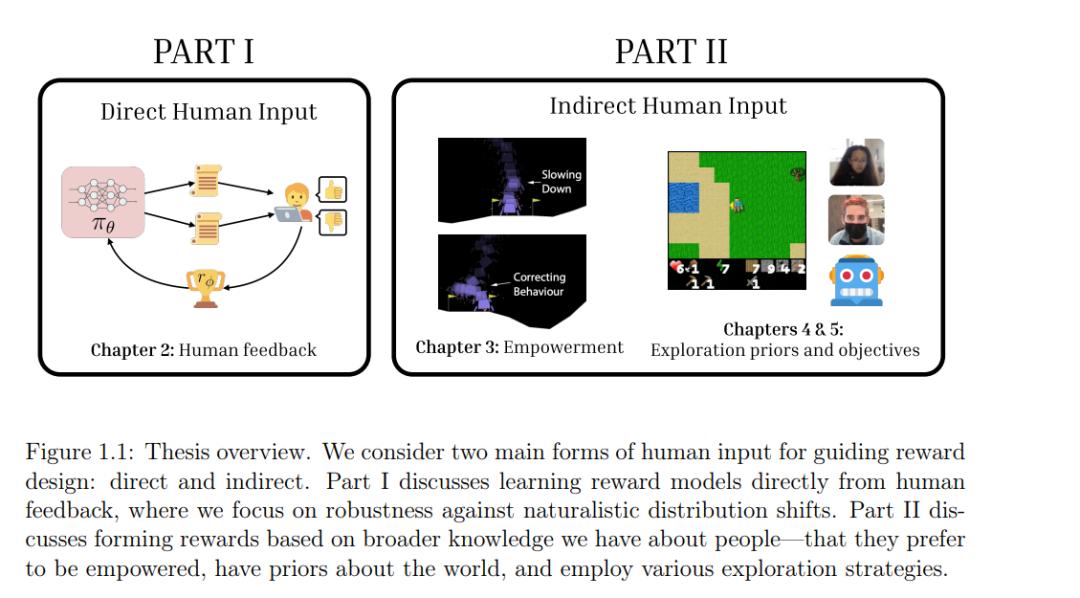
本论文包含两个主要部分:直接利用人类输入进行奖励设计,或间接使用我们对人类的普遍认知进行奖励设计。在第一部分中,我们提出了一个基于人类反馈构建鲁棒奖励模型的框架。我们提出了一种适用于大规模预训练视觉-语言模型的奖励建模方法,在视觉和语言分布转移的情况下,能够生成更具广泛适应性的多模态奖励函数。在第二部分中,我们利用关于人类的广泛知识,作为奖励设计的新型输入形式。在人类辅助场景下,我们提出使用人类赋能作为与任务无关的奖励输入。这使我们能够训练辅助智能体,避免现有目标推理方法的局限,同时还旨在保护人类的自主性。
最后,我们研究了在人工智能体中引发探索行为的情况。与以往不加区分地优化多样性以鼓励探索的工作不同,我们提出通过利用人类的先验知识和普遍的世界认知来设计内在奖励函数,从而引导更类似人类的探索行为。为了更好地理解指导人类行为的内在目标如何能为智能体设计提供借鉴,我们还比较了在人类和智能体在开放式探索场景中的行为与常用作内在奖励的信息论目标的对齐程度。最后,我们反思了奖励设计的挑战,并探讨了未来的研究方向。


关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









