








作者:金一鸣
本文约4000字,建议阅读8分钟
本文介绍优化大模型效果的大利器,从而帮助读者在实战中高效地选择技术方案来优化模型效果。上一篇文章大模型扫盲系列——大模型实用技术介绍(上)中谈到实用的大模型核心技术,这篇承接实战相关的主题,介绍优化大模型效果的大利器,从而帮助读者在实战中高效地选择技术方案来优化模型效果。
首先,在技术方面,笔者更关注如何得到一个效果更好的LLM解决方案。在去年的OpenAI的DevDay上,开放了闭门会上分享精进大模型效果的视频(https://youtu.be/ahnGLM-RC1Y?si=tNrLOHqCHnYOdMaa),从这个视频分享中,可以清晰地看到整个行业在大模型落地应用技术层面的改进方向,如图1 所示。

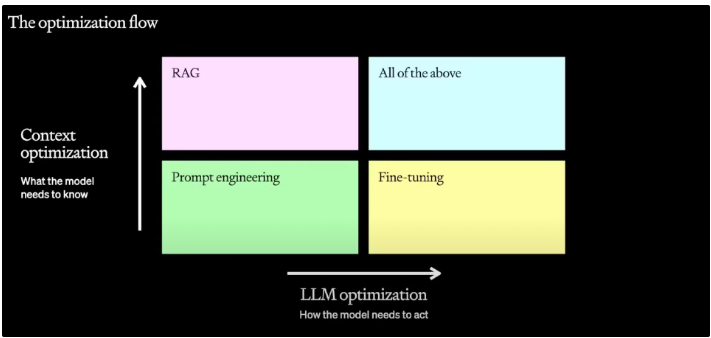
图1 大模型落地应用技术层面的改进方向
通过图1总结一下该分享的内容:
1、通过“提示工程”快速构建基础步骤,作为目标任务效果的基线。
2、优化模型效果,主要通过RAG(从上下文角度出发)以及Fine-tuning(从模型角度出发)进行优化,两种方式各有优劣,根据具体情况选择,可以任一一种或者两种都使用。
视频中可以得到一条很清晰的迭代思路:在具体场景中应用大模型解决问题时,最开始应该从Prompt Engineering入手,使用各种prompt技巧,快速迭代得到一个较好的基线效果,当出现效果瓶颈时,从错误的case入手,考虑是否需要使用RAG来引入一些外部知识进行知识补充,或者是通过指令微调(Instruction Finetuning)的方式让模型在当前任务上进行高效迭代。
另外,除了这两种方式,在优化方向上也可以从数据,强化学习(RL)角度进行迭代,LLM目前在这些方面的探索技术也有很多,后续作为优化效果的重点方向统一总结。
1. Prompt原理
视频中再一次提到了优化prompt技术的重要性,它是改进模型效果最简单也是最高效的技巧,一开始可以通过尝试利用prompt方式提升baseline效果,这种方式比finetune,RAG等要方便很多,迭代的效率也会高很多。很多人可能会好奇为什么调试提示词会对模型效果有这么大的改善,这里从prompt原理角度出发,解释一下为什么prompt会使得大模型获得更优的效果。
对于大型语言模型,无论是现在主流的Causal LM类还是prefixLM类的模型,都是通过自注意力机制(self-attention)学习输入序列的内部表示。当向模型提供一个prompt时,该prompt激活了特定的内部表示路径。已经在预训练过程中通过大量数据学习到了这些路径,并且与prompt中的词汇、结构或语境相关联。因此,一个好的prompt有助于将模型的注意力引导到与任务相关的表示上。
另外,从统计学角度来看,prompt优化本质就是最大化联合概率,模型试图最大化给定前文(prompt)条件下,生成正确下文(response)的概率。良好的prompt提供清晰、相关的上下文信息,使得模型能够更准确地估计这些条件概率,因此生成更准确、更相关的输出。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









