








作者:金一鸣
本文约5000字,建议阅读10分钟
本文介绍优化大模型效果的大利器,从而帮助读者在实战中高效地选择技术方案来优化模型效果。1. Few-shot技巧
Few-shot学习是一种机器学习方法,在这种方法中,模型可以从少量的示例(例如1到几百个)中学习特定任务或概念。但在大模型Prompt领域,这种方式准确的应该理解为In-context Learning,这是一种特定的few-shot学习形式,通常指的是在模型推理过程中通过上下文示例来引导模型理解和解决任务。模型并不会对这些示例进行再训练或微调,而是直接在推理过程中使用它们。作用方式通常是在描述任务时提供一些高质量的例子来辅助说明这个任务工作方式,比如举一个one-shot的例子:


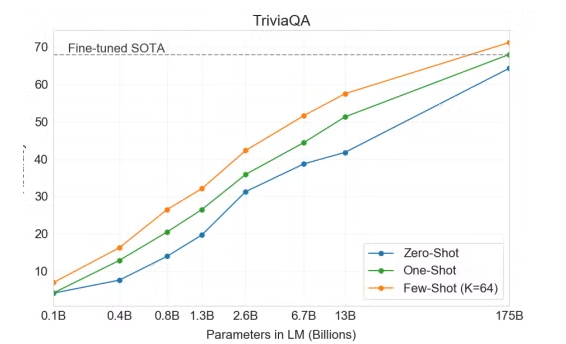
比较经典说明few-shot在大模型上效果表现好的还是OpenAI这篇Language Models are Few-Shot Learners(https://arxiv.org/pdf/2005.14165),介绍在GPT-3上few-shot带来的效果提升,下图是在其中一个数据集上的实验效果图,比较直观的说明在 TriviaQA 任务上,GPT-3 的性能随着模型规模的扩大而稳步提升,显示出语言模型在参数量增加时能够持续积累知识。相比于zero-shot设置,one-shot和few-shot设置的表现显著提升,不仅达到了SOTA 微调的开放域模型性能水平,甚至在某些情况下超越了它。在论文中其他的测试集上,这个结论也是基本成立,说明这个方法有效性还是很确定的。

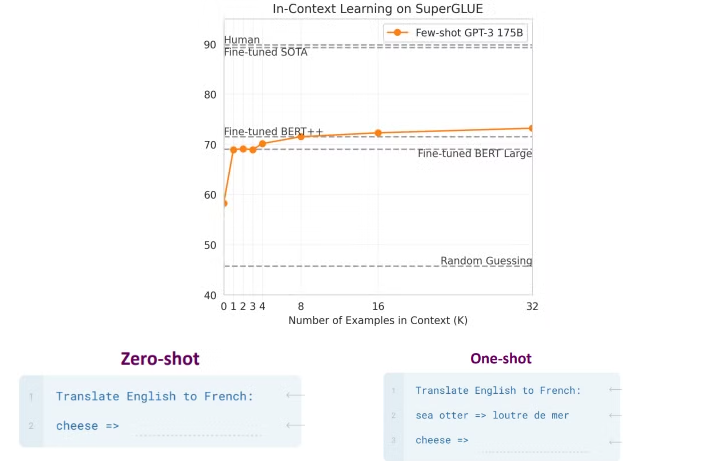
另外对于选择few-shot的数量,论文中也对比了例子数量对最后效果的影响,从图中可以看到zero-shot是最低的分数,当随着 K 不断增大时,我们发现 GPT-3 每个任务只需要不到 8 个示例,就能在整体 SuperGLUE 得分上胜过经过微调的 BERT-Large,后面例子越多甚至能超过微调的BERT++。下图分别是数据集上三种方式(zero-shot,one-shot,few-shot)的样例,可以直观的感受few-shot的使用方式。当然这里需要注意的是对于实践中的任务来说,大多数情况下不一定是例子给的越多越好,主要由任务的难度,模型的大小等因素综合决定,需要具体去实践得到比较好的效果,同时也要考虑例子的质量,包含例子与任务相关性,多样性,准确性等多个维度来使用few-shot。



去年的时候,Google就发了文章(https://arxiv.org/pdf/2303.03846)说明few shot的各种问题对整体效果的影响。首先,第一个结论是用负样本的few shot比正样本会带来一些负向影响,并且不同模型的大小对这个负向效果的感知是不一样的,越大的模型受few shot负例的影响越小。

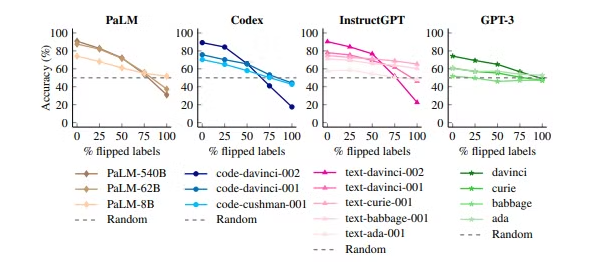
所以选择的时候尽量选择正确,与任务相关性高或者高质量的示例来作为few shot正向效果的参考。
最近一篇新的文章(https://arxiv.org/pdf/2406.15708)也得到了few shot如何选择对优化重要性的结论,并且作者强调了用自动化提示词优化(Automatic prompt optimization,APO)方式对优化指令和例子的重要性:
即使对于功能强大的指令遵循模型
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









