







来源:专知
本文约1000字,建议阅读5分钟
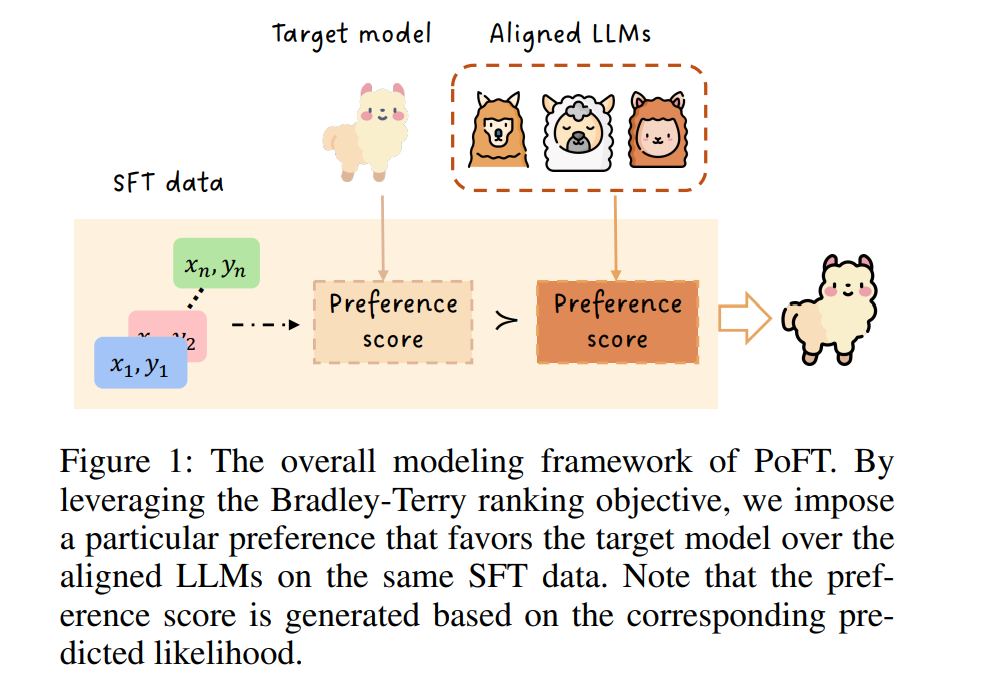
PoFT在不同的训练数据集和基础模型上,相比传统SFT基准方法表现出稳定且一致的改进。
摘要
对齐,即赋予预训练的大语言模型(LLM)遵循指令的能力,对于其在现实世界中的应用至关重要。传统的监督微调(SFT)方法将其形式化为因果语言建模,通常采用交叉熵目标,需要大量高质量的指令-响应对。然而,由于创建和维护高质量数据集的成本高昂且劳动密集,广泛使用的SFT数据集的质量无法得到保证。为了解决与SFT数据集质量相关的局限性,我们提出了一种新颖的偏好导向监督微调方法,即PoFT。其直觉是通过施加特定的偏好来提升SFT:在相同的SFT数据上,优先选择目标模型而非对齐的大语言模型。这种偏好鼓励目标模型预测出比对齐LLMs更高的概率,从而将数据质量评估信息(即对齐LLMs的预测概率)融入训练过程中。我们进行了广泛的实验,结果验证了该方法的有效性。PoFT在不同的训练数据集和基础模型上,相比传统SFT基准方法表现出稳定且一致的改进。此外,我们证明PoFT可以与现有的SFT数据过滤方法结合,进一步提升性能,并通过偏好优化程序(如DPO)进一步改进。
代码 — https://github.com/Savannah120/alignmenthandbook-PoFT/
关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









