







来源:时序人
本文约2600字,建议阅读5分钟本文研究者针对长期时间序列预测任务开发了一种基于 LSTM 的方法,即补丁分割长短期记忆网络(P-sLSTM)。传统的循环神经网络架构,如长短期记忆神经网络(LSTM),在时间序列预测任务中历来扮演着重要角色。尽管最近为自然语言处理引入的 sLSTM 通过引入指数门控和记忆混合机制,对长期序列学习有益,但其潜在的短期记忆问题成为直接在时间序列预测中应用 sLSTM 的障碍。
为了解决这一问题,来自牛津大学、宾夕法尼亚大学等学校企业合作提出了一种简单而高效的算法 P-sLSTM。该算法通过在 sLSTM 中融入补丁技术和通道独立性进行构建。这些改进显著提升了 sLSTM 在时间序列预测中的性能,取得了最先进的结果。目前,该工作已被 AAAI 2025 接收。

【论文标题】
Unlocking the Power of LSTM for Long Term Time Series Forecasting
【论文地址】
https://arxiv.org/abs/2408.10006
论文背景
时间序列预测是统计学和机器学习中的一个重要领域,广泛应用于金融、交通、气象等领域。传统的循环神经网络(RNN)及其变体 LSTM 在时间序列建模中发挥了重要作用,但存在一些局限性,例如难以捕捉长期依赖关系以及缺乏动态调整存储决策的能力。
近年来,Transformer 架构在自然语言处理(NLP)中取得了巨大成功,其引入的自注意力机制能够有效捕捉长距离依赖关系。然而,LSTM 在某些应用场景中仍具有独特优势,例如较低的时间和空间复杂度以及良好的可解释性。因此,探索如何改进 LSTM 以提升其在时间序列预测中的性能具有重要意义。
最近,一种名为 sLSTM 的扩展 LSTM 版本被引入,表明人们不仅可以修订存储决策,还可以提高其存储容量,从而在各种 NLP 任务中取得了非常有竞争力的性能。鉴于在 NLP 中先进 LSTM 的成功,那能否解锁 LSTM 在时间序列预测中的潜力呢?
在本文中,研究者通过重新提出适用于多变量时间序列预测的 sLSTM,给出了肯定的答案,从而得出了新方法 P-sLSTM。本文主要贡献如下:
解释了为什么 sLSTM 框架能够提高存储容量并修订存储决策,使其适用于时间序列预测;
严格地证明了 sLSTM 不能保证具有长记忆来捕获长期依赖性。基于之前的限制,研究者应用了 patching 技术来解决这个问题,并开发了基于 LSTM 的结构 P-sLSTM,用于时间序列预测;
在各种数据集上的广泛评估表明,P-sLSTM 的性能比原始 LSTM 提高了20%的准确性,并达到了与最先进的 SOTA 模型相当的性能。
sLSTM 架构回顾
最近提出的 sLSTM 架构通过引入指数门控和记忆混合机制,在 NLP 任务中表现出色。sLSTM 的主要改进包括:
指数门控:在遗忘门和输入门中使用指数激活函数替代传统的 sigmoid 函数,能够更灵活地控制信息流,并缓解梯度消失问题。
归一化状态:sLSTM 引入了归一化状态,并修改了隐藏状态的计算,有助于稳定长序列上的隐藏状态计算。
记忆混合机制:通过多头结构和块对角线循环权重矩阵,允许模型动态整合不同时间步的记忆,增强对长期依赖关系的捕捉能力。
尽管 sLSTM 在 NLP 任务中取得了成功,但直接将其应用于时间序列预测任务时仍面临挑战。论文通过理论分析和实验验证,发现 sLSTM 在某些情况下可能仍然存在短记忆问题,限制了其在长期时间序列预测中的性能。
P-sLSTM 模型
研究者将 sLSTM 定义为一个马尔可夫链过程,并分析了其记忆特性。通过扩展 Zhao 等人的工作,论文证明了 sLSTM 在某些条件下可能仍然具有短记忆特性,这表明仅靠 sLSTM 的改进可能无法完全解决长期依赖问题。
为了克服 sLSTM 的短记忆问题,研究者提出了 P-sLSTM 模型,图1展示了设计的 P-sLSTM 的整体结构,其中多变量时间序列数据被划分为不同的通道,这些通道共享相同的主干结构但独立处理。每个通道的单变量序列被分割成 patch,经过一个线性层处理,经过几个系统块后,另一个线性层产生最终预测。
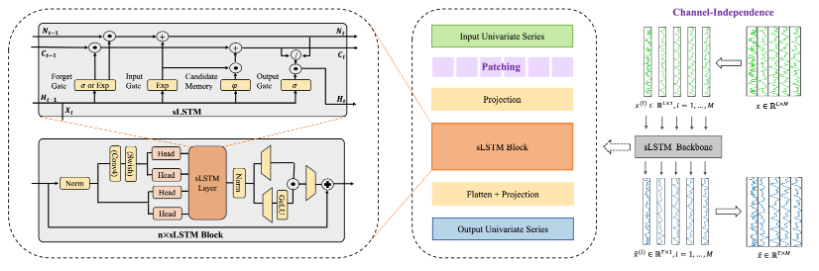
图1:P-sLSTM架构概览(左上:sLSTM结构;左下:sLSTM模块)
P-sLSTM 主要改进包括:
Patching 技术:受 Transformer 架构中 patch 成功的启发,研究者将时间序列划分为多个 patch,使模型能够分别处理这些片段并最终整合全局信息,这能够有效缓解 sLSTM 的短记忆问题。
通道独立性(Channel Independence, CI):首次将 CI 技术引入基于 RNN 的模型中,避免过拟合并提高计算效率。CI 技术允许模型独立处理多变量时间序列中的每个通道,从而更好地捕捉各通道的特征。
通过这些改进,P-sLSTM 能够更好地捕捉时间序列中的长期依赖关系,同时保持较低的时间和空间复杂度。
实验分析
01 主要预测结果
P-sLSTM 在多个数据集和预测长度设置中表现出色,获得了23次第一名和10次第二名的成绩。
P-sLSTM 在大多数情况下优于 sLSTM(90%的设置)和传统 LSTM(95%的设置),显示出其在时间序列预测中的优越性。
在 PEMS03 数据集上,P-sLSTM 的性能不如其他数据集,可能是因为该数据集非常嘈杂,而 P-sLSTM 没有包含去噪机制。
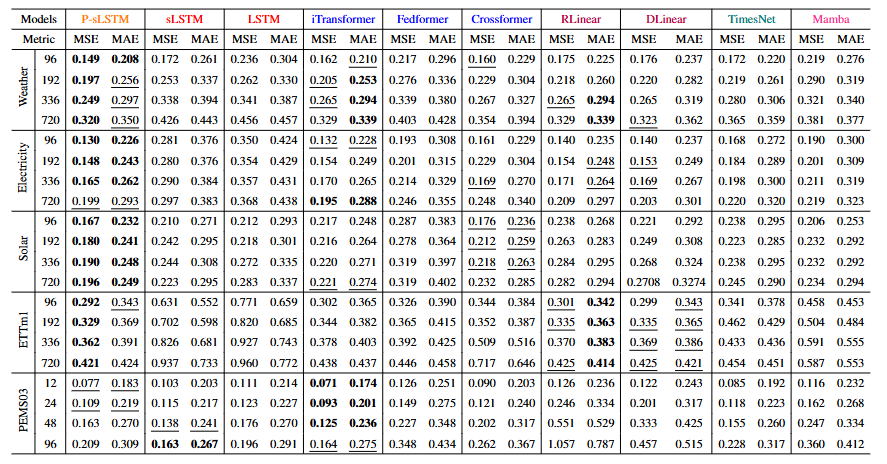
表1:展示了不同基线模型在时间序列预测任务中的量化结果
02 不同patch大小的影响
随着 patch 大小的增加,预测精度会先增加,达到一个最优解后,随着 patch 大小的进一步增加,预测精度会下降。
较小的 patch 会破坏原始时间序列的顺序信息,导致 sLSTM 无法有效处理。
较大的 patch 包含过多信息,导致过去的信息会削弱模型整合新信息的能力。
适当的 patch 大小可以显著提升模型性能,但最优的 patch 大小需要根据具体数据集进行调整。
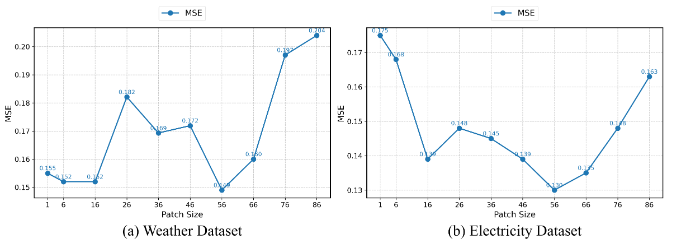
图2:不同补丁尺寸对P-sLSTM在Weather和Electricity数据集上性能的影响
03 不同回溯窗口大小的影响
与 LSTM 和 sLSTM 相比,P-sLSTM 通过 patching 机制能够更好地捕捉长期依赖关系,因此随着回溯窗口的增加,预测精度会提高。
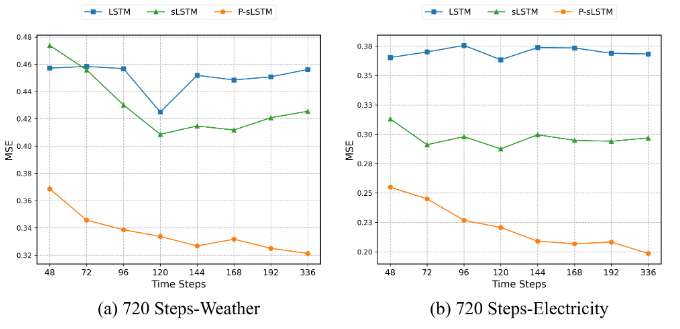
图3:在Weather和Electricity数据集上,长期预测(T=720)中,具有不同回溯窗口大小的模型的均方误差(MSE)结果
04 记忆混合的消融研究
记忆混合机制略微提升了模型性能,但提升幅度有限。记忆混合机制有助于模型选择重要的过去时间信息,但其对性能的提升作用有限。
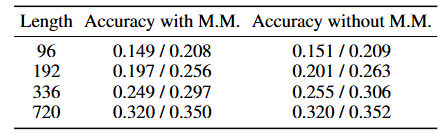
表2:在Weather数据集上关于记忆混合的消融研究
05 通道独立性的重要性
通道独立(CI)策略的 P-sLSTM 在训练误差上略高于通道混合(CM) 策略,但在验证误差和测试误差上均低于 CM 策略。CI 可以显著防止过拟合,提高模型的泛化能力。
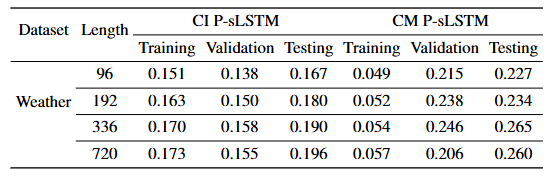
表3:在P-sLSTM上对比CI与CM策略
06 时间效率研究
P-sLSTM 具有最低的计算成本,这表明基于 RNN 的方法在时间序列预测中的潜力。

表4:P-sLSTM和iTransformer在天气和ETTm1数据集上的计算效率
总结
本文研究者针对长期时间序列预测任务开发了一种基于 LSTM 的方法,即补丁分割长短期记忆网络(P-sLSTM)。结合了自然语言处理中的 sLSTM 框架与补丁分割技术,以解决原始 LSTM 或一般 RNN 可能存在的短期记忆问题,同时采用通道独立技术来避免过拟合问题。
这项工作将激发对基于 RNN/LSTM 的模型在时间序列预测任务中的新一轮探索,并为 RNN 结构及其应用提供有价值的见解。未来的工作可能会考虑使用更复杂的补丁分割技术,以尽可能保留时间序列的原始周期性。此外,LSTM/RNN 仍存在一些已知局限性,例如它们无法进行并行计算。为了帮助模型实现并行计算,可以考虑添加 mLSTM,这是另一种 LSTM 结构,能够在时间序列问题中进行并行计算。
编辑:王菁
关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU

















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









