







本文约2200字,建议阅读8分钟
本文总结了10种关键技术,帮助您高效准确地完成数据合并任务。在数据分析工作中,我们经常需要处理来自多个来源的数据集。当合并来自20个不同地区的销售数据时,可能会发现部分列意外丢失;或在连接客户数据时,出现大量重复记录。如果您曾经因数据合并问题而感到困扰,本文将为您提供系统的解决方案。
Pandas库中的merge和join函数提供了强大的数据整合能力,但不恰当的使用可能导致数据混乱。基于对超过1000个复杂数据集的分析经验,本文总结了10种关键技术,帮助您高效准确地完成数据合并任务。

1、基本合并:数据整合的基础工具
应用场景:合并两个包含共享键的DataFrame(如订单数据与客户信息)。
merged_df=pd.merge(orders_df, customers_df, on='customer_id')技术原理:
on='customer_id'参数指定用于对齐的公共键;默认
how='inner'参数确保只保留匹配的行。
实用技巧:使用how='outer'可保留所有行并便于发现不匹配数据潜在问题:当customer_id存在重复值时,可能导致行数意外增加。建议先验证键的唯一性:
print(customers_df['customer_id'].is_unique) # 理想情况下应返回True2、左连接:保留主表完整性的操作
应用场景:需要保留左侧DataFrame的所有记录,即使部分记录在右侧表中没有匹配项(例如,保留所有客户记录,包括无订单的客户)。
left_merged=pd.merge(customers_df, orders_df, on='customer_id', how='left')技术原理:
保留左侧表的所有行,对于无匹配的记录,在来自右侧表的列中填充
NaN对于需要保持分析对象完整性的场景尤为重要
3、右连接:关注补充数据的方法
应用场景:优先保留右侧DataFrame的完整记录(例如,列出所有产品,包括未产生销售的产品)。
right_merged=pd.merge(products_df, sales_df, on='product_id', how='right')技术原理:
展示所有销售记录,包括产品目录中不存在的商品,适用于数据质量审计。
实用建议:为保持代码一致性,可考虑将DataFrame位置调换并使用左连接实现相同效果。
4、外连接:数据一致性检测工具
应用场景:识别数据集之间的不匹配记录(例如,查找没有对应订单的客户或没有对应客户的订单)。
outer_merged=pd.merge(df1, df2, on='key', how='outer', indicator=True) outer_merged['_merge'].value_counts()输出示例:
both 8000left_only 1200 right_only 500技术原理:
indicator=True参数添加一个标识列,显示每行数据的来源
概念类比:可将外连接视为维恩图的完整实现,突显两个数据集的交集与差集。
5、基于索引连接:高效的合并方式
应用场景:使用索引而非列来合并DataFrame(如时间序列数据的合并)。
joined_df=df1.join(df2, how='inner', lsuffix='_left', rsuffix='_right')技术原理:
基于索引对齐的连接操作,通常比
merge()执行效率更高;lsuffix/rsuffix参数用于解决列名冲突问题。
使用限制:当索引不具有实际业务意义(如随机生成的行号)时,应选择基于列的合并方式。
6、 多键合并:精确匹配的数据整合
应用场景:通过多个列进行合并操作(例如,同时通过name和signup_date匹配用户记录)。
multi_merged=pd.merge( users_df, logins_df, left_on=['name', 'signup_date'], right_on=['username', 'login_date'] )技术原理:
通过多列匹配减少因单列重复值导致的不准确匹配。
实施建议:数据合并前应先进行数据清洗,确保格式一致性,避免日期格式不统一(如2023-01-01与01/01/2023)导致的匹配失败。
7、数据拼接:纵向数据整合技术
应用场景:垂直堆叠具有相同列结构的DataFrame(例如,合并多个月度报表)。
combined=pd.concat([jan_df, feb_df, mar_df], axis=0, ignore_index=True)技术原理:
axis=0参数指定按行进行堆叠;ignore_index=True重置索引编号
常见问题:不一致的列顺序会导致生成包含NaN值的数据。建议使用pd.concat(..., verify_integrity=True)参数及时捕获此类问题。
8、交叉连接:全组合数据生成方法
应用场景:生成所有可能的组合(如测试每种产品在不同价格区域的组合方案)。
cross_merged=pd.merge( products_df, regions_df, how='cross' )技术原理:
生成两个DataFrame的笛卡尔积,需谨慎使用以避免数据量爆炸。
9、后缀管理:解决列名冲突的技术
应用场景:处理合并后的重名列(如区分revenue_x与revenue_y)。
merged_suffix=pd.merge( q1_df, q2_df, on='product_id', suffixes=('_q1', '_q2') )技术原理:
自定义后缀(如
_q1和_q2)明确标识列的来源DataFrame。
实用建议:使用具有业务含义的描述性后缀(如_marketing与_sales)增强数据可解释性。
10、合并验证:数据完整性保障机制
应用场景:避免一对多关系合并带来的意外结果(如重复键导致的数据异常)。
pd.merge( employees_df, departments_df, on='dept_id', validate='many_to_one' # 确保departments_df中的dept_id是唯一的 )技术原理:
validate='many_to_one'参数会在右侧DataFrame的键存在重复值时抛出错误,提供数据质量保障
验证选项:
'one_to_one':要求两侧的键都是唯一的'one_to_many':左侧键唯一,右侧键可重复'many_to_one':要求右侧键唯一,左侧键可重复
不同场景的技术选择指南
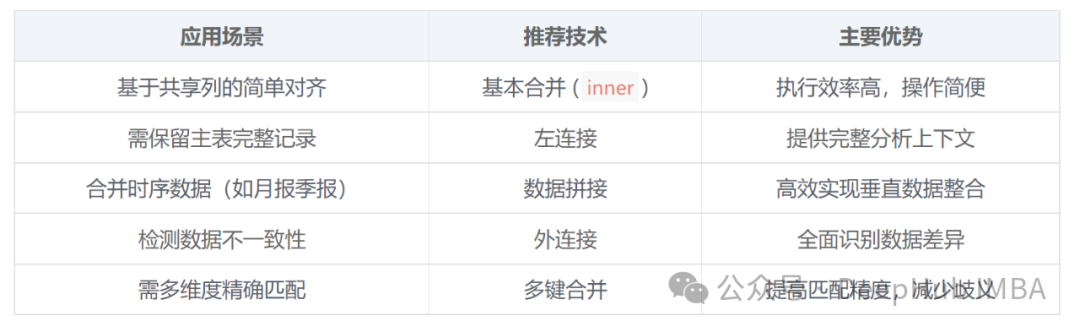
预先验证键的质量:
print(df['key_column'].nunique()) # 检测潜在的重复值处理缺失值:
df.fillna('N/A', inplace=True) # 防止因缺失值导致的合并不完整优化内存使用:在处理大型数据集前调整数据类型:
df['column'] =df['column'].astype('int32') # 将64位数据类型降为32位实践练习(可选)
验证合并质量:检查现有项目中的数据合并逻辑,应用
validate='one_to_one'进行验证。交叉连接实践:尝试合并产品与地区数据表,并通过逻辑筛选获取有价值的组合。
列名冲突处理:优化已合并DataFrame中的重名列,提高数据可解释性。
总结
在Pandas中进行数据合并操作需要精确理解数据结构、清晰掌握各种合并方法的特性,并注意验证合并结果的正确性。掌握本文介绍的技术,可以显著提高数据整合效率,减少调试时间,将更多精力投入到数据分析与洞察发现中。
关键建议:当对合并结果有疑虑时,建议使用带有validate参数和indicator=True的pd.merge()函数,这将提供额外的安全保障和问题定位能力。
编辑:黄继彦
关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









