







作者:Bety Rodriguez-Milla
翻译:和中华
校对:吴金笛
本文约2800字,建议阅读8分钟。
本文展示了当数据稀缺时,如何一步步进行分析从而得到一些见解。
[ 导读 ]本文是系列文章中的一篇,作者对滑铁卢地区的Freedom of Information Requests数据集进行探索分析,展示了在实践中拿到一批数据时(尤其像本文中的情况,数据很稀缺时),该如何一步步进行分析从而得到一些见解。作者的同事也对该数据集使用其他方法进行了分析,建议对NLP感兴趣的读者也一并阅读,将大有裨益。
最近我碰到了滑铁卢地区的Open Data项目,连同它的Freedom of Information Requests数据集。我的同事Scott Jones已经在一系列文章中使用机器学习(ML)技术对其进行了分析。由于数据不足,ML表现不佳。虽然Scott做了在这种情况下应该做的事情,即寻找更多数据。尽管数据很稀缺,但我仍然很好奇这些数据还能告诉我什么。毕竟数据总是有价值的。
在进入这段8分钟的阅读旅程之前,我想说你可以在Github上找到Jupyter notebook里的所有代码和对这些数据的更多见解,由于内容太多,文章里无法一一介绍。如果你不想阅读notebook,可以在下面链接的相关文件中找到全部图形结果。
Github相关链接:
https://github.com/brodriguezmilla/foir
相关文件:
https://github.com/brodriguezmilla/foir/blob/master/foir_all_figures.pdf
接下来,我向你介绍其中几个分析的要点。
了解数据
我们使用pandas库来实现这一步,以下是Open Data中的文件之一:

1999年的Freedom of Information Requests文件样本
我们有18个文件,从1999年至2016年每年一个,总共有576个请求(Requests),令人惊讶地是全部都有相同的六列。我们将只使用三个主要列,来源(Source),请求摘要(Summary_of_Request)和决策(Decision)。
Source。 这是发出请求的实体,即请求者。 通过查看多年来的信息,能够将其合并为“Business”,“Individual”,“Individual by Agent”,“Media”,“Business by Agent”和“Individual for dependant”。
Summary_of_Request。 包含已由记录员编辑过的请求。
Decision。合并后的类别包括:“All information disclosed”,“Information disclosed in part”,“No records exist”,“Request withdrawn”,“Partly non-existent”,“No information disclosed”,“Transferred”,“Abandoned”, “Correction refused”,“Correction granted”,“No additional records exist”。
这些列的相互之间关系如何?
描述性统计和探索性数据分析
在本节中,我们将重点关注Source和Decision列。稍后我们将使用一些NLP工具分析这些请求。以下是数据的分布:
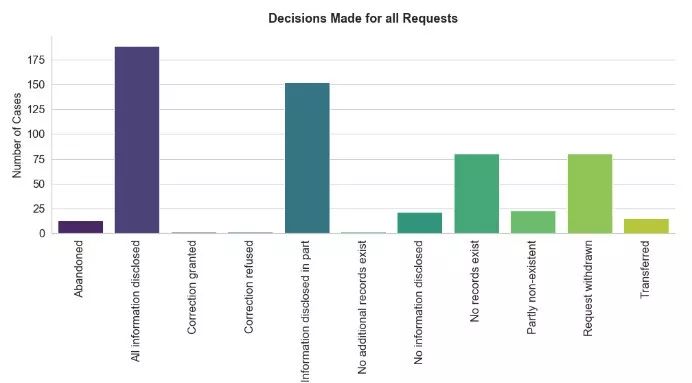
大约60%的请求是“All information disclosed”或“Information disclosed in part”。 至少有七种类型的决策少于25个实例,其中一个最重要的决策是“No information disclosed”。 因此,我们不仅数据量有限,而且还存在不平衡的情况。 对于机器学习来说这都不太好。
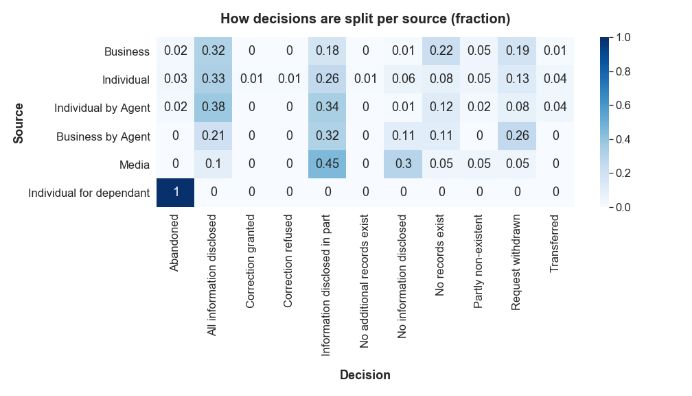
通过另一种数据视图,即Source 与 Decision的透视表,我们看到大多数请求都是由“Business”,“Individual”和“Individual by Agent”发起的。
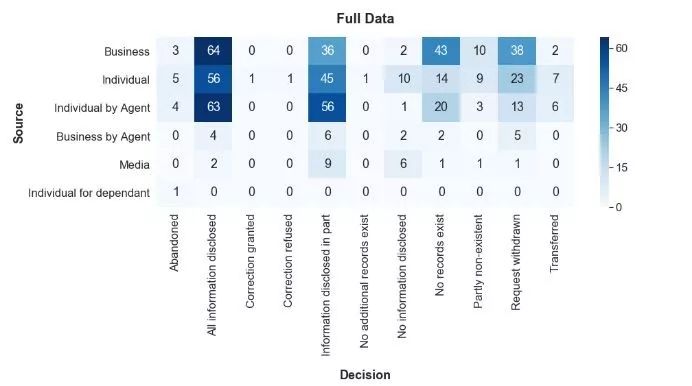
将每个来源的数字进行处理,使每一行加起来等于1,我们看到主要的三个来源表现良好,因为“All information disclosed”每个都超过30%,“Information disclosed in part”则增加了18%至34%,甚至更多。 两者相加在50%以上。此外,“Individual by Agent”的成功率高于“Individual”。几乎没有请求的“Media”表现不佳,只有10%的请求被决策为“All information disclosed”。
自然语言处理(NLP)
现在我们继续分析Summary_of_Requests列。为此,我们转投自然语言处理库,例如NLTK和spaCy,以及scikit-learn的帮助。
从广义上讲,在分析任何文本之前,需要做的步骤其实很少(参见Susan Li的帖子):
https://towardsdatascience.com/topic-modelling-in-python-with-nltk-and-gensim-4ef03213cd21
对文本进行分词:将文本分解为单个特殊实体/单词,即token。
删除任何不需要的字符,比如回车换行和标点符号,像' - ','...','“'等。
删除网址或将其替换为某个单词,例如“URL”。
删除网名或用某个单词替换“@”,例如“screen_name”。
删除单词的大小写。
删除少于等于n个字符的单词。在本例中,n = 3。
删除停用词,即某种语言中含义不大的词。这些词可能无助于对我们的文本进行分类。例如“a”,“the”,“and”等词。但并没有一个通用的停用词列表。
词形还原,它是将单词的变种形式归并在一起的过程,这样它们就可以作为单个词项进行分析,就可以通过单词的词目(lemma)或词典形式来识别。
因此,在编写了处理函数之后,我们可以对文本进行转换:
def prepare_text_tlc(the_text):
text = clean_text(the_text)
text = parse_text(text)
tokens = tokenize(text)
tokens = replace_urls(tokens)
tokens = replace_screen_names(tokens)
tokens = lemmatize_tokens(tokens)
tokens = remove_short_strings(tokens, 3)
tokens = remove_stop_words(tokens)
tokens = remove_symbols(tokens)
return tokens由于我们会持续处理此文本,因此我们将预处理过的文本作为新列“Edited_Summary”添加到dataframe中。

N元语法(N-grams)和词云
还能如何分析和可视化我们的文本呢?作为第一步,我们可以找到最常用的单词和短语,即我们可以获得一元语法(单个tokens)和 n元语法(n-tokens组)及它们在文本中的频率。
def display_top_grams(gram, gram_length, num_grams):
gram_counter = Counter(gram)
if gram_length is 1:
name = 'unigrams'
elif gram_length is 2:
name = 'bigrams'
elif gram_length is 3:
name = 'trigrams'
else:
name = str(gram_length) + '-grams'
print("No. of unique {0}: {1}".format(name, len(gram_counter)))
for grams in gram_counter.most_common(num_grams):
print(grams)
return None
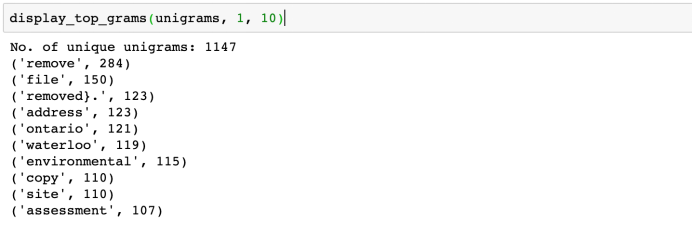
所以对于我们的一元语法:
并使用WordCloud:

那为什么“remove”这个词如此突出?事实证明,出于隐私原因,原始请求中写入的所有姓名,日期和位置都已删除,并在Open Data的文件中被替换为“{location removed}”或“{date removed}”等短语。这种替换共有30多种变体。 使用正则表达式(regEx)来清理文本,我们得到了一个更好的词云。这一次,我们也加入了二元语法。

看一下上面的词云和三元语法:

我们看到有一些常见的短语,例如“ontario works”,“environmental site”,“grand river transit”,“rabies control”,“public health inspection”和“food bear illness”(亦如'food borne illness ' – 还记得我们之前曾把tokens进行了词形还原)。 那么,这些短语在我们的文本中有多常见?包含这些短语的请求信息是否影响请求被批准的可能性?事实证明,46%的数据是那些类型的请求,这些短语没有一个得到“No information disclosed”的决策,并且有明显的趋势:

例如,“rabies control”约有95%披露了全部或部分信息,而5%被转移了。
对Summary_of_Request和Edited_Summary 列统计
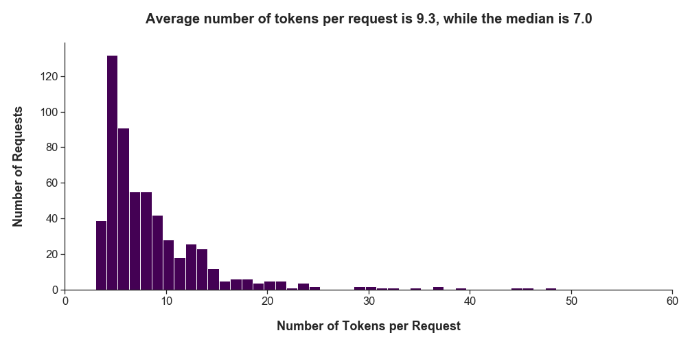
我们已经知道现有数据量是有限的,但到底多有限呢?好吧,只有7个请求超过100个单词,而分词后只剩1个。平均每个请求有21个单词,而中位数为15,而分词后平均为9个单词,中位数为7。

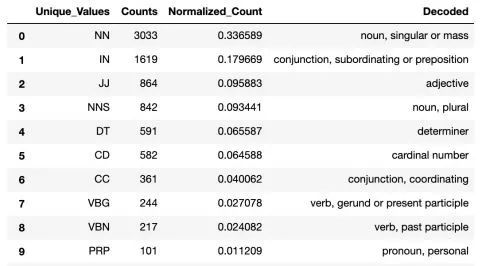
词性(POS)标记
在这里,我们使用spaCy来识别该文本是如何由名词,动词,形容词等组成的。 我们还使用函数spacy.explain()来找出这些标记的含义。
full_text_nlp = nlp(full_text) # spaCy nlp()
tags = []
for token in full_text_nlp:
tags.append(token.tag_)
tags_df = pd.DataFrame(data=tags, columns=['Tags'])
print("Number of unique tag values:\
{0}".format(tags_df['Tags'].nunique()))
print("Total number of words: {0}".format(len(tags_df['Tags'])))
# Make a dataframe out of unique values
tags_value_counts = tags_df['Tags'].value_counts(dropna=True,
sort=True)
tags_value_counts_df = tags_value_counts.rename_axis(
'Unique_Values').reset_index(name='Counts')
# And normalizing the count values
tags_value_counts_df['Normalized_Count'] = tags_value_counts_df['Counts'] / len(tags_df['Tags'])
uv_decoded = []
for val in tags_value_counts_df['Unique_Values']:
uv_decoded.append(spacy.explain(val))
tags_value_counts_df['Decoded'] = uv_decoded
tags_value_counts_df.head(10)
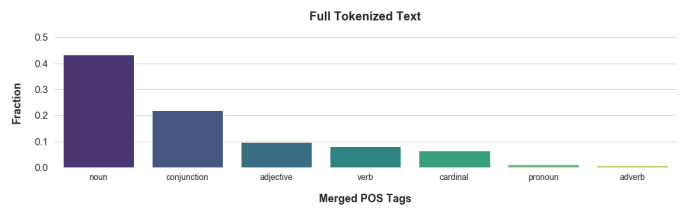
同时将类别合并,例如“名词,单数或大量”和“名词,复数”,以形成更通用的版本,以下是这些请求的组成方式:
使用scikit-learn,Bokeh和t-SNE进行主题建模
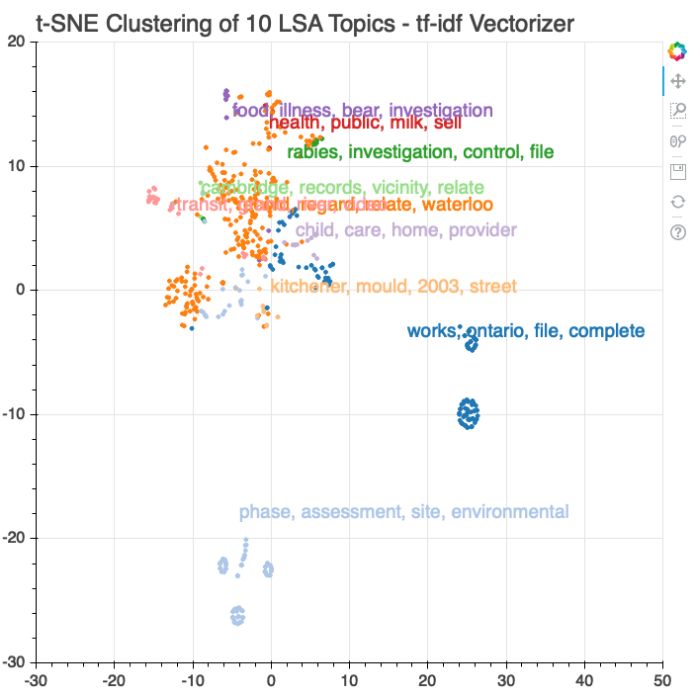
在notebook中,我们使用不同的主题建模技术,包括scikit-learn的隐含狄利克雷分布(LDA)函数,潜在语义分析(LSA),并且用 CountVectorizer()和TfidfVectorizer()做对比,gensim的LDA,使用t-SNE用于降维,Bokeh和pyLDAvis用于可视化。 我们不会在此处附上完整代码,所以鼓励你去亲自查看完整的notebook。鉴于我们数据的局限性,所有工具都还表现得不错。下图是一个亮点:
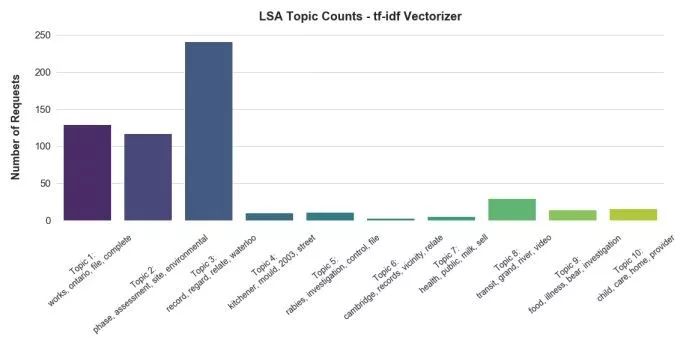
几乎所有最常见的短语都在主题中出现了。正如预期的那样,一些主题是明确的,例如“ontario works”或“environmental site”,而其他聚类则不然。
机器学习
我们已经知道机器学习效果不会很好,但鉴于这是一个学习练习,我们仍然要试一下。在notebook中,我们比较了三种不同情况下的八种不同机器学习模型。我们无法按原样比较完整数据,因为某些情况只有极少数实例。例如,只有一个请求被“Correction granted”,因此当我们训练模型时,该情况将要么在训练集中,要么在测试集中。只有一个案例并不能提供一个良好的基础。我们的选择很少:
我们可以删除少于15个实例的请求,称之为“Over-15”。
我们将全部决议分成三个基本类别:
-
All information disclosed(加上“Correction granted”。)
Information disclosed in part(加上“Partly non-existent”。)
No information disclosed(加上' Transferred',' No records exist',' Correction refused',' No additional records exist',' Withdrawn'和' Abandoned'。)这会使我们的数据集更平衡。
我们可以删掉少于15个实例的请求,并且删掉没有实际结果的决策,即撤回或抛弃的情况,称之为“Independent”。
以下是结果:
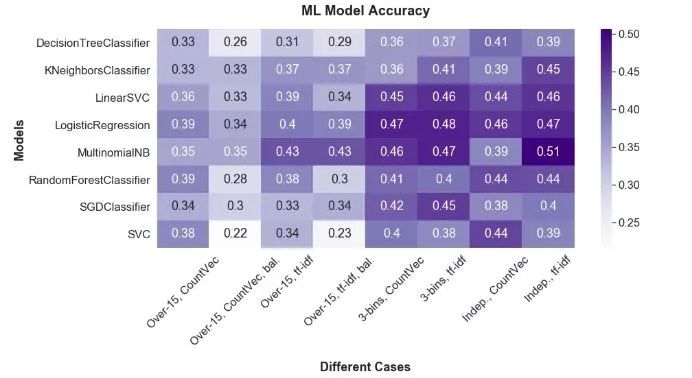
总体而言,逻辑回归和多项式朴素贝叶斯分类器结合tf-idf给出了更好的结果。 对我们的类别进行分箱(binning)似乎是最合乎逻辑的方法。
可以在以下Github链接中找到代码和完整的结果:
Github链接:
https://github.com/brodriguezmilla/foi
原文标题:
When Data is Scarce… Ways to Extract Valuable Insights
原文链接:
https://towardsdatascience.com/when-data-is-scarce-ways-to-extract-valuable-insights-f73eca652009
译者简介

和中华,留德软件工程硕士。由于对机器学习感兴趣,硕士论文选择了利用遗传算法思想改进传统kmeans。目前在杭州进行大数据相关实践。加入数据派THU希望为IT同行们尽自己一份绵薄之力,也希望结交许多志趣相投的小伙伴。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:datapi),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。


点击“阅读原文”拥抱组织















 537
537











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









