







作者:王佳鑫
本文约4800字,建议阅读9分钟介绍一篇收录在《IEEE TRANSACTIONS ON INFORMATION THEORY》的论文。本文介绍的是一篇收录在《IEEE TRANSACTIONS ON INFORMATION THEORY》的“Structural Information and Dynamical Complexity of Networks”论文。基于这个理论,近一两年(2023年-2024年)的时候涌现了较多该理论的应用文章,并发表在各类计算机顶会如AAAI, ICML,WWW,KDD等。由于研究背景、理论及其数学推导、证明等相对复杂和繁琐,我们将分成多期进行分开讲解。


摘要:
网络的结构信息和动态复杂性是一个重要的研究领域。1953年,香农提出了结构信息的量化问题来分析通信系统,这成为了信息科学和计算机科学领域持续时间最长的巨大挑战之一。为了解决这个问题,北京航空航天大学的李安胜老师团队提出了结构信息的第一个度量,即K维结构信息(或结构熵)。给定图G,定义G的K维结构信息HK(G)为确定可通过图中随机游走访问的节点的高维代码所需的最小总位数。这个度量不仅提供了完全检测自然或真实结构的原理,还是网络动态复杂性的第一个度量,满足许多基本属性如可加性、局部性、鲁棒性等。研究还建立了网络一维和二维结构信息的基本定理,并提出通过最小化K维结构熵来近似图的K维结构信息的算法。这一原理被发现可以用于检测现实世界网络中的自然或真实结构,为从噪声数据中发现知识提供了基础。
一、研究背景
首先介绍大家熟知的信息熵概念。信息熵(Information Entropy)由克劳德·香农在信息理论中提出,用来量化信息的不确定性和复杂性。信息熵的定义如下:

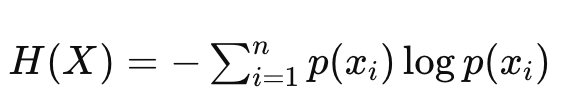
其中H(X)是随机变量X的熵。p(xi)是随机变量X取值xi的概率。n是随机变量X的可能取值的数量。信息熵衡量的是在给定概率分布下,系统的不确定性程度。熵值越高,系统的不确定性越大,信息越丰富。
21世纪的到来见证了生物数据、网络数据、地形图和医疗数据等新型数据的涌现。这些新兴数据的分析和其中蕴含的规律与知识的发掘,已然成为当代计算机科学面临的重大挑战。在这一新任务面前,香农对信息的经典定义明显显得力不从心,亟需一种新的结构信息度量方法。具体来说,假设有一个结构化数据G = (V, E),它是一个图。按照香农信息熵的传统分析方法,我们只能通过以下三个步骤来获取G的信息熵:首先,我们需要定义G的一个分布p,比如度数分布或距离分布;其次,计算p的香农信息,即I = H(p);最后,我们得到的I被视为G的信息。然而,这种方法存在明显缺陷。第一步实际上是通过去除G的结构,将其简化为非结构化向量p,这可能会丢失G最有价值的属性。第三步得到的仅仅是一个数字I,而这个单一数值难以反映G的丰富特性。关键问题在于:我们能从这个香农信息I中推断出G的哪些本质属性?这个问题的重要性不言而喻,因为图是计算机科学中最普遍、最直观的数学结构。可惜的是,香农的信息理论无法支持分析图这类结构化数据的工作。同理,其他基于香农熵的各种度量方法也难以有效支持结构化数据的分析。更糟糕的是,当面对大规模网络数据和非结构化大数据时,这种局限性变得更加明显。
在深入研究网络复杂性时,我们不得不指出一个关键问题:现有的各种图熵和图模型概念大多局限于网络复杂性的静态度量。然而,现实世界的网络远非静止不变。每时每刻,数以百万计的交互、通信和操作在网络中发生,使得网络呈现出动态发展的特性。因此,网络的复杂性在很大程度上体现为其动态复杂性,即定量衡量网络交互、通信、运行和演化的复杂程度。这种动态特性在现实世界的网络中尤为明显。我们可以大致将这些网络分为两类:第一类是由自然和社会规律演化而来的网络,如引文网络、社交网络和蛋白质相互作用网络;第二类是工程领域中人为创建的网络,如计算机网络、通信网络和服务网络。无论哪一类,识别网络的自然结构都是理解网络动力学的核心。面对这一复杂局面,我们不禁要问:如何准确衡量网络的动态复杂性?这个问题不仅是对现有理论的挑战,更是推动网络科学发展的关键。
综合以上所有问题,我们需要建立一个全新的理论框架。这就引出了我们的核心研究目标:建立网络结构信息和动态复杂性的度量方法。这个新的理论框架,我们称之为结构熵理论,旨在捕捉网络的本质特性,不仅考虑其静态结构,更重要的是量化其动态演化过程。通过结构熵理论,我们希望能够更深入地理解网络的内在机制,为复杂系统的分析和预测提供新的视角和工具。
在接下来的内容中,我们将详细阐述这一理论的基本原理、数学模型以及在实际应用中的潜力。这一理论不仅有望解决上述挑战,还可能为网络科学、信息理论和复杂系统研究开辟新的方向。
二、结构熵理论及其数学原理
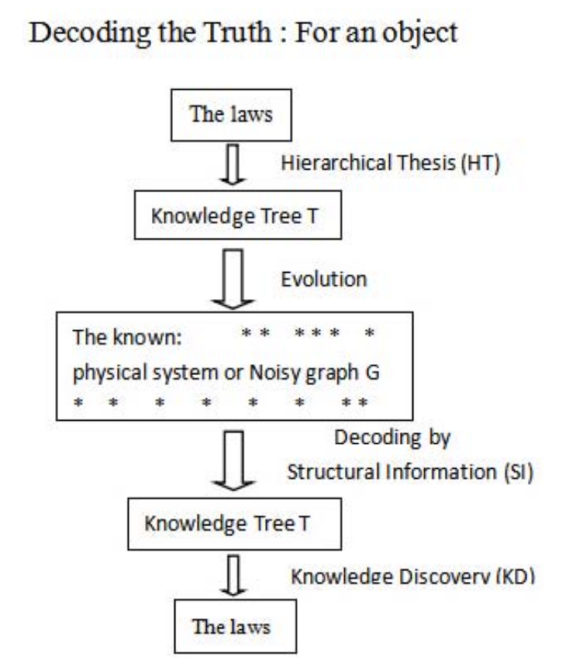
结构熵的整体思想(如下图):首先假设图G中存在一个由内在规律生成的自然层次结构T。这个结构反映了数据的本质特征和组织方式。其次,我们的目标是通过一种巧妙的方法来识别这个基本结构T。具体而言,我们试图排除G中存在的最大量的非确定性、不确定性和噪声,从而揭示出数据的核心架构。最后,我们定义图G的结构信息H,使得H能够精确地确定这个基本结构T。这种度量方法一旦建立,就能让我们有效地解码真实知识,而不受噪声数据的干扰。这个由结构信息H确定的层次结构T,我们称之为G的"知识树"或"编码树"。它不仅反映了数据的内在组织,还为我们提供了一种新的视角来理解和分析复杂网络。这种方法的核心在于生成最优的编码树来计算结构熵。通过这种方式,我们可以有效地压缩信息,去除冗余和噪声,揭示数据的多层次结构,捕捉到可能被传统方法忽视的微妙关系和模式。接下来我们先开始讲解网络一维和二维结构信息的基本定理。

连通无向图的一维结构信息:设 G = (V, E) 是一个具有 n 个节点和 m 条边的无向连通图。对于每个节点 i ∈ {1, 2, ..., n},令 di 表示节点 i 在图 G 中的度数,并令 pi = di/(2m)。那么,图 G 中随机游走的平稳分布由概率向量 p = (p1, p2, ..., pn) 描述。我们将 G 的一维结构信息或定位熵定义如下:

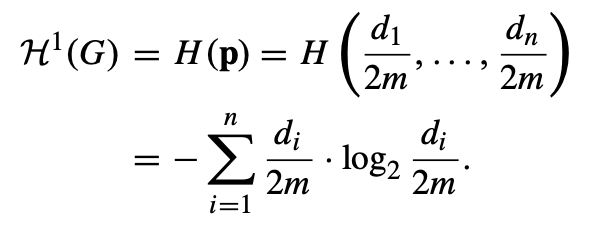
这个定义基于图的度分布和Shannon熵函数。pi = di/(2m)表示随机游走时停留在节点i的概率,这是由节点的度数与总边数的关系决定的。H1(G)实际上是计算了这个概率分布的Shannon熵。这个熵值反映了图结构的复杂性,如果图是非常规则的(如所有节点度数相同),熵值会较低,如果图的度分布很不均匀,熵值会较高。这个度量提供了一种方法来量化图的整体结构特性,特别是从随机游走的角度来看节点的"重要性"或"可达性"。
实际例子:




总边数  (每条边计为1)
(每条边计为1)




连通加权图的一维结构信息:设 G = (V, E) 是一个具有 n 个节点、m 条边的连通加权图,其权重函数为 w。我们定义 G 的一维结构信息或定位熵如下:

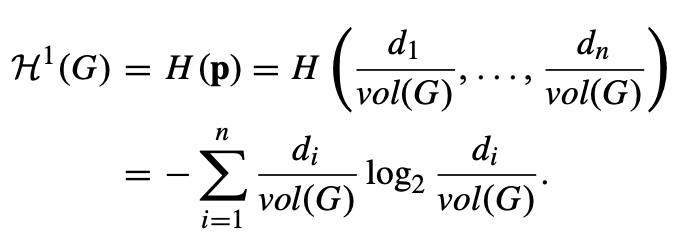
du是节点u的加权度,N(u) 是 u 的邻居集合,vol(U) = ∑(u∈U) du是节点子集 U 的体积,vol(G) = ∑(v∈V) dv 是整个图 G 的体积。pu = du/vol(G) 是随机游走中访问节点u的概率。
连通有向图的一维结构信息:给定一个连通有向图 G = (V, E),其中 n = |V| 是节点数,m 是有向边的数量。对于任意节点 v ∈ V,我们用dvin 和 dvout分别表示 v 在 G 中的入度和出度。我们定义G的一维结构信息或定位熵如下:

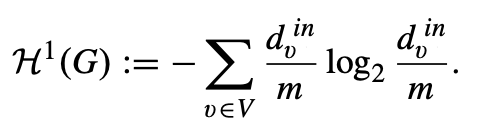
非连通无向图的一维结构信息:给定一个无向图 G = (V, E),(1)如果 E = ∅(即图中没有边),则定义 H1(G) = 0;(2)否则,假设 G1, G2, ..., GL 是 G 的所有连通分量的诱导子图。那么我们定义 G 的定位熵为所有 Gi 的定位熵的加权平均值。即

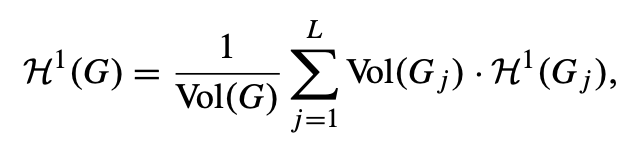
考虑到现实世界中的许多网络都具有复杂的社区结构,仅仅使用一维结构信息可能无法充分捕捉这种复杂性。因此,我们需要一个更精细的度量方法来描述网络的层级结构和模块化特性。这就引出了二维结构信息的概念。二维结构信息的定义考虑了网络的分区结构。假设我们有一个连通的无向图 G = (V, E),以及一个将节点集 V 划分为若干社区或模块的分区 P = {X1, X2, ..., XL}。我们的目标是定义一个度量,既能捕捉每个社区内部的结构特征,又能反映社区之间的连接模式。
连通无向图的二维结构信息:给定一个无向连通图 G = (V, E),假设 P = {X₁, X₂, ..., Xₗ} 是 V 的一个分区。我们定义由 P 给出的 G 的结构信息如下:

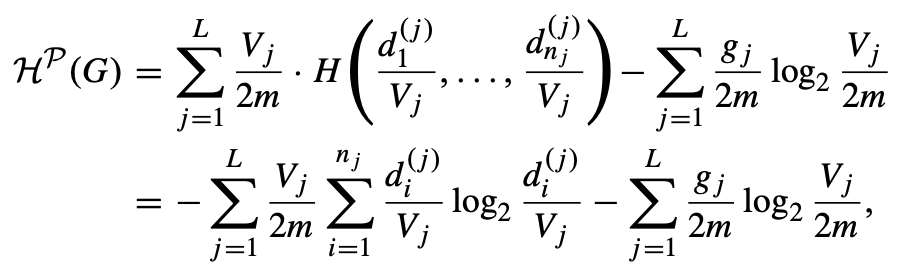
其中,L是分区P中的模块数,nⱼ 是模块 Xⱼ 中的节点数,di(j) 是 Xⱼ 中第 i 个节点的度,Vⱼ 是模块 Xⱼ 的体积(即 Xⱼ 中所有节点度的总和),gⱼ 是恰好一个端点在模块 Xⱼ 中的边的数量。这个定义提供了一种量化网络结构的方法,特别是考虑了网络的模块化结构。公式中的第一项表示模块内部的信息,而第二项则代表模块之间的信息。这种方法可以用于分析复杂网络的组织结构,特别是在社区检测和网络分析中非常有用。
连通加权图的二维结构信息:设 G = (V, E) 是一个有 n 个节点、m 条边的加权图,其权重函数为 w。假设 P = {X₁, X₂, ..., Xₗ} 是 V 的一个分区。我们定义由 P 给出的 G 的结构信息如下:

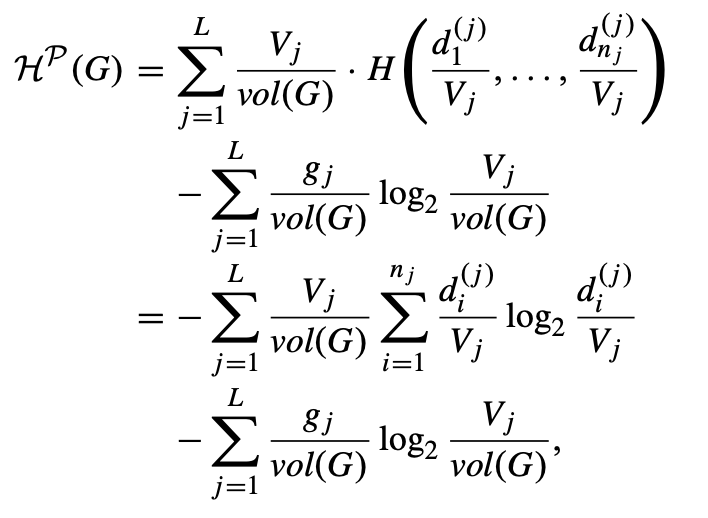
其中L 是分区 P 中的模块数,nⱼ 是模块 Xⱼ 中的节点数,d_i^(j) 是 Xⱼ 中第 i 个节点的度,Vⱼ 是模块 Xⱼ 的体积,gⱼ 是恰好一个端点在模块 Xⱼ 中的边的权重之和,vol(G) 是整个图 G 的体积(所有边权重的总和),这个定义扩展了前面的概念,适用于加权网络。主要区别在于:使用 vol(G) 代替了 2m,这反映了加权图的总体积。Vⱼ 现在代表模块 Xⱼ 的加权体积,而不仅仅是度数和。gⱼ 现在是跨模块边的权重和,而不是简单的边计数。这个公式由两部分组成:第一项捕捉了模块内部的信息结构,第二项表示模块间的信息。
连通有向图的二维结构信息:给定一个有向连通图 G = (V, E) 和 G 的一个分区 P = {V₁, ..., Vₗ},我们定义 G 由 P 给出的二维结构信息如下:

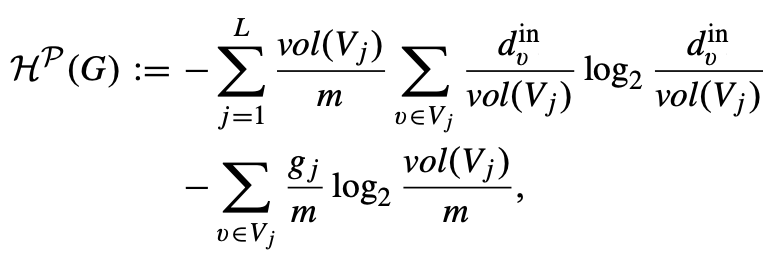
其中L 是分区中的模块数,vol(Vⱼ) 是模块 Vⱼ 的体积(即该模块中所有节点的入度之和),dvin 是节点 v 的入度,gⱼ 是从模块 Vⱼ 到其他模块的边数,这个定义扩展了之前的概念,使其适用于有向图:它使用入度而不是总度来定义节点和模块的"大小"。
体积现在基于入度,这反映了信息流入节点或模块的方式。公式的第一项捕捉了模块内部的信息结构,考虑了每个节点相对于其所在模块的"重要性"。第二项表示模块间的信息流动,gⱼ 现在特指从一个模块流出到其他模块的边。
总而言之,对于连通图,设 G = (V, E) 是一个连通图。我们定义 G 的二维结构信息,其中 P 遍历 G 的所有可能分区。

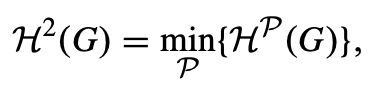
H²(G) 被定义为所有可能分区 P 的 HP(G) 的最小值。这意味着我们在寻找能最好地描述图结构的分区方式。
非连通无向图的一维结构信息:给定一个图 G,假设 G₁, G₂, ..., Gₗ 是 G 的所有连通分量的诱导子图。那么我们定义 G 的二维结构信息为所有子图 Gᵢ 的二维结构熵的加权平均值。即:

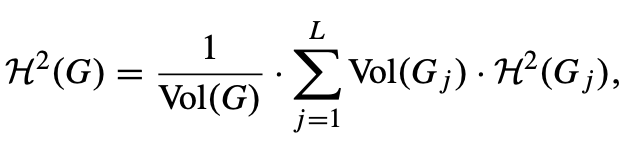
其中 Vol(G) 是 G 的体积,对每个 j,Vol(Gⱼ) 是 Gⱼ 的体积。对于非连通图,我们将其分解为连通分量,然后计算每个连通分量的二维结构信息。整个图的二维结构信息是各连通分量的二维结构信息的加权平均值,权重是各分量的体积。定义考虑了特殊情况:当一个连通分量只有一个孤立节点时,其二维结构信息被定义为0。这是通过极限 lim{p→0} -p log₂ p = 0 来实现的。对于完全没有边的图(即所有节点都是孤立的),其二维结构信息被定义为0。
归一化二维结构信息:对于任何图 G = (V, E),我们将 G 的归一化二维结构信息定义如下:

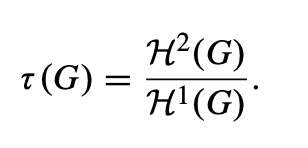
其中τ(G) 表示归一化的二维结构信息,H²(G) 可能表示二维结构信息,H¹(G) 可能表示一维结构信息。这个比率通过将二维结构信息除以一维结构信息来实现归一化。
总结:
一维结构信息:
关注点:主要考虑节点的度分布和整体连接模式。
编码方式:每个节点用单一的代码表示。
随机游走:基于整个图的平稳分布。
适用性:适合分析整体网络结构,不考虑社区或模块结构。
计算复杂度:相对简单,主要依赖于节点度的分布。
二维结构信息:
关注点:同时考虑节点在局部社区中的位置和社区之间的关系。
编码方式:每个节点用两个代码表示(社区代码和节点在社区内的代码)。
随机游走:考虑社区内部和社区之间的游走概率。
适用性:特别适合分析具有明显社区结构的网络。
计算复杂度:较高,需要考虑社区划分和社区间连接。
这两种方法的主要区别在于,一维结构信息提供了网络整体复杂性的一个全局视角,而二维结构信息则更深入地探索了网络的层级结构和模块化特性。
由于篇幅的限制,后一篇我们将接着详细讲述如何最小化高维(K维)结构熵来近似图的K维结构信息的算法,以及在各大顶会中的应用(如图表示学习、图神经网络、社区检测、聚类优化、角色识别等任务)。
参考文献:
[1] Li A, Pan Y. Structural information and dynamical complexity of networks[J]. IEEE Transactions on Information Theory, 2016, 62(6): 3290-3339.
编辑:于腾凯
校对:林亦霖
作者简介
王佳鑫,南京大学信息管理学院博士生。
数据派研究部介绍
数据派研究部成立于2017年初,以兴趣为核心划分多个组别,各组既遵循研究部整体的知识分享和实践项目规划,又各具特色:
算法模型组:积极组队参加kaggle等比赛,原创手把手教系列文章;
调研分析组:通过专访等方式调研大数据的应用,探索数据产品之美;
系统平台组:追踪大数据&人工智能系统平台技术前沿,对话专家;
自然语言处理组:重于实践,积极参加比赛及策划各类文本分析项目;
制造业大数据组:秉工业强国之梦,产学研政结合,挖掘数据价值;
数据可视化组:将信息与艺术融合,探索数据之美,学用可视化讲故事;
网络爬虫组:爬取网络信息,配合其他各组开发创意项目。
点击文末“阅读原文”,报名数据派研究部志愿者,总有一组适合你~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派THUID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
未经许可的转载以及改编者,我们将依法追究其法律责任。
关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU
点击“阅读原文”拥抱组织

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









