









人在看东西的时候,时刻关注的一定是当前正在看的这样东西的某一部分。也即,当我们目光移到别处时,注意力会随着目光移动而转移。这意味着,人注意到某个目标或某个场景时,该目标内部以及该场景内每一处空间位置上的注意力分布是不一样的。
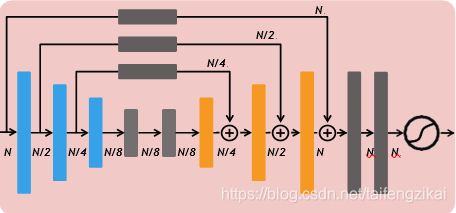
注意力模型本质上是对目标数据进行加权变化。注意力模型的结构受到视觉注意力发展的启发,已成为神经网络中的一种重要概念并在很多应用领域展开了研究。[1]尝试了注意力机制在三维点云领域的应用。使用注意力模型的目的是从点云中识别出信息量最大的点,将它们的特征用于网络预测决策。注意力模型的结构构建在自下而上/自上而下的前馈网络结构中,注意力模型可以用于图1编码器-解码器框架。对于图像,自下而上的前馈过程收集图像的全局信息,而自上而下的过程将全局和本地信息与跳过连接相结合。在以点云为输入的网络中,信息点的特征是在自下而上的步骤中学习的。然后,这些学习的特征将添加到自上而下的步骤中的点。来自注意力模型的输出特征图被用作注意力掩模。
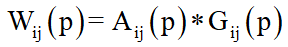
其中,i的范围是N,j是通道的标签。 A (P)表示注意力掩码, G(P)表示点特征图。
从注意力的作用角度出发,我们就可以从两个角度来分类:1)种类:空间注意力和时间注意力;2)分为Soft Attention和Hard Attention。Soft Attention是所有的数据都会注意,都会计算出相应的注意力权值,不会设置筛选条件。Hard Attention会在生成注意力权重后筛选掉一部分不符合条件的注意力,让它的注意力权值为0,即可以理解为不再注意这些不符合条件的部分。以上举例的方式为空间注意力的Soft Attention,对标准卷积的关于空间点云的特征使用注意力掩码加权。标准卷积的权重是由每个点邻居的空间位置确定,经过注意力模块加权的卷积网络会屏蔽点云交界处的其他类别,从而着重于该点本身。
请各位关注公众号。更多的文章可以关注公众号查看。















 928
928











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









