










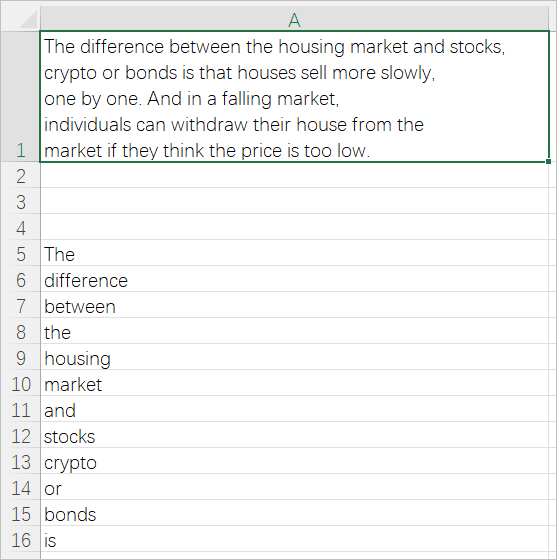
实例需求:一段多行英文保存在A1单元格,现需要拆分出其中的单词,依次写入A5开始的第一列单元格中。
上一篇博客使用VBA的Split方式实现了单词拆分,由于涉及标点符号等特殊字符,其实并不完美实现,例如:如果文本中单词左侧可能出现引号,那么需要继续扩充代码进行判断。
无需质疑正则是文本处理的王者,下面来看一下正则的实现方法。
【示例代码】
Sub demo2()
txt = [a1]
Range("A5:A10000").ClearContents
rNum = 5
With CreateObject("vbscript.regexp")
.Global = True
.IgnoreCase = True
.Pattern = "[A-Z]+"
Set mths = .Execute(txt)
End With
For i = 0 To mths.Count - 1
Cells(rNum, 1) = mths(i)
rNum = rNum + 1
Next
End Sub
【代码解析】
第2行代码读取A1单元格的内容。
第3行代码清空保存结果的单元格区域。
第4行代码设置保存位置行号。
第5行代码创建正则对象。
第6行代码设置全局替换。
第7行代码设置忽略大小写。
第8行代码设置匹配模式。
第9行代码执行正则匹配。
第11~14行代码循环处理每个单词,写入相应的单元格。
第13行代码行号加一。
请注意如果需要处理类似于He's包含单引号的单词,那么需要进一步优化正则匹配模式子付串。















 1088
1088











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









