










思想:将读取的数据当做数据库中的数据表,读取的数据放置到数据内存中临时存储,以SQL语句对数据进行筛选,得出想要的数据内容。
数据情况
筛选V2和V3两列中,元素的重复次数超过2次以上的数据,其中2和3的重复次数超过3次,需要筛选出来。

筛选数据R语言程序
library(sqldf)
data <- read.csv("data.csv")
head(data)
zdata <- sqldf("select * from data t where (select count(1) from data where V2 = t.V2 and V3 = t.V3)>2")
print(zdata)
方法一: 使用的SQL语句为:
select * from data t where (select count(1) from data where V2=t.V2 and V3=t.V3)>2
得到晒选的效果如下所示:

方法二:提取查询

v1=c(1,21,5,5,8,8)
v2=c(2,5,2,8,2,2)
v3=c(3,6,3,9,3,3)
v4=c(4,7,3,4,7,4)
data=data.frame(v1,v2,v3,v4)
head(data)
data
v
2
v
5
=
p
a
s
t
e
(
d
a
t
a
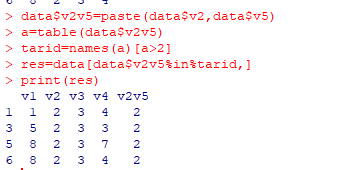
v2v5=paste(data
v2v5=paste(datav2,data
v
5
)
a
=
t
a
b
l
e
(
d
a
t
a
v5) a=table(data
v5)a=table(datav2v5)
tarid=names(a)[a>2]
res=data[data$v2v5%in%tarid,]
print(res)
方法三:条件筛选subset
a1 <- c("M","b","b","c")
b1 <- c(1,2,3,4)
da <- cbind(a1,b1)
da <- as.data.frame(da)
print(da)
mz <- subset(da,a1=='b'&b1==2)
print(mz)

方法四:which条件查询
a1 <- c("M","b","b","c")
b1 <- c(1,2,3,4)
da <- cbind(a1,b1)
da <- as.data.frame(da)
print(da)
zda<-da[which(a1 == 'b'),]
print(zda)

案例一:门店营业额业务数据筛选判断
找出历史门店中累计营业额有25天的日营业额大于3的订单数量门店。
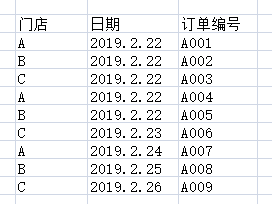
1.对一天中不同的门店的订单数量进行统计。找出每一天中不同门店的订单数量
install.packages("sqldf")
library(sqldf)
AA=read.csv("C:\\Users\\Administrator\\Desktop\\data.csv")
str(AA)
data1=sqldf("select 门店,日期,count(1) as 当日订单数 from AA group by 日期,门店")
2.对每一天中,不同门店的订单数量进行判断,找出每天门店的订单数量大于三的门店。
data2=sqldf("select 门店,日期,count(1) as 当日订单数 from AA group by 日期,门店 having 当日订单数>=3")
3.对每天门店数量大于3的门店进行统计,找出连续一个月中,每天门店数量大于3的门店,在一个月中的营业额次数累计大于等于25天的门店。
data3=sqldf("select 门店,count(1) as 月订单数量大于3的天数 from (select 门店,日期,count(1) as 当日订单数 from AA group by 日期,门店 having 当日订单数>=3) group by 门店 having 月订单数量大于3的天数>=25")
案例二: 数据筛选合并
原始数据如下:
key time
a 1月
a 1月
a 2月
b 1月
b 1月
b 1月
合并数据如下:
key time count
a 1月 2
a 2月 1
b 1月 3
实现代码如下:
key=c("a","a","a","b","b","b")
time=c("1月","1月","2月","1月","1月","1月")
data=cbind(key,time)
data=as.data.frame(data)
data
library(sqldf)
zdata=sqldf("select key,time,count(1) from data group by key,time")
print(zdata)

案例三:提取指定内容数据
提取数据框中的a1列数据包含内容为b的所有数据。
a1=c("M","b","b","c")
b1=c(1,2,3,4)
da=cbind(a1,b1)
da=as.data.frame(da)
print(da)
m=da[da$a1=='b',]
print(m)

案例四:R语言对两列中不重复元素数据进行计数
数据情况:
slon是经度,slat是维度,找出以两列中非重复数据累计出现的次数,(即不同的位置的个数,即统计出不同位置下(slon,slat)出现的次数)。

统计出a,b对应出现过多少次,1,2出现次数,2,3出现过多少次,等等
方法如下:
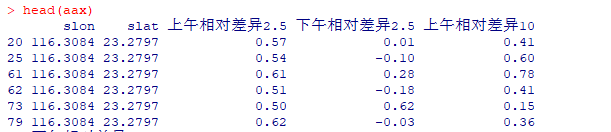
统计不同的(a,b)出现次数,对a和b进行合并,对a&b进行计数,即得到不同的(a,b)出现次数的结果值,如下所示:
aax$freq <- paste(aax$slon,aax$slat,sep=',')
table(aax$freq)
统计效果如下所示:

不同位置数据统计详细过程方法如下
原始数据展示如下,统计slon和slat
aax=dat1
print(aax)
运行得到结果如下:
两列数据合并成一列,合并slon和slat,生成新的一列freq
aax$freq <- paste(aax$slon,aax$slat,sep=',') ## 两列数据合并成一列
head(aax)
运行得到结果如下:

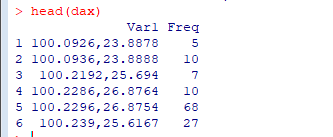
table统计新生成的一列,并将统计结果转换为数据框形式展示
dax=as.data.frame(table(aax$freq))
head(dax)
运行得到结果如下:
对统计的结果Var1变量进行拆分成两列,还原slat和slon,展示统计结果
re <- strsplit(as.character(dax$Var1),",")
for(i in 1:dim(dax)[1])
{
dax$slon[i] <- re[[i]][1]
dax$slat[i] <- re[[i]][2]
}
head(dax)
运行得到结果如下:
















 987
987











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









