








🧩 新所得库 - 自研 YOLOv8 模型失败复盘:别让 SoftmaxBiFPN 把你炸飞!
👨💻 作者:夏驰和徐策
📌 项目背景:毕业设计《基于深度学习的道路行人检测系统的设计与实现》
🎯 本篇目标:记录一次 YOLOv8 + BiFPN + CBAM 自研结构的失败调试全过程,帮助未来的你少走弯路。
🔍 背景
在毕业设计中,我决定将 YOLOv8 的默认 Neck 结构替换为自研的 SoftmaxBiFPNLayer,同时加入 CBAM 模块提升注意力机制,希望通过 结构优化 提升小目标检测性能。
但正如所有工程实践中最有价值的部分——这一次我们失败了,然后修复了它。
🚨 第一次失败的错误栈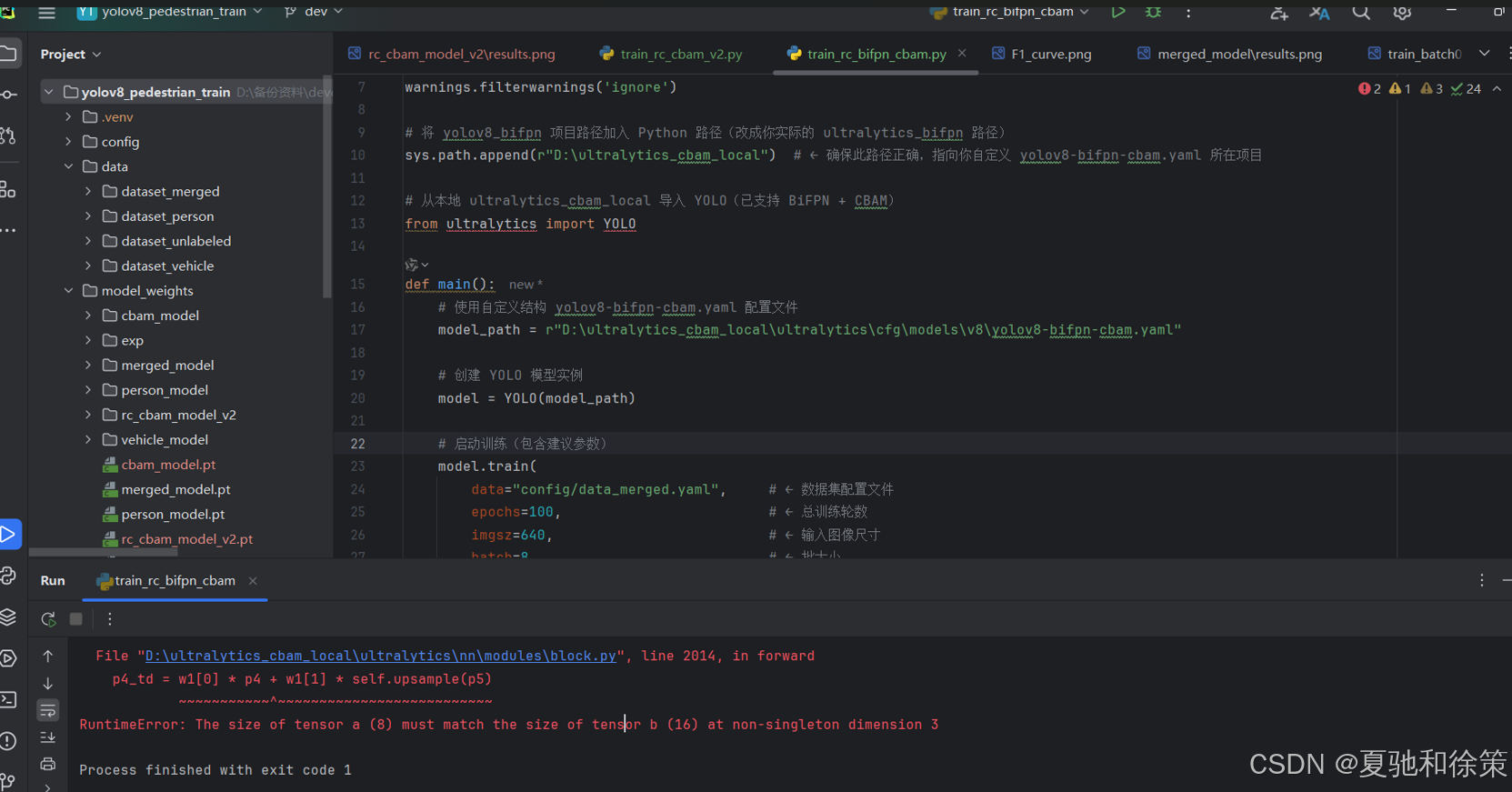
启动训练后报错如下:
RuntimeError: The size of tensor a (8) must match the size of tensor b (16) at non-singleton dimension 3
定位到:
p4_td = w1[0] * p4 + w1[1] * self.upsample(p5)
🧠 问题分析
问题的本质在于:我们在 forward 返回了多个输出(p3_out, p4_td, p5_out),但 YOLOv8 的 Head 只接受一个输入(类似 SPPF)。
而原始 .yaml 中定义:
- [[6, 8, 9], 1, SoftmaxBiFPNLayer, [256]]
这一层只能输出一个 Tensor,否则会在 Head 拼接时直接爆炸。
✅ 解决方案
我们采用了两步式修复:
1. YAML 优化:明确传入 3 个输入 → 输出一个 Tensor
# SoftmaxBiFPNLayer 融合 P4(6) P5(8) SPPF(9),统一通道为 256
- [[6, 8, 9], 1, SoftmaxBiFPNLayer, [256]]
注意:[6,8,9] 是 P4, P5, SPPF(stride 16, 32, 32)
2. 修改 SoftmaxBiFPNLayer:仅返回 p5_out
# 原:
return p3_out, p4_td, p5_out
# 修改后:
return p5_out # ✅ 保持和官方 SPPF 结构一致
✅ 成功运行
训练脚本顺利执行,验证了结构正确性:
✅ 模型训练完成,最优权重已保存为:model_weights/rc_bifpn_cbam_model.pt
🧱 总结:踩过的 4 个坑
| 编号 | 坑点 | 描述 | 修复方式 |
|---|---|---|---|
| P1 | 输出张量数量不一致 | 自定义模块输出了多个 Tensor,而 Head 只支持单输入 | return p5_out |
| P2 | 参数传入不统一 | SoftmaxBiFPNLayer 参数未标准化为 [in_chs, out_ch] | 重写 task.py 的 parse |
| P3 | 通道数不对齐 | CBAM 输入通道与上层输出不一致,报错 fallback kernel_size | 确保 CBAM 输入是上层 out_ch |
| P4 | 忘记开发者模式打包 | 改了源码但没 pip install -e .,训练的其实是旧模型 | 使用本地路径 + sys.path.append() |
✨ 彩蛋:如何让自定义模块更官方?
我们写的 SoftmaxBiFPNLayer 具备以下特征:
-
使用
Conv()和make_divisible()保留 Ultralytics 风格; -
所有结构封装为独立模块,可扩展成 repeat;
-
输出 shape 保持与官方 Neck 一致,无需额外修改 Head。
这样不仅稳定,也利于后续你把结构变种成 BiFPN_CBAM_Stacked、BiFPNLite、BiFPN_P2Support 等多个版本。
📦 附录
文件结构推荐
ultralytics_cbam_local/
├── ultralytics/
│ ├── nn/
│ │ ├── modules/
│ │ │ └── bifpn_softmax.py ← 放置 SoftmaxBiFPNLayer 的位置
│ ├── cfg/
│ │ └── models/
│ │ └── v8/
│ │ └── yolov8_bifpn_cbam.yaml
📌 结语
你不一定要造火箭,但如果你真的要造,那就要从一颗螺丝钉开始。
自研结构从来不是一次就通的,而是靠一次次失败支撑起的强大模型。
愿你把踩过的坑,铺成未来的路。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











