








📘 动手学深度学习 - 14.3 目标检测与边界框(Object Detection & Bounding Boxes)
🧠 一、目标检测是什么?
在之前章节中我们讲过 图像分类:输入一张图片,输出一个类别。但现实中图像往往不止一个对象,例如:
-
一张图片中同时有猫、狗和人;
-
无人驾驶中一帧图像里包含车、行人、红绿灯。
👉 所以我们需要的不只是识别是什么对象,还需要知道在图像的什么位置。
这就是 目标检测(Object Detection) 的核心任务:
“识别出图像中所有感兴趣的对象,并预测每个对象的位置和类别。”
✅ 理论理解:
图像分类只关心“图是什么”,但现实世界更复杂,我们关心多个对象以及它们的位置——这就是目标检测的核心。
💼 大厂/科研实战理解:
-
在 自动驾驶企业(如特斯拉/小鹏/百度Apollo) 中,目标检测模型实时运行在车载端,必须精准地检测行人、车辆、交通标志,并实时输出位置信息(bounding box)。
-
在 AI安防系统(如海康/商汤) 中,摄像头获取视频流,目标检测用于识别入侵者、火焰、危险物等,bounding box 是下游分析(跟踪、报警、联动系统)的关键输入。
-
在 学术研究 中,目标检测是 COCO、VOC、OpenImages 等多目标图像数据集的核心任务,精度(mAP)、推理速度(FPS)都由 bounding box 决定性能指标。
🎯 二、边界框(Bounding Boxes)
📦 1. 什么是边界框?
边界框是矩形区域,通常用四个数字描述一个目标的位置。有两种常见表示方法:
| 表示法 | 含义 |
|---|---|
| (x1, y1, x2, y2) | 左上角和右下角的坐标 |
| (cx, cy, w, h) | 中心点坐标 + 宽高 |
🔁 2. 转换函数实现(PyTorch)
def box_corner_to_center(boxes):
"""(x1, y1, x2, y2) → (cx, cy, w, h)"""
x1, y1, x2, y2 = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]
cx = (x1 + x2) / 2
cy = (y1 + y2) / 2
w = x2 - x1
h = y2 - y1
return torch.stack((cx, cy, w, h), axis=-1)
def box_center_to_corner(boxes):
"""(cx, cy, w, h) → (x1, y1, x2, y2)"""
cx, cy, w, h = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]
x1 = cx - 0.5 * w
y1 = cy - 0.5 * h
x2 = cx + 0.5 * w
y2 = cy + 0.5 * h
return torch.stack((x1, y1, x2, y2), axis=-1)
✅ 理论理解:
-
两种常见的边界框表示方式:
-
(x1, y1, x2, y2):用于图像坐标空间,利于可视化; -
(cx, cy, w, h):用于深度模型回归,便于 Anchor 匹配。
-
💼 实战理解(企业/科研):
| 场景 | 工程意义 |
|---|---|
📦 x1y1x2y2 | COCO/VOC 标注格式;图像可视化框的绘制格式 |
🧠 cxcywh | YOLO、SSD、RetinaNet、DETR等模型内部预测格式,尤其与 anchor/base box 对齐计算 loss |
| 🔄 转换过程 | 标注格式转换、推理后处理、部署到不同设备(如 TensorRT、OpenVINO)中必须统一格式 |
| 🧪 自动评测 | 所有自动指标如 IoU、mAP 等都依赖边界框的精确表达 |
💡 实际部署中,你在数据流/模块流中会遇到的典型操作:
# 模型输出的中心格式 → 显示用的角点格式
pred_box_xyxy = box_center_to_corner(pred_box_cxcywh)
# 标注数据格式转换
label_box_cxcywh = box_corner_to_center(label_box_xyxy)
📌 box_corner_to_center / box_center_to_corner 实用函数
✅ 理论理解:
两个函数用于格式之间的互相转换,是目标检测数据流、模型 I/O 的基础。
💼 实战理解:
| 使用位置 | 工程/科研应用 |
|---|---|
| 🔍 模型后处理 | 将模型输出框从 (cx, cy, w, h) → (x1, y1, x2, y2),用于绘图、推理输出 |
| 📁 标注预处理 | 将 VOC/COCO 标注格式统一转为 YOLO 训练需要的中心格式 |
| 📦 自动标注工具 | 用于将手动标注后的角点框自动转换为中心格式输入模型训练 |
| ⚙️ 框回归损失 | SmoothL1Loss/GIoU/DIoU 等依赖一致格式计算偏移量 |
企业级平台一般会统一封装为 bbox_utils.py 模块,并集成如下函数:
def convert_bbox_format(bbox, src_format='xyxy', tgt_format='cxcywh'):
...
🐶🐱 三、实战:标注狗和猫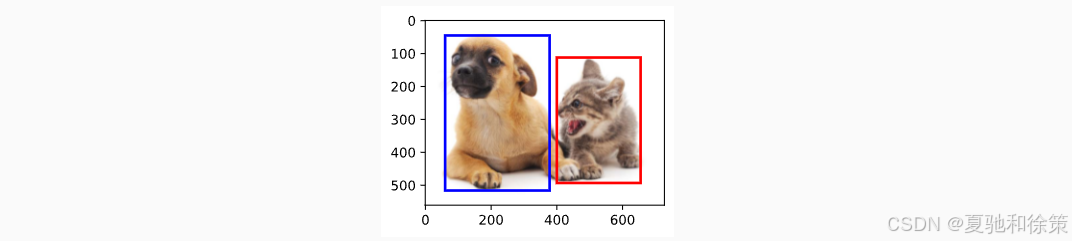
🖼️ 加载图像
img = d2l.plt.imread('../img/catdog.jpg')
d2l.plt.imshow(img)
📍 设置边界框坐标
dog_bbox = [60.0, 45.0, 378.0, 516.0]
cat_bbox = [400.0, 112.0, 655.0, 493.0]
✅ 验证边界框转换是否正确
boxes = torch.tensor([dog_bbox, cat_bbox])
assert torch.all(box_center_to_corner(box_corner_to_center(boxes)) == boxes)
🖌️ 绘图辅助函数:把边界框转为 matplotlib 可画格式
def bbox_to_rect(bbox, color):
return d2l.plt.Rectangle(
xy=(bbox[0], bbox[1]),
width=bbox[2] - bbox[0],
height=bbox[3] - bbox[1],
fill=False,
edgecolor=color,
linewidth=2)
🖼️ 可视化边界框
fig = d2l.plt.imshow(img)
fig.axes.add_patch(bbox_to_rect(dog_bbox, 'blue'))
fig.axes.add_patch(bbox_to_rect(cat_bbox, 'red'))
📌 狗猫图像加载 + 标注框测试
✅ 理论理解:
通过一个静态图像手动定义边界框,检验转换函数正确性和绘图工具是否工作。
💼 实战理解:
-
在大厂内部/科研项目初期,为验证模型预测效果,常手动采集样本并测试绘制逻辑是否正确。
-
用于训练前的数据 sanity check(数据清洗阶段),或 debug 阶段排查模型“框漂移/错误”。
🧠 真实应用中的衍生场景:
-
标注系统的前端预览功能(如 CVAT、LabelMe) → 显示的是角点框;
-
模型调试时,预测输出框需实时显示在网页/可视化面板上;
-
生成自动报告时(如工业 AI 质检),需要自动画框+显示类别+置信度;
-
用户可点击框调整坐标 → 需支持双向格式转换。
📌 bbox_to_rect 可视化工具函数
✅ 理论理解:
将 (x1, y1, x2, y2) 格式框转为 Matplotlib 格式用于绘制矩形框。
💼 实战理解:
-
在科研评测图中标注 GT 与预测框,图像可视化展示实验结果;
-
工业产品中用于调试系统:检测模型是否“打偏”,是否框得过大/过小;
-
用于训练日志自动生成(如 TensorBoard / WandB),展示训练过程中的预测图像。
💡 延伸:
-
在企业项目中会进一步包装成带类别文字、颜色映射、透明度的绘图工具:
draw_bbox(image, bbox, label="person", confidence=0.94, color="blue")
📌 四、小结(Summary)
-
📦 目标检测 = 图像分类 + 定位对象(使用边界框);
-
🔁 使用
box_corner_to_center和box_center_to_corner可以实现两种边界框形式的自由转换; -
🖼️ 使用
bbox_to_rect将框转换为 matplotlib 可画区域; -
✅ 在猫狗图像上成功框出了两个对象。
✅ 理论总结:
-
边界框用于目标检测中定位对象;
-
学会掌握两种边界框形式之间的转换;
-
为后续的预测、标注、IoU计算打基础。
💼 实战总结(工程落地场景):
| 应用模块 | 如何使用边界框 |
|---|---|
| 模型训练 | 损失函数依赖框中心坐标(如 YOLO 预测),框回归部分需要预测和 GT 一致格式 |
| 数据预处理 | 数据增强/图像裁剪时需同步变换边界框坐标 |
| 模型后处理 | NMS 需要角点框格式;输出可视化也是角点框格式 |
| 多端部署 | 模型在 PyTorch、ONNX、TensorRT、NCNN 等平台切换时,要统一框格式避免误差 |
🧠 五、思考题(练习)
-
📸 尝试使用你自己的图片做对象标注。
-
🕓 比较“框选对象”和“写下类别”哪个更耗时?
-
❓ 为什么
box_corner_to_center的输入张量最内层维度必须是 4?因为每个边界框都需要用 4 个数(x1, y1, x2, y2 或 cx, cy, w, h)表示,维度固定为 4。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











