







前言
为什么线性回归是机器学习的基石?
在房价预测、用户增长分析、广告点击率预测等场景中,我们经常需要建立多个影响因素与目标值之间的关系模型。
多元线性回归正是解决这类问题的核心工具。本文将带您深入理解这一经典算法,从数学推导到代码实现,揭示其背后的智慧。(文章较长,建议收藏慢慢看)
1、基本概念
线性回归是机器学习中有监督机器学习下的一种算法。 回归问题主要关注的是因变量(需要预测的值,可以是一个也可以是多个)和一个或多个数值型的自变量(预测变量)之间的关系。
有监督学习:需要带标签的训练数据
连续值预测:预测股票价格、销售额等连续数值
因果分析:量化不同因素对结果的影响程度
需要预测的值:即目标变量,target,y,连续值预测变量。
影响目标变量的因素: X 1 X_1 X1… X n X_n Xn,可以是连续值也可以是离散值。
因变量和自变量之间的关系:即模型,model,是我们要求解的。
以房价预测为例:
1.1、简单线性回归
算法说白了就是公式,简单线性回归属于一个算法,它所对应的公式:
y = w x + b y = wx + b y=wx+b
这个公式中,y 是目标变量即未来要预测的值,x 是影响 y 的因素,w,b 是公式上的参数即要求的模型。其实 b 就是截距,w 就是斜率嘛! 所以很明显如果模型求出来了,未来影响 y 值的未知数就是一个 x 值,也可以说影响 y 值 的因素只有一个,所以这是就叫简单线性回归的原因。
同时可以发现从 x 到 y 的计算,x 只是一次方,所以这是算法叫线性回归的原因。 其实,大家上小学时就已经会解这种一元一次方程了。

1.2、最优解
Actual value:真实值,一般使用 y 表示。
Predicted value:预测值,是把已知的 x 带入到公式里面和猜出来的参数 w,b 计算得到的,一般使用 y ^ \hat{y} y^ 表示。
Error:误差,预测值和真实值的差距,一般使用 ε \varepsilon ε 表示。
最优解:尽可能的找到一个模型使得整体的误差最小,整体的误差通常叫做损失 Loss。
Loss:整体的误差,Loss 通过损失函数 Loss function 计算得到。
1.3、多元线性回归
现实生活中,往往影响结果 y 的因素不止一个,这时 x 就从一个变成了 n 个, x 1 x_1 x1… x n x_n xn 同时简单线性回归的公式也就不在适用了。多元线性回归公式如下:
y ^ = w 1 x 1 + w 2 x 2 + … … + w n x n + b \hat{y} = w_1x_1 + w_2x_2 + …… + w_nx_n + b y^=w1x1+w2x2+……+wnxn+b
b是截距,也可以使用 w 0 w_0 w0来表示
y ^ = w 1 x 1 + w 2 x 2 + … … + w n x n + w 0 \hat{y} = w_1x_1 + w_2x_2 + …… + w_nx_n + w_0 y^=w1x1+w2x2+……+wnxn+w0
y ^ = w 1 x 1 + w 2 x 2 + … … + w n x n + w 0 ∗ 1 \hat{y} = w_1x_1 + w_2x_2 + …… + w_nx_n + w_0 * 1 y^=w1x1+w2x2+……+wnxn+w0∗1
使用向量来表示, X ⃗ \vec{X} X表示所有的变量,是一维向量; W ⃗ \vec{W} W表示所有的系数(包含 w 0 w_0 w0),是一维向量,根据向量乘法规律,可以这么写:
y ^ = W T X \hat{y} = W^TX y^=WTX【默认情况下,向量都是列向量】
矩阵相乘计算示例:
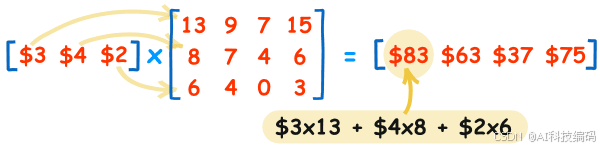
2、正规方程
2.1、最小二乘法矩阵表示
最小二乘法可以将误差方程转化为有确定解的代数方程组(其方程式数目正好等于未知数的个数),从而可求解出这些未知参数。这个有确定解的代数方程组称为最小二乘法估计的正规方程。公式如下:
θ = ( X T X ) − 1 X T y \theta = (X^TX)^{-1}X^Ty θ=(XTX)−1XTy 或者 W = ( X T X ) − 1 X T y W = (X^TX)^{-1}X^Ty W=(XTX)−1XTy ,其中的 W 、 θ W、\theta W、θ 即使方程的解!
什么是最小二乘法?
最小二乘法是一种数学优化技术,它通过最小化误差的平方和来寻找数据的最佳函数匹配。
原理:给定一组数据点 ( ( x i , y i ) ) , ( i = 1 , 2 , ⋯ , n ) ((x_i, y_i)),(i = 1,2,\cdots,n) ((xi,yi)),(i=1,2,⋯,n),假设我们希望找到一个函数 ( y = f ( x ) ) (y = f(x)) (y=f(x))来拟合这些数据点。最小二乘法的目标是找到一组参数,使得观测值 ( y i ) (y_i) (yi)与预测值 ( f ( x i ) ) (f(x_i)) (f(xi))之间的误差平方和最小。用数学公式表示,就是要最小化 ( S = ∑ i = 1 n ( y i − f ( x i ) ) 2 ) (S = \sum\limits_{i = 1}^{n}(y_i - f(x_i))^2) (S=i=1∑n(yi−f(xi))2),其中S表示误差平方和。
最小二乘法公式如下:
J ( θ ) = 1 2 ∑ i = 0 n ( h θ ( x i ) − y i ) 2 J(\theta) = \frac{1}{2}\sum\limits_{i = 0}^n(h_{\theta}(x_i) - y_i)^2 J(θ)=21i=0∑n(hθ(xi)−yi)2
增加 1 2 \frac{1}{2} 21是为了求导后消除2产生的系数。
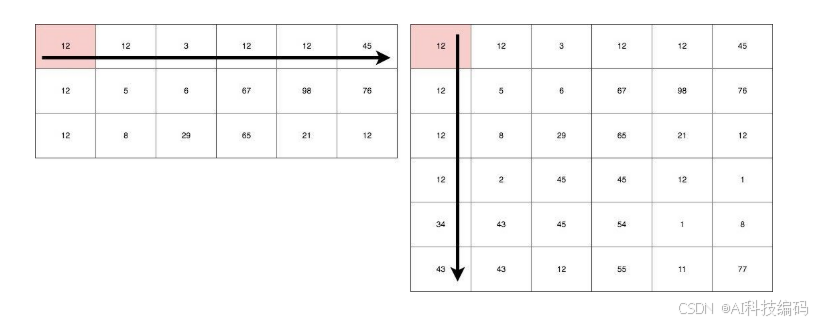
公式使用矩阵表示:
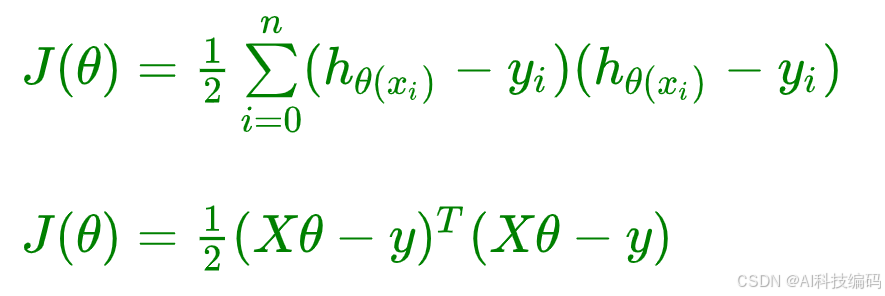
之所以要使用转置T,是因为矩阵运算规律是:矩阵A的一行乘以矩阵B的一列!
2.2、多元一次方程举例
1、二元一次方程
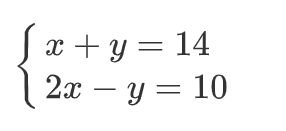
2、三元一次方程
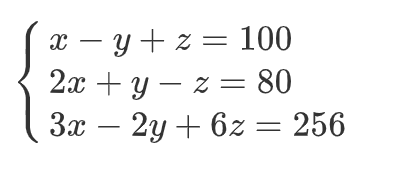
3、八元一次方程
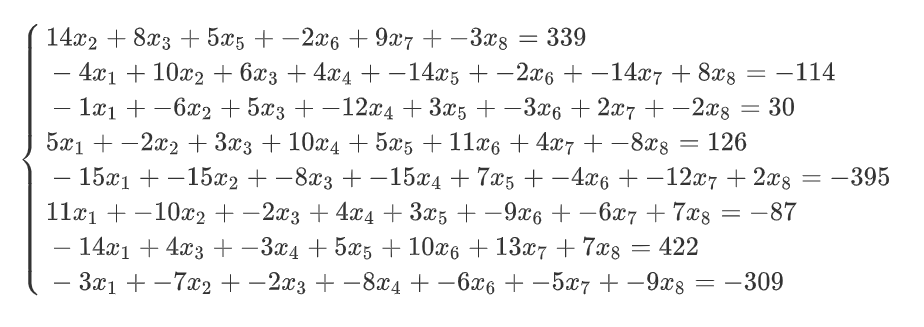
# 上面八元一次方程对应的X数据
X = np.array([[ 0 ,14 , 8 , 0 , 5, -2, 9, -3],
[ -4 , 10 , 6 , 4 ,-14 , -2 ,-14 , 8],
[ -1 , -6 , 5 ,-12 , 3 , -3 , 2 , -2],
[ 5 , -2 , 3 , 10 , 5 , 11 , 4 ,-8],
[-15 ,-15 ,-8 ,-15 , 7 , -4, -12 , 2],
[ 11 ,-10 , -2 , 4 , 3 , -9 , -6 , 7],
[-14 , 0 , 4 , -3 , 5 , 10 , 13 , 7],
[ -3 , -7 , -2 , -8 , 0 , -6 , -5 , -9]])
# 对应的y
y = np.array([ 339 ,-114 , 30 , 126, -395 , -87 , 422, - 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3096
3096

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









