







📘 动手学深度学习 - 构建指南 - 6.1 层和模块
6.1 层和模块
当初我们引入神经网络时,模型只有单个输出神经元。后来,为了支持多个输出,我们自然而然引入了**神经元层(Layer)**的概念。
-
单个神经元:输入 → 输出 → 参数
-
单个层(Layer):输入(向量) → 输出(向量) → 一组参数
即使是复杂模型如MLP(多层感知机),整体还是可以看作由层叠加构成,遵循同样的输入、输出、参数规律。
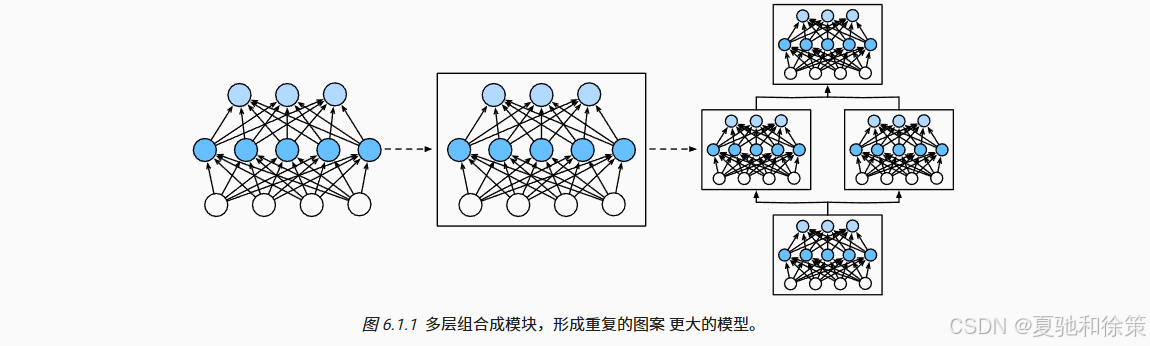
随着网络规模不断扩大(如ResNet-152有数百层),仅靠单层管理变得低效。因此,我们需要引入**模块(Module)**概念。
模块是更高一层的抽象:
它可以是单层
也可以是多层组合
也可以是整个子网络或整个模型本身
模块让我们能递归、灵活地组织网络。
理论理解:
-
最初神经网络就是一个单一神经元:输入 → 输出 → 参数。
-
扩展到多个输出时,演变为神经元层(Layer)。
-
MLP(多层感知机)就是由层堆叠起来的模型,本质仍是输入-输出-参数的组合。
-
当网络越来越大(如ResNet-152,数百层),单靠一层一层管理非常困难,因此引入模块(Module):
-
一个模块可以是单个层,也可以是多层组合,还可以是整个子系统。
-
模块支持递归嵌套,使复杂模型的搭建变得系统化、模块化。
-
企业实战理解:
-
Google 在开发 Inception(GoogLeNet)系列时,就是通过模块化把不同卷积组合成 "Inception模块",极大提升了模型扩展性。
-
OpenAI 在 GPT 系列(如 GPT-3)中,每一层 Transformer Block 也是标准模块(Multi-Head Attention + FFN),方便堆叠到几百层。
-
字节跳动在视频推荐、智能剪辑中也大量使用模块化的 CNN+LSTM 组合,便于快速扩展和部署不同版本。
-
NVIDIA在ResNet变种的实现(ResNeXt、EfficientNet)中,也坚持模块化组织,提升了可维护性与分布式训练效率。
6.1.1 自定义模块
为了理解模块,我们可以自己动手自定义一个模块。每个模块需要完成几件事:
-
接受输入:在
forward()方法中。 -
返回输出:可能形状变化,比如隐藏层输出是256维。
-
管理参数:存储可训练参数,如权重、偏置。
-
计算梯度:反向传播由框架自动处理。
-
初始化参数:根据需要自定义初始化方法。
示例,自定义一个简单的MLP:
class MLP(nn.Module):
def __init__(self):
super().__init__()
self.hidden = nn.LazyLinear(256)
self.out = nn.LazyLinear(10)
def forward(self, X):
return self.out(F.relu(self.hidden(X)))
-
__init__()定义层 -
forward()定义计算流程
✅ 只要继承nn.Module,并实现forward(),就能自定义任意复杂网络!
理论理解:
-
自定义模块就是自己写一个
nn.Module的子类:-
定义好
__init__()初始化各层 -
定义
forward()描述前向传播
-
-
模块需要:
-
接收输入,返回输出
-
存储并管理参数(可训练或不可训练)
-
(自动)支持反向传播(框架完成)
-
-
每个模块就是可以独立计算的一块"小模型"。
企业实战理解:
-
Google Research 在开发 MobileNetV3 时,通过自定义模块,灵活插入了轻量注意力(SE Block)、不同的激活函数(h-swish)等创新。
-
字节跳动在短视频推荐的视觉模型中,自定义模块融合了轻量卷积+MLP-Mixer变体,快速验证新结构。
-
OpenAI 在CLIP的Vision Encoder部分,曾自定义了多个特制的PatchEmbedding模块,用于高效处理图像切块。
-
自定义模块在企业中极其重要,因为实际需求变化快,标准模块往往不够用,需要快速自定义创新结构。
6.1.2 Sequential模块
Sequential是PyTorch提供的顺序容器模块,用于简洁地堆叠一组子模块。
比如MLP可以直接写成:
net = nn.Sequential(
nn.LazyLinear(256),
nn.ReLU(),
nn.LazyLinear(10)
)
特点:
-
模块按顺序连接
-
输入数据依次经过每一层
在Sequential中,前向传播forward()方法就是顺序地调用每个子模块的forward()。
简化了MLP、CNN、ResNet等线性结构模型的搭建过程。
理论理解:
-
nn.Sequential是一种简单而强大的容器模块:-
按顺序连接若干子模块
-
输入数据依次通过每一层
-
-
适合线性堆叠的神经网络,比如普通MLP、简单CNN、ResNet(某些Block内部)。
企业实战理解:
-
NVIDIA在TensorRT推理加速引擎中,遇到Sequential结构可以直接优化为流水线加速,提高推理速度。
-
字节跳动的图像识别模型训练中,如果整个模型是标准Sequential堆叠,可以直接一行定义,非常方便快速测试新结构。
-
Google TensorFlow中
tf.keras.Sequential也是标准组件,在工业界应用极为广泛,如图像分类、特征提取。 -
但实际工程中,如果需要灵活结构(比如Skip-connection、Attention),Sequential就不够用了,需要自定义Module。
6.1.3 在Forward Propagation方法中执行代码
Sequential虽然方便,但不够灵活,无法处理:
-
动态控制(如循环、条件)
-
自定义计算逻辑
-
引入不可训练参数(常量)
在需要灵活处理时,应该自定义模块,并在forward()方法中编写任意逻辑。
示例:固定权重矩阵+动态控制流:
class FixedHiddenMLP(nn.Module):
def __init__(self):
super().__init__()
self.rand_weight = torch.rand((20, 20)) # 固定常量
self.linear = nn.LazyLinear(20)
def forward(self, X):
X = self.linear(X)
X = F.relu(X @ self.rand_weight + 1)
X = self.linear(X)
while X.abs().sum() > 1:
X /= 2
return X.sum()
重点:
-
self.rand_weight不是参数,不参与优化。 -
可以在forward里嵌套任意Python控制结构(如while循环)。
✅ forward()就是神经网络执行图本身,灵活编程无极限!
理论理解:
-
Sequential只能简单堆叠,无法处理复杂逻辑。
-
当需要在网络中引入:
-
循环(
while、for) -
条件判断(
if) -
固定常量(不可训练)
-
多路径分支
-
-
就必须在自定义模块的
forward()方法中写任意Python代码。 -
forward()方法本质就是描述神经网络的执行流程。
企业实战理解:
-
OpenAI 在 DALL·E 的图像生成网络中,经常需要在 forward 中动态调整 mask、条件输入,非常灵活。
-
DeepMind 在 AlphaFold 蛋白质结构预测中,为了动态控制注意力权重,必须在forward中插入复杂数学公式。
-
字节跳动短视频多模态模型(音频+图像+文本)融合时,也需要在forward中进行动态判断数据模态并做不同处理。
-
Google BERT改进版(如ALBERT)中forward也需要动态根据输入长度做处理,非纯Sequential能胜任。
6.1.4 小结
本小节总结:
-
**层(Layer)**是最基本的构建单元。
-
**模块(Module)**可以是层、层组或整个网络。
-
模块可以递归嵌套,构建复杂神经网络。
-
Sequential适合线性堆叠结构,但灵活性受限。
-
在自定义模块中,可以自由编写任意复杂的前向传播逻辑。
模块不仅组织了参数和结构,也管理了:
-
参数初始化
-
自动微分
-
前向与反向传播
模块是现代深度学习框架(如PyTorch、TensorFlow、JAX等)的核心抽象。
理论理解:
-
模块(Module)是层级化建模的核心。
-
单层(Layer)是基本单位,多个Layer可以组成Module。
-
Module可以是单层、多层、甚至整个模型。
-
Sequential适合堆叠式结构,自定义Module适合灵活控制流。
-
模块管理了:
-
参数初始化
-
前向传播
-
自动反向传播
-
企业实战理解:
-
Google Brain开发Transformer模型就是标准的模块化实践,把Attention、FeedForward分开封装为模块。
-
NVIDIA Megatron-LM超大规模模型,每个微层(比如LayerNorm+Attention)都作为单独模块,方便并行与切分。
-
字节跳动在轻量视频分类、OCR、目标检测中,标准化模块,提升了工程效率和可维护性。
-
现代AI工业级模型,比如OpenAI GPT-4,几乎都是通过严格模块化设计,方便训练、微调、并行、部署。
✅ 全小节严格对齐总结表
| 小节 | 内容总结 |
|---|---|
| 6.1 层和模块 | 神经元 → 层 → 模块,模块更灵活 |
| 6.1.1 自定义模块 | 继承nn.Module,自定义forward,灵活控制 |
| 6.1.2 Sequential模块 | 线性堆叠模块的快捷方式 |
| 6.1.3 在forward中执行代码 | 支持任意计算、常量引入、动态控制流 |
| 6.1.4 小结 | 层是单位,模块是组合,模块让网络灵活高效 |
🎯 一句话总结
模块是深度学习工程的灵魂,掌握模块化,才能掌控复杂神经网络!




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











