







一、热力图
热力图是一种以颜色变化展示数据分布的可视化图表 ,它把数据矩阵中的数值通过颜色直观呈现,帮助人们快速理解数据的特征和规律。
1、原理
数据矩阵:热力图基于一个数据矩阵,矩阵中的每个元素对应一个特定的行和列的交叉点。例如在分析电商销售数据时,行可以代表不同的商品类别,列代表不同的销售月份,矩阵元素就是该商品类别在对应月份的销售额。
颜色映射:将数据矩阵中的数值映射到一个颜色空间。通常会定义一个颜色渐变的范围,比如从蓝色到黄色再到红色。数值低的区域用蓝色表示,数值中等的用黄色,数值高的用红色。软件会根据数据矩阵中每个元素的数值大小,在这个颜色渐变范围内选择对应的颜色进行填充。
可视化呈现:最后将带有颜色填充的矩阵以图表形式展示出来,形成热力图。这样人们就能通过颜色直观地理解数据矩阵中数值的分布情况。
2、作用
发现数据模式:通过颜色的深浅变化,能快速发现数据中的模式和趋势。比如在分析学生成绩数据时,以科目为行,学生为列,成绩为数值绘制热力图,就能直观看到哪些科目整体成绩较高(颜色浅),哪些科目普遍成绩低(颜色深),还能看出某些学生在哪些科目上表现突出或薄弱。
展示变量相关性:常用于展示多个变量之间的相关性。例如在分析房价影响因素时,将房屋面积、房龄、周边配套设施等因素两两之间的相关性系数用热力图展示,颜色越接近红色表示正相关性越强,越接近蓝色表示负相关性越强,这样可以一目了然地看到哪些因素之间关系紧密。
数据对比:方便对不同类别或组的数据进行对比。比如比较不同地区在多个经济指标上的表现,通过热力图能清晰看出各地区的优势和劣势指标。
3、相关系数矩阵与热力图的关系
1、协方差:


想到了在概率论中学到的协方差公式:
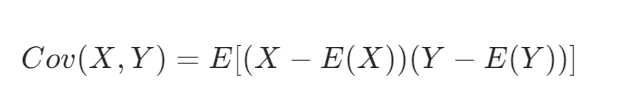
这个公式适用于总体数据情况,是从概率意义上对协方差的准确描述。而上面的公式是基于样本数据计算协方差的公式,是在实际应用中,当总体数据难以获取完整信息时,通过抽样得到样本,利用样本数据来估计总体协方差。
两者关联:在大数定律下,当样本数量 n 趋于无穷大时,样本均值趋近于总体期望,样本计算的协方差(第一个公式 )会趋近于理论定义的协方差(第二个公式 )。 也就是说,第一个公式是在实际统计分析中,用样本对第二个公式所定义的总体协方差的近似计算。
2、协方差和相关系数的联系与区别
二者均用来刻画两个变量之间线性相关程度的指标 。虽然能反映线性相关情况,但不能衡量变量间的非线性关系。
协方差的量纲是两个变量量纲的乘积,其数值大小受变量自身变化幅度(尺度)影响 ,不同量纲的变量计算出的协方差难以直接比较。
相关系数是对协方差进行标准化后的结果 ,消除了变量量纲的影响,取值范围固定在 [-1, 1] ,更便于不同数据集间相关程度的比较 。
3、相关系数矩阵:

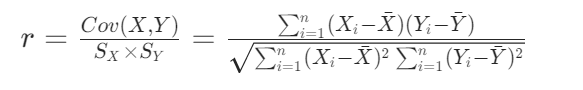
皮尔逊相关系数基于变量的均值、标准差以及它们的协方差来构建。其核心思想是通过标准化两个变量的协方差,得到一个在 -1 到 1 之间的数值,消除了度量单位的影响,便于不同变量间比较。
这里的皮尔逊相关系数就是概率论中学过的这个!!!
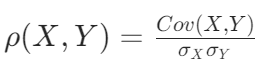
4、关系:
相关系数矩阵本身是一个数值表格,直接查看数值难以快速理解变量之间的关系模式。而热力图通过颜色编码,将相关系数矩阵中的数值转换为不同颜色,使我们能够一眼看出哪些变量之间相关性强(颜色深),哪些变量之间相关性弱(颜色浅)。
4、绘制流程
1、准备工作
皮尔逊相关系数是衡量两个连续变量线性相关程度最常用的指标。它的计算依赖于变量的均值、标准差和协方差,这些统计量的计算都基于数值运算。如果数据是类别型(如颜色:红、绿、蓝),没有数值意义,就无法直接套用皮尔逊相关系数公式。
# 读取数据
import pandas as pd
data = pd.read_csv('data.csv')
# 查看数据
data.info()
data.head(5)
# 对列值类别计数,确定如何编码
data["Years in current job"].value_counts()
data["Home Ownership"].value_counts()
# 字符串映射成数字
mappings = {
"Years in current job": {
"10+ years": 10,
"2 years": 2,
"3 years": 3,
"< 1 year": 0,
"5 years": 5,
"1 year": 1,
"4 years": 4,
"6 years": 6,
"7 years": 7,
"8 years": 8,
"9 years": 9
},
"Home Ownership": {
"Home Mortgage": 0,
"Rent": 1,
"Own Home": 2,
"Have Mortgage": 3
}
}
data["Years in current job"] = data["Years in current job"].map(mappings["Years in current job"])
data["Home Ownership"] = data["Home Ownership"].map(mappings["Home Ownership"])
data.info()
data.head()
data.columns2、求出相关系数矩阵
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 提取连续值特征(简单判别,不准确)
continuous_features = [
'Annual Income', 'Years in current job', 'Tax Liens',
'Number of Open Accounts', 'Years of Credit History',
'Maximum Open Credit', 'Number of Credit Problems',
'Months since last delinquent', 'Bankruptcies',
'Current Loan Amount', 'Current Credit Balance', 'Monthly Debt',
'Credit Score'
]
# 计算相关系数矩阵
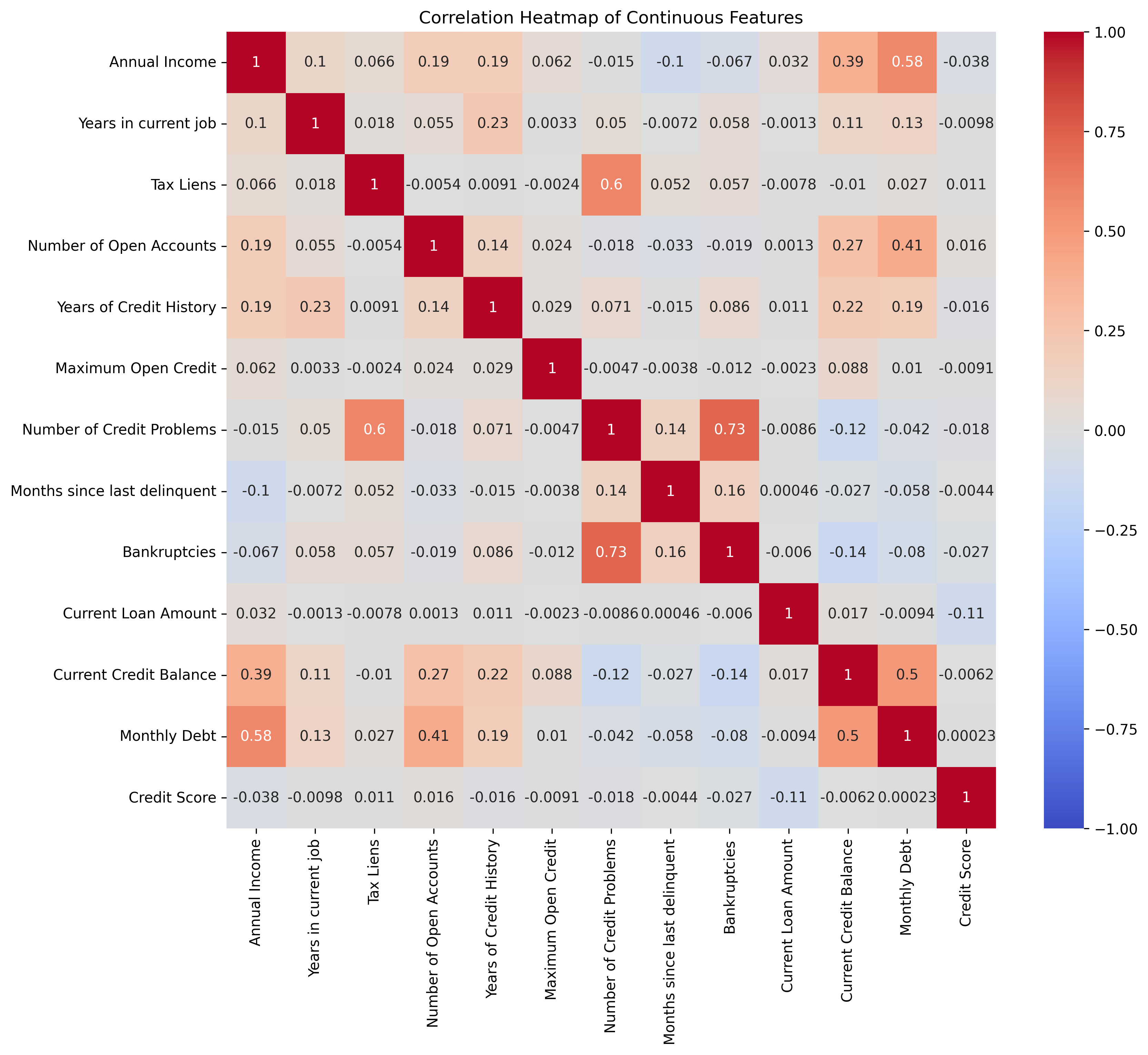
correlation_matrix = data[continuous_features].corr().corr() 方法:
计算所选连续特征间的皮尔逊相关系数矩阵。皮尔逊相关系数用于衡量两变量间的线性相关程度,取值范围在 -1 到 1 之间。该矩阵的元素 (i, j) 表示第 i 个特征与第 j 个特征之间的相关系数。
3、绘制热力图
# 设置图片清晰度
plt.rcParams['figure.dpi'] = 300
# 绘制热力图
plt.figure(figsize=(12, 10))
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', vmin=-1, vmax=1)
plt.title('Correlation Heatmap of Continuous Features')
plt.show()-
sns.heatmap是seaborn库中用于绘制热力图的函数。 -
correlation_matrix是传入的要绘制热力图的相关系数矩阵。 -
annot=True表示在热力图的每个单元格中显示相关系数的具体数值,方便查看每个特征对之间的相关程度。 -
cmap='coolwarm'指定使用名为coolwarm的颜色映射。coolwarm是一种双色渐变的颜色映射,通常蓝色表示负相关,红色表示正相关,颜色的深浅表示相关程度的强弱。 -
vmin=-1和vmax=1设定了颜色映射的取值范围为 -1 到 1,确保相关系数矩阵中的所有值都能在这个颜色映射范围内正确显示,突出显示相关性的程度和方向。
5、易错点
离散特征和连续特征都能计算相关系数吗?都可以绘制热力图吗?
离散特征与连续特征都能计算相关系数,但方法不同。
对于连续特征,常用皮尔逊相关系数来衡量它们之间的线性关系。离散特征计算相关系数不能直接用皮尔逊相关系数。对于两个分类变量(离散特征),常用的方法有卡方检验来衡量它们之间的相关性。卡方检验通过比较实际观测值与理论期望值之间的差异,判断两个变量是否相互独立,进而反映它们的关联程度。
都可以绘制热力图,但处理方式有别。
当对连续特征计算出相关系数矩阵(如使用皮尔逊相关系数得到)后,可直接绘制热力图。在热力图中,不同颜色代表不同的相关系数值,通过颜色的深浅直观展示各连续特征间的相关程度。对于离散特征,如果用卡方检验衡量相关性,一般需先将卡方检验的结果进行某种变换(如将检验的 p 值进行转换),使其在一个合适的数值区间内,再绘制热力图。
所以,无论是离散特征还是连续特征,从理论上来说都能计算相关系数并绘制热力图,只是需要根据特征类型选择合适的方法来计算相关系数,并对结果进行恰当处理以绘制有效的热力图。
二、子图绘制
import pandas as pd
import matplotlib.pyplot as plt
# 定义要绘制的特征
features = ['Annual Income', 'Years in current job', 'Tax Liens', 'Number of Open Accounts']
# 随便选的4个特征,不要在意对不对
# 设置图片清晰度
plt.rcParams['figure.dpi'] = 300
# 创建一个包含 2 行 2 列的子图布局
fig, axes = plt.subplots(2, 2, figsize=(12, 8))
# 绘制第一个箱线图
# 用于选择 features 列表中的第一个特征。
i = 0
# 从 features 列表中获取第一个特征名称。
feature = features[i]
# 在axes数组的 (0, 0) 位置(即第一行第一列的子图)绘制feature特征的箱线图。
# dropna() 方法用于去除数据中的缺失值,以避免绘图时出现错误。
axes[0, 0].boxplot(data[feature].dropna())
# 标题内容为 “Boxplot of [特征名称]”。
axes[0, 0].set_title(f'Boxplot of {feature}')
# 为该子图的 y 轴设置标签,标签内容为特征名称。
axes[0, 0].set_ylabel(feature)
# 绘制第二个箱线图(第一行第二列的子图)
i = 1
feature = features[i]
axes[0, 1].boxplot(data[feature].dropna())
axes[0, 1].set_title(f'Boxplot of {feature}')
axes[0, 1].set_ylabel(feature)
# 绘制第三个箱线图(第二行第一列的子图)
i = 2
feature = features[i]
axes[1, 0].boxplot(data[feature].dropna())
axes[1, 0].set_title(f'Boxplot of {feature}')
axes[1, 0].set_ylabel(feature)
# 绘制第四个箱线图(第二行第二列的子图)
i = 3
feature = features[i]
axes[1, 1].boxplot(data[feature].dropna())
axes[1, 1].set_title(f'Boxplot of {feature}')
axes[1, 1].set_ylabel(feature)
# 调整子图间距,避免标题、标签等元素相互重叠
plt.tight_layout()
# 显示图形
plt.show()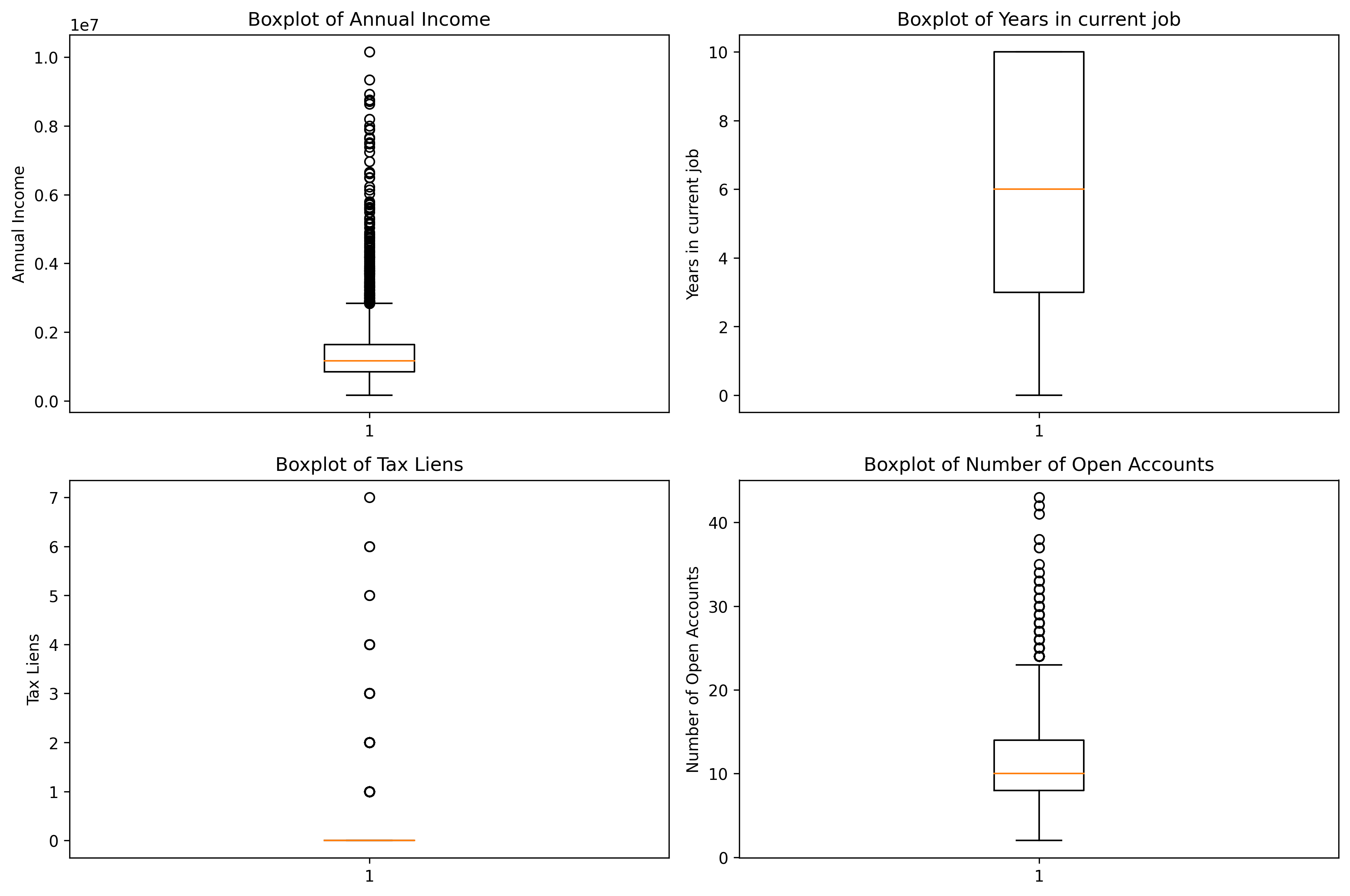 用循环实现:
用循环实现:
# 定义要绘制的特征
features = ['Annual Income', 'Years in current job', 'Tax Liens', 'Number of Open Accounts']
# 设置图片清晰度
plt.rcParams['figure.dpi'] = 300
# 创建一个包含 2 行 2 列的子图布局
fig, axes = plt.subplots(2, 2, figsize=(12, 8))
# 使用 for 循环遍历特征
for i in range(len(features)):
row = i // 2
col = i % 2
# 绘制箱线图
feature = features[i]
axes[row, col].boxplot(data[feature].dropna())
axes[row, col].set_title(f'Boxplot of {feature}')
axes[row, col].set_ylabel(feature)
# 调整子图间距
plt.tight_layout()
# 显示图形
plt.show()可以用enumerate 函数:
是一个非常实用的内置函数,它主要用于在遍历可迭代对象(如列表、元组、字符串等)时,同时获取元素及其索引。
语法:enumerate(iterable, start=0)
-
iterable:这是必须提供的参数,表示要遍历的可迭代对象。 -
start:这是可选参数,用于指定索引的起始值,默认值为0。
features = ['Annual Income', 'Years in current job', 'Tax Liens', 'Number of Open Accounts']
for i, feature in enumerate(features):
print(f"索引 {i} 对应的特征是: {feature}")
# 输出:
索引 0 对应的特征是: Annual Income
索引 1 对应的特征是: Years in current job
索引 2 对应的特征是: Tax Liens
索引 3 对应的特征是: Number of Open Accounts

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









