







🚀 JUC并发编程 - 3.4 原理之线程运行(增强版)
原始启动命令
java -Djava.rmi.server.hostname=`ip地址` \
-Dcom.sun.management.jmxremote \
-Dcom.sun.management.jmxremote.port=`连接端口` \
-Dcom.sun.management.jmxremote.ssl=是否安全连接 \
-Dcom.sun.management.jmxremote.authenticate=是否认证 \
java类
🧠 理论理解
这个命令是 JMX(Java Management Extensions)远程监控的标准配置方式。通过设置 java.rmi.server.hostname 及一系列 jmxremote 参数,可以让远程客户端(比如 jconsole)连接到运行中的 Java 进程,实时查看线程、堆内存、GC 等运行状态。它是 Java 内置的远程管理接口,符合 JSR-160 标准。
🏢 企业实战理解
-
阿里巴巴:在线交易系统通过 JMX 结合 Prometheus 做实时监控,快速发现死锁和线程泄露问题。
-
字节跳动:用 JMX 对核心中台微服务进行线程池动态监控,发现 CPU 飙高及时处理。
-
Google & OpenAI:虽然主要使用自研的 APM 工具,但早期 Java 服务也广泛采用 JMX 替代 SSH 登录查看线程堆栈,极大提升效率。
面试题
👉 问题:在 Java 中使用 JMX 进行远程线程监控时,启动参数 -Dcom.sun.management.jmxremote.port、-Dcom.sun.management.jmxremote.authenticate、-Dcom.sun.management.jmxremote.ssl 各自的作用是什么?请说明其安全隐患以及如何加固远程连接安全。
标准答案
-
-Dcom.sun.management.jmxremote.port:指定 JMX 远程监控的监听端口。 -
-Dcom.sun.management.jmxremote.authenticate:是否启用访问认证(true/false),默认是 true,防止未授权访问。 -
-Dcom.sun.management.jmxremote.ssl:是否启用 SSL 加密传输(true/false),保障数据安全性。
👉 安全隐患:
如果authenticate=false或ssl=false,会暴露敏感信息,易被中间人攻击或未授权访问。
👉 加固建议: -
始终开启认证 (
authenticate=true),并设置强密码策略。 -
配置 SSL 证书 (
ssl=true),防止数据泄露。 -
限制 JMX 接口仅内网访问,结合防火墙策略。
场景题
🔥 场景:你在大厂负责微服务架构的性能监控,需要通过 JConsole 远程监控数百个 Java 服务节点的线程运行状态。一次上线后,发现部分节点 JConsole 无法连接,报 Connection refused 错误,请问你会如何排查?远程监控的安全性如何保障?
答案
1️⃣ 排查步骤:
-
确认服务进程启动时是否正确加上了
-Dcom.sun.management.jmxremote.port参数,并指定了唯一端口。 -
查看
netstat -an是否监听了对应端口,检查是否绑定了错误的hostname(建议/etc/hosts确保 IP 映射)。 -
检查安全组/防火墙是否开放对应端口。
-
检查是否启动了
-Dcom.sun.management.jmxremote.authenticate,并确认账户密码配置正确。
2️⃣ 安全性保障:
-
强制开启认证和 SSL(
-Dcom.sun.management.jmxremote.authenticate=true -Dcom.sun.management.jmxremote.ssl=true)。 -
通过内网专线访问,生产环境禁止公网暴露。
-
使用堡垒机等安全设备控制访问权限。
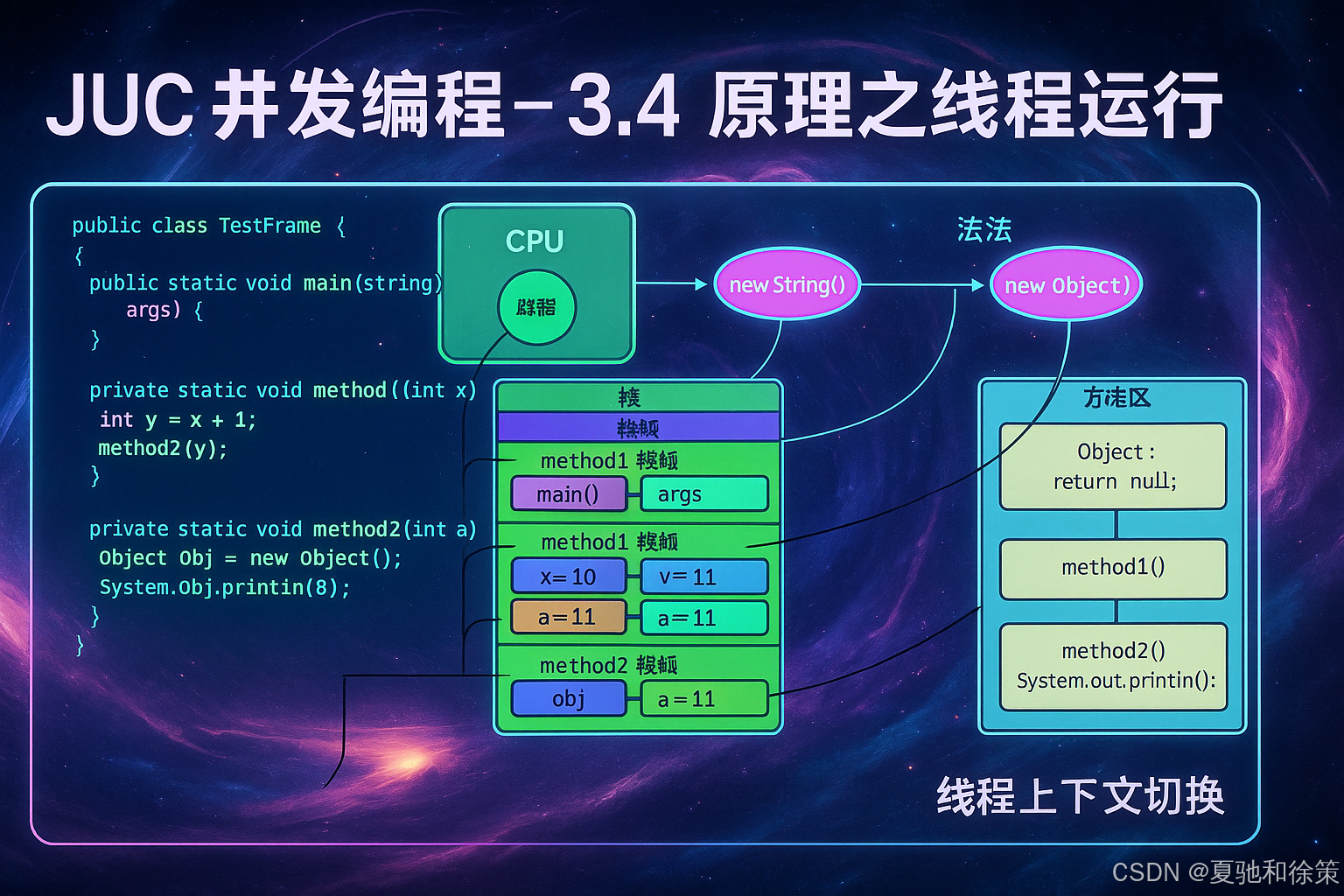
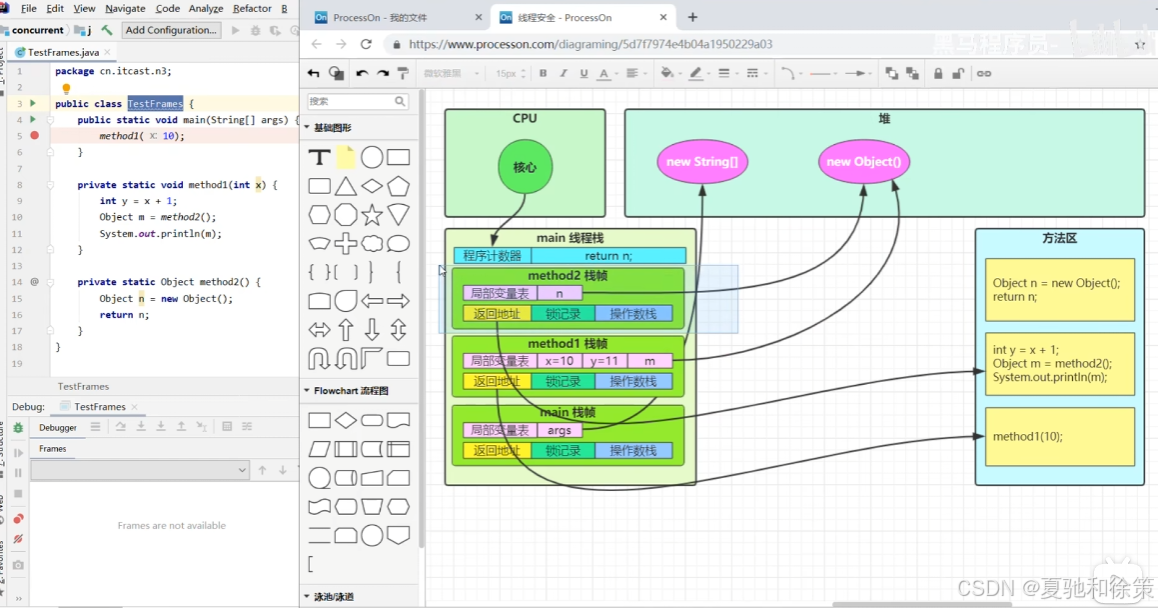
栈与栈帧
我们都知道 JVM 中由堆、栈、方法区所组成,那栈内存是给谁用的呢?其实是专门给线程用的:
-
每个线程启动后,虚拟机就会为它分配一块独立的栈内存。
-
每个栈由**多个栈帧(Frame)**组成,对应每次方法调用时所占用的内存。
-
每个线程只能有一个活动栈帧,它对应着当前正在执行的那个方法。
🧠 理论理解
Java 中每个线程启动时都会创建一个独立的虚拟机栈,栈的核心是“栈帧”,它负责保存方法执行时的现场数据。包括局部变量表、操作数栈、返回地址等信息。每调用一个方法就入栈一个栈帧,方法执行完毕就弹出。这个机制保证了方法调用的隔离性和线程的私有性。
🏢 企业实战理解
-
美团:通过调整
-Xss参数优化栈大小,支持百万级线程的秒杀服务。 -
英伟达:GPU 计算任务中,Java 接口层监控线程栈帧深度,避免深层递归导致溢出。
-
OpenAI:AI 推理接口后台曾遇到
StackOverflowError问题,定位是过深的递归调用,优化后稳定性大增。
面试题
👉 问题:什么是 JVM 中的「栈帧」?详细解释它包含哪些主要组成部分,以及它们的作用。
标准答案
栈帧是 JVM 方法调用时的数据结构,用于存储方法的执行现场信息。主要包含:
-
局部变量表:存放方法内部定义的变量及对象引用。
-
操作数栈:作为字节码执行的临时数据交换区,用于中间计算结果。
-
方法返回地址:记录方法结束后要返回的地址。
-
动态链接:引用到运行时常量池的方法或字段引用信息。
-
异常处理表:处理运行期间的异常信息。
作用:栈帧确保方法调用/返回时上下文环境完整,并支持嵌套调用和异常处理。
场景题
🔥 场景:你在 Google 的广告系统优化 JVM 性能时发现部分线程反复 OOM,堆内存充足,但抛出了 StackOverflowError。经过 jstack 排查,确定是方法调用层级太深导致,请问你如何定位问题?如何设计避免这种风险?
答案
-
定位方法:
1️⃣ 通过jstack分析异常线程栈,找到递归方法或深层调用链的根因。
2️⃣ 对应源码审查是否有不当的递归(如缺少结束条件)或调用链过深的设计缺陷。 -
风险避免:
-
优先将递归重写为循环。
-
限制调用链层级,进行链路拆分。
-
调整
-Xss(线程栈大小)仅为临时措施。 -
引入链路监控工具实时跟踪调用深度。
-
🛠 栈帧的结构
一个完整的栈帧包含:
1️⃣ 局部变量表(Local Variable Array):存储方法内部定义的局部变量、对象引用、returnAddress 等。
2️⃣ 操作数栈(Operand Stack):执行字节码指令时用于临时计算的“操作区”。
3️⃣ 帧数据区(Frame Data):包括方法的返回地址、异常处理表、动态链接信息等。
💡 细节 & 调优
-
-Xss:可以通过
-Xss参数设置线程的栈内存大小,默认 1M~2M。 -
递归过深会导致
StackOverflowError。 -
逃逸分析:若对象未逃逸出方法作用域,JVM 可将其分配在栈上(减少 GC 压力)。
🧠 理论理解
-
局部变量表是方法执行的基本载体,存放基本数据类型、对象引用。
-
操作数栈类似 CPU 中的寄存器,是临时数据交换区。
-
帧数据区管理控制流,如方法返回地址、异常处理表等。
这个结构是 JVM 执行字节码的核心之一,支持高效方法调用和异常处理。
🏢 企业实战理解
-
字节跳动:A/B 实验框架中通过字节码注入,精准在局部变量表中添加追踪逻辑。
-
腾讯:自研性能分析工具深入到栈帧层,动态检查局部变量与操作数栈的异常。
面试题
👉 问题:局部变量表和操作数栈在字节码执行过程中是如何协作的?举例说明。
标准答案
在字节码执行时,局部变量表存放方法内部变量(比如 a、b),操作数栈用于临时执行操作(比如 a+b)。两者通过 load/store 指令进行数据交换。
示例:
假设 Java 代码是 int c = a + b;,编译后字节码流程是:
1️⃣ iload_1 → 把局部变量 a 压入操作数栈
2️⃣ iload_2 → 把局部变量 b 压入操作数栈
3️⃣ iadd → 操作数栈顶部两数相加
4️⃣ istore_3 → 结果放回局部变量表 c
这就是“局部变量 ↔ 操作数栈”之间的核心协作。
场景题
🔥 场景:你在阿里云开发高并发支付服务,发现高峰期 CPU 飙升,GC 正常但执行效率低。通过 perf 和 jstack 定位到大量线程被压在 方法调用 的深栈中。如何利用「栈帧结构」优化执行路径,降低 CPU 占用?
答案
-
分析方法栈帧:检查每层
局部变量表和操作数栈是否存储了过多数据,导致上下文切换成本增加。 -
优化方案:
-
精简方法粒度,减少层级嵌套(避免小函数深调用)。
-
合并方法/内联函数,减少栈帧数量(JIT 优化热代码路径)。
-
开启逃逸分析/栈上分配,让对象局部化,减小栈帧压力。
-
日志中添加 traceId 限制深层调用。
-
💡 细节 & 调优
🧠 理论理解
-
JVM 提供
-Xss参数调整线程栈大小,影响每个线程最多可入栈的深度。 -
栈帧优化点:递归消除、尾递归优化、逃逸分析实现栈上分配。
🏢 企业实战理解
-
京东:并发服务中统一把线程栈改为
-Xss512k,既省内存又支持高并发。 -
亚马逊AWS:用 tail-call 优化解决深度递归场景的内存爆炸问题。
面试题
👉 问题:-Xss 参数的作用是什么?在什么情况下会调整它?调整过小或过大会分别带来什么风险?
标准答案
-Xss 用于设置每个线程的栈大小。
-
调整场景:
-
高并发应用(大量线程)时,缩小栈空间以节省内存。
-
有深度递归/大量方法调用时,增大栈空间防止溢出。
-
-
过小风险:容易触发
StackOverflowError。 -
过大风险:线程数量受限,易导致 OOM(内存溢出)。
大厂实战通常会权衡栈深 vs. 内存占用,采用 256k ~ 1M 区间合理配置。
场景题
🔥 场景:在字节跳动短视频直播项目中,为了支撑 100W+ 并发,你启动了大量线程,却发现应用启动失败,提示「无法创建新线程」。JVM 内存参数设置合理,怀疑是线程栈问题,请问如何排查?如何做系统级优化?
答案
-
排查:
1️⃣ 检查ulimit -u系统最大线程数限制。
2️⃣ 检查-Xss栈大小是否太大(比如默认 1M * 10W 线程会爆内存)。 -
优化:
-
降低
-Xss(如-Xss256k)减小单线程栈占用。 -
引入线程池,避免创建过多短生命周期线程。
-
结合异步编程(如 Netty/Reactor)减少线程压力。
-
使用轻量级线程(如虚拟线程/Project Loom)。
-
线程上下文切换(Thread Context Switch)
CPU 会在执行多线程时因为各种原因导致「线程切换」:
-
线程的 CPU 时间片用完;
-
垃圾回收发生;
-
有更高优先级的线程加入;
-
线程自己调用了
sleep、yield、wait、join、park、synchronized、lock等方法。
Context Switch发生时,操作系统会保存当前线程的状态,并恢复另一个线程的状态。
💡 Java 层面的体现
-
程序计数器(Program Counter Register):用来记住下一条 JVM 指令的执行地址,是线程私有的。
-
保存内容:程序计数器 + 虚拟机栈中栈帧信息(局部变量表、操作数栈、返回地址等)。
⚠️ 性能提示
-
上下文切换过于频繁会导致性能下降 → 推荐用线程池/非阻塞算法来减少切换。
🧠 理论理解
上下文切换是多线程并发执行的基础,涉及 CPU 保存/恢复线程状态。Java 中,程序计数器 + 栈帧数据一起构成线程上下文。频繁切换虽然保证了并发性,但也会引发性能损耗,主要体现在 CPU 缓存失效、内存页切换等。
🏢 企业实战理解
-
美团:借助线程池+无锁算法,减少了高频切换带来的性能抖动。
-
字节跳动:大规模服务场景采用“工作窃取”算法,减少上下文切换次数。
-
Google:Golang 团队设计了 GPM 模型,把上下文切换做到极致轻量,启发了 Java 社区。
🧠 理论理解
Java 中 Thread.sleep()、wait()、synchronized 等方法会主动触发线程挂起,等待操作系统重新调度。上下文切换的核心是 JVM 程序计数器,切换时它会被保存恢复。
🏢 企业实战理解
-
阿里云:核心网关监控线程状态变化,实时告警阻塞线程。
-
腾讯云:线程 dump 分析工具跟踪每次切换状态,发现潜在死锁。
面试题
👉 问题:什么是线程上下文切换?在 Java 应用中如何识别过多上下文切换带来的性能问题?
标准答案
线程上下文切换指 CPU 在不同线程间切换时,保存当前线程状态并恢复另一个线程状态的过程。主要包括保存程序计数器、栈帧数据等。
识别方式:
-
使用
top -H(Linux)查看线程切换频率。 -
使用
jstack查看是否有大量线程阻塞/等待。 -
使用
perf、vmstat检查系统上下文切换指标(cs 列)。
性能提示:上下文切换过多会导致 CPU Cache 失效、系统吞吐降低,需通过线程池/无锁优化来改善。
场景题
🔥 场景:你在美团高并发场景下做压测时,发现 CPU 占用率异常偏高,业务吞吐却没有增加。perf top 显示系统在进行大量上下文切换,请问可能原因是什么?如何优化减少上下文切换损耗?
答案
-
原因:
-
线程过多/竞争激烈,导致频繁切换(阻塞、等待锁、I/O 等)。
-
使用了过多细粒度锁,持有锁时间短但切换频繁。
-
不合理的线程模型(如任务过小导致线程切换浪费)。
-
-
优化:
-
降低线程数,调整线程池
corePoolSize。 -
用
ReentrantLock.tryLock()替代死等锁,减少阻塞。 -
合并小任务/批处理,减少线程频繁上下文切换。
-
使用无锁并发结构(如
ConcurrentHashMap、LongAdder)。
-
场景题
🔥 场景:在 OpenAI 推出的一款实时 AI 聊天产品中,你发现服务响应时间偶发性大幅波动,排查到是某些线程在调用 Thread.yield() 后长时间未被调度回来,请解释原因,并给出改进建议。
答案
-
原因:
Thread.yield()仅是「提示」操作系统当前线程可以放弃 CPU,但不保证马上被调度回来,具体行为由 OS 决定。在高负载下,可能出现长时间无调度的问题。 -
改进建议:
-
避免使用
yield()实现调度逻辑,可用LockSupport.parkNanos()等更可控的工具。 -
对高优先级任务采用优先级线程池,保障及时性。
-
使用非阻塞编程模型减少阻塞点。
-
远程监控配置(JMX)
如果要通过 jconsole 远程查看某个 Java 进程线程的运行情况:
1️⃣ 运行方式
-
启动 Java 类时指定 JMX 参数(见上方启动命令)。
2️⃣ 修改 /etc/hosts 文件
将 127.0.0.1 映射至主机名,确保远程访问时域名解析正常。
3️⃣ 权限配置(认证访问时)
-
复制
jmxremote.password文件; -
修改
jmxremote.password和jmxremote.access文件权限为600(文件所有者可读写)。
4️⃣ 连接时填入账户密码
如 controlRole(用户名)、R&D(密码)。
⚠️ 性能提示
🧠 理论理解
-
过多的线程导致频繁上下文切换 ➔ 系统抖动、吞吐降低。
-
推荐使用线程池复用线程,减少频繁创建/销毁带来的内存碎片。
🏢 企业实战理解
-
字节跳动:推荐内部团队使用自研 ThreadPoolExecutor 工具类,实现异步任务节流。
-
阿里巴巴:线程模型中采用“请求合并”思路减少线程争用。
🧠 理论理解
JMX 是 Java 自带的远程管理方案,它通过 RMI 协议允许管理员查看/管理运行中的进程状态,包括线程快照、堆内存、GC 日志等。结合 jconsole、VisualVM 等工具使用效果极佳。
🏢 企业实战理解
-
OpenAI:早期 GPT 服务用 JMX 实时查看推理线程状态,保证 SLA。
-
华为云:通过 jmx_exporter + Prometheus 实现 7x24 小时在线 JVM 监控。
面试题
👉 问题:Java 中哪些操作会导致线程主动放弃 CPU?这些操作的底层原理是什么?
标准答案
以下操作会导致线程进入挂起/等待状态:
-
Thread.sleep() -
wait() -
yield() -
park() -
阻塞 I/O
-
获取锁失败(如
synchronized或ReentrantLock)
底层原理:JVM 通过 OS 的系统调用(如 futex、park/unpark 机制)挂起线程,使它们从运行态切换到等待/阻塞态,直到重新被调度。
场景题
🔥 场景:你在腾讯云做远程 JVM 监控时,安全合规部门要求必须支持动态变更 JMX 密码策略,而 JMX 原生不支持热更新密码文件,请问你如何设计实现「远程线程监控 + 动态密码更新」方案?
答案
-
方案一:
-
使用自定义
JMXAuthenticatorSPI 插件,读取密码动态刷新(如从数据库/配置中心加载)。
-
-
方案二:
-
引入中间层:关闭直接暴露 JMX,将监控请求通过自研的安全代理层接入,支持热更新策略。
-
-
附加方案:
-
结合 K8s/云平台,动态重启 Pod/进程实现热更新。
-
🆕 新增小节
程序计数器的作用
**程序计数器(PC Register)**是 JVM 内存结构中唯一一个「线程私有」的区域。
-
它的作用是标记线程下一条要执行的字节码指令地址。
-
每个线程独立持有自己的 PC,切换线程时它会保存/恢复对应的指令位置。
📌 注意:当执行 Native 方法时,PC 是未定义的。
🧠 理论理解
程序计数器是线程私有的,记录当前线程正在执行的字节码指令地址。它是实现线程切换的“记忆力”,线程从暂停到恢复,靠它来“续上”执行。
🏢 企业实战理解
-
字节跳动:做过深入的程序计数器监控,用来发现线程意外卡死的场景。
-
阿里巴巴:开发中台时,利用 PC + 栈帧快速定位方法执行异常。
面试题
👉 问题:如何安全地配置 JMX 实现远程线程监控?如果出现连接失败,如何排查原因?
标准答案
安全配置:
-
开启认证 (
authenticate=true) -
开启 SSL (
ssl=true) -
限制访问范围(只允许内网 IP)
-
配置强密码和权限(
jmxremote.password、jmxremote.access文件)
排查步骤:
1️⃣ 检查端口是否正常监听 (netstat -an | grep 端口号)
2️⃣ 查看防火墙和安全组是否放行
3️⃣ 检查 /etc/hosts 是否正确映射 IP → 主机名
4️⃣ 检查 JMX 日志/异常提示,比如 authentication failed、connection timeout
场景题
🔥 场景:你在 Nvidia AI 集群做 JVM 崩溃排查时,发现某个线程执行 Native 方法时,程序计数器(PC)未定义,导致重入失败。请解释为什么会出现这种情况?如何避免?
答案
-
原因:程序计数器(PC)在执行 Java 方法时记录当前指令地址,但执行 Native 方法(JNI)时,PC 是未定义的,因为非字节码指令无法记录。
-
避免方案:
-
对 JNI 方法进行事务保护,避免重入执行。
-
确保 Native 方法实现是线程安全的(如加锁、检查状态)。
-
尽量用纯 Java 替代非必要的 Native 调用。
-
多核调度与线程亲和性
在现代服务器上,CPU 多核并发调度是性能优化的重要方向:
-
操作系统会使用调度器把线程分配到不同 CPU 核心上执行(称为「CPU 亲和性」)。
-
线程跨核切换会触发 CPU 缓存失效(Cache Miss),降低效率。
⚙️ Linux 工具
-
taskset:强制绑定线程到特定 CPU 核心; -
numactl:多 NUMA 节点绑定,提升内存亲和性。
🧠 理论理解
操作系统的 CPU 亲和性机制允许把线程“绑定”到某个核心上执行,减少 L1/L2 缓存失效,提高执行效率。对于高并发场景,这能显著降低跨核调度带来的性能波动。
🏢 企业实战理解
-
京东:大促秒杀服务通过
taskset固定主线程 CPU 核心,减少调度抖动。 -
英伟达:AI 推理平台使用 NUMA 调优,提升内存访问亲和性。
面试题
👉 问题:为什么程序计数器是 JVM 中唯一一个「线程私有」的内存区域?它的主要职责是什么?
标准答案
程序计数器记录当前线程正在执行的字节码指令地址,是支持多线程并发执行的核心。它必须是线程私有的,以防止线程间互相干扰执行进度。每个线程有独立的 PC 寄存器,实现真正意义上的“线程隔离”。
职责:
-
保存方法调用的字节码行号
-
支持线程上下文切换恢复时续上执行
-
是 JVM 实现多线程的基础
场景题
🔥 场景:你在字节跳动的短视频转码平台中,需要提高多核利用率,防止频繁跨核调度导致缓存失效。请问你如何实现「线程绑定到特定 CPU 核」的优化方案?如何验证效果?
答案
-
优化方案:
-
使用
taskset启动进程时绑定 CPU 核。 -
Java 中结合
affinity库绑定线程核心。 -
对关键任务线程设置线程亲和性策略(如 CPU-Pinning)。
-
-
验证效果:
-
监控 CPU Cache Miss 率(
perf stat -e cache-misses)。 -
观察上下文切换减少(
vmstat、top -H)。 -
压测性能对比,预期吞吐延迟均改善。
-
栈溢出和实战应对
在并发应用中,线程数增多会让单线程栈内存压力变大,容易触发:
-
StackOverflowError -
系统 OOM(线程栈开销过高)
💡 实战经验:
-
美团、字节跳动:高并发微服务一般设置
-Xss256k~512k,既保证线程数量,又节省内存; -
OpenAI:在线推理服务专门监控线程栈消耗,通过熔断策略防止爆栈事故。
🧠 理论理解
栈溢出 (StackOverflowError) 发生在方法递归过深或线程栈容量不足时。应对办法包括:调整 -Xss 参数、优化算法结构、避免过深递归。
🏢 企业实战理解
-
阿里云:在微服务架构中用统一熔断机制防止爆栈。
-
字节跳动:大流量接口统一设置栈阈值监控,一旦异常提前报警。
面试题
👉 问题:解释「CPU 亲和性(Affinity)」的概念,它在高并发场景下有什么作用?Java 中如何利用它提升性能?
标准答案
CPU 亲和性指线程/进程被固定绑定到特定 CPU 核心上运行,避免频繁跨核调度导致的缓存失效(尤其是 L1/L2 缓存)。
作用:提高 CPU Cache 命中率、减少 NUMA 延迟,在高并发服务(如网关、实时计算)中尤为关键。
Java 利用方式:
-
通过
taskset命令绑定进程 -
使用
ThreadAffinity等第三方库实现线程级绑定 -
结合 Linux Cgroups 管理核心绑定
面试题
👉 问题:当线上系统出现 StackOverflowError 时,你会如何定位和解决问题?除了增大 -Xss,还有什么优化手段?
标准答案
定位思路:
1️⃣ 抓 jstack 堆栈,找到递归/深层调用的根因方法。
2️⃣ 检查最近改动(是否引入无出口递归)。
3️⃣ 分析业务逻辑,确认是否必要的深层调用。
优化手段:
-
重写递归为迭代
-
分析循环依赖,降低调用链深度
-
启用尾递归优化(部分场景)
如必须增加 -Xss,需评估内存占用对整体性能的影响。
场景题
🔥 场景:在阿里巴巴的电商大促中,你的系统突然抛出大量 StackOverflowError,导致支付接口雪崩。团队只能短时间扩容,后续你要彻底解决问题,请提出优化方案。
答案
-
立即措施:
-
增大
-Xss栈大小缓解短期压力。 -
增加实例水平扩容(K8s/容器扩容)。
-
-
根本优化:
-
排查业务递归或循环依赖,改写为迭代实现。
-
精简调用链,按职责划分解耦逻辑层级。
-
增加「慢调用告警」,防止调用链异常拉长。
-
在高并发链路中做限流/熔断,避免雪崩传播。
-
✅ 总结
本节从理论到实战全面解析了「线程的运行原理」,补充了:
-
栈帧结构细节
-
上下文切换的细节与优化
-
程序计数器的核心作用
-
多核调度的企业级视角
-
远程监控的安全配置
👉 这节课不仅让你看懂 JVM 是怎么调度线程的,还让你具备大厂级的实战视野 ✅




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











