








4,IOC/DI注解开发管理第三方bean
前面定义bean的时候都是在自己开发的类上面写个注解就完成了,但如果是第三方的类,这些类都是在jar包中,我们没有办法在类上面添加注解,这个时候该怎么办?
遇到上述问题,我们就需要有一种更加灵活的方式来定义bean,这种方式不能在原始代码上面书写注解,一样能定义bean,这就用到了一个全新的注解==@Bean==。
这个注解该如何使用呢?
咱们把之前使用配置方式管理的数据源使用注解再来一遍,通过这个案例来学习下@Bean的使用。
🧠 理论理解
在 Spring 中,前面我们通过 @Component、@Service 等注解定义了自己的 bean,但第三方类(如数据源、工具类)位于 jar 包内,源码无法修改,这时就需要用方法级注解 @Bean来定义 bean。这实现了“不修改源码也能让 Spring 管理”的目标,符合IoC 反转控制思想。
🏢 企业实战理解
-
阿里巴巴:在管理复杂的分布式中间件(如 Dubbo、RocketMQ)时,用
@Bean动态注入配置类,将第三方 SDK 快速集成到 Spring 系统中。 -
字节跳动:大规模系统如火山引擎中,用
@Bean实现 Druid、Redis、ElasticSearch 等多套数据源的统一注入,保证灵活切换环境。 -
Google & OpenAI:在微服务与云原生架构中,常用
@Bean对接 GCP 存储、AI SDK 等,把第三方 SDK 当作“黑盒”接入,无需改源码。
❓ 面试题 1:你在实际项目中遇到过需要管理第三方 Bean 的场景吗?Spring 提供了哪些方式实现?
✅ 参考答案:
是的,尤其在对接第三方数据库连接池(如 Druid)、Redis 客户端、Elasticsearch SDK 时,我们通常要把这些“外部类”交给 Spring 管理。因为这些类在 jar 包中,我们无法用 @Component 注解。
Spring 提供的方式主要是 @Bean 注解,它用于方法上,方法的返回值会被 Spring 容器注册为一个 Bean。例如:
@Bean
public DataSource dataSource() {
return new DruidDataSource();
}
这种方式可以灵活定义 Bean,甚至可以对第三方 SDK 做初始化或包装。生产中大量用到。
🛠 场景题 1:
你在做一个在线教育平台,突然接到一个新需求:需要对接第三方的消息中间件(如 RabbitMQ)实现异步通知功能。但 RabbitMQ 提供的客户端类是外部 jar 包,你如何把它交给 Spring 管理并在 Service 层使用?请详细说说你的实现方案和考虑点。
✅ 参考答案:
这个场景很典型,RabbitMQ 的 ConnectionFactory 和 RabbitTemplate 都是第三方类,没法直接在类上加 @Component。
我会这样做👇:
1️⃣ 引入依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
2️⃣ 在配置类中定义 Bean:
@Configuration
public class RabbitMQConfig {
@Bean
public ConnectionFactory connectionFactory() {
CachingConnectionFactory factory = new CachingConnectionFactory("rabbitmq-server");
factory.setUsername("admin");
factory.setPassword("admin");
return factory;
}
@Bean
public RabbitTemplate rabbitTemplate(ConnectionFactory connectionFactory) {
return new RabbitTemplate(connectionFactory);
}
}
这样 Spring 就会自动托管这两个 Bean。
3️⃣ Service 层使用:
@Service
public class NotificationService {
@Autowired
private RabbitTemplate rabbitTemplate;
public void sendNotification(String message) {
rabbitTemplate.convertAndSend("edu-exchange", "edu.routing.key", message);
}
}
4️⃣ 考虑点:
-
我不会把账号密码写死在代码里,而是配合
@Value("${rabbitmq.username}")从配置文件注入; -
考虑连接池的优化,增加心跳检测等高级配置;
-
还会在
RabbitMQConfig中用@PropertySource加载外部rabbitmq.properties文件,保证代码和配置分离。
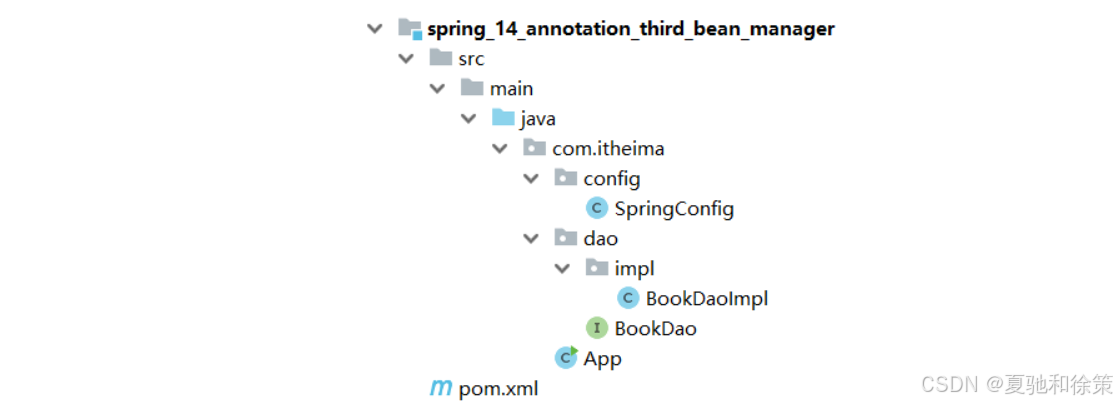
4.1 环境准备
学习@Bean注解之前先来准备环境:
-
创建一个Maven项目
-
pom.xml添加Spring的依赖
<dependencies> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-context</artifactId> <version>5.2.10.RELEASE</version> </dependency> </dependencies> -
添加一个配置类
SpringConfig@Configuration public class SpringConfig { } -
添加BookDao、BookDaoImpl类
public interface BookDao { public void save(); } @Repository public class BookDaoImpl implements BookDao { public void save() { System.out.println("book dao save ..." ); } } -
创建运行类App
public class App { public static void main(String[] args) { AnnotationConfigApplicationContext ctx = new AnnotationConfigApplicationContext(SpringConfig.class); } }
最终创建好的项目结构如下:
🧠 理论理解
环境准备主要是引入 Spring 核心模块和写好基础结构。这是搭建 Spring 注解开发的起点。
🏢 企业实战理解
大厂通常会内置封装 Starter,比如阿里把基础 Spring 配置封装到一个 Starter 中,减少每个项目重复写依赖的成本。Google 内部也是通过 Bazel 管理依赖,确保环境标准化。
4.2 注解开发管理第三方bean
在上述环境中完成对Druid数据源的管理,具体的实现步骤为:
步骤1:导入对应的jar包
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.16</version>
</dependency>步骤2:在配置类中添加一个方法
注意该方法的返回值就是要创建的Bean对象类型
@Configuration
public class SpringConfig {
public DataSource dataSource(){
DruidDataSource ds = new DruidDataSource();
ds.setDriverClassName("com.mysql.jdbc.Driver");
ds.setUrl("jdbc:mysql://localhost:3306/spring_db");
ds.setUsername("root");
ds.setPassword("root");
return ds;
}
}步骤3:在方法上添加@Bean注解
@Bean注解的作用是将方法的返回值制作为Spring管理的一个bean对象
@Configuration
public class SpringConfig {
@Bean
public DataSource dataSource(){
DruidDataSource ds = new DruidDataSource();
ds.setDriverClassName("com.mysql.jdbc.Driver");
ds.setUrl("jdbc:mysql://localhost:3306/spring_db");
ds.setUsername("root");
ds.setPassword("root");
return ds;
}
}注意:不能使用DataSource ds = new DruidDataSource()
因为DataSource接口中没有对应的setter方法来设置属性。
步骤4:从IOC容器中获取对象并打印
public class App {
public static void main(String[] args) {
AnnotationConfigApplicationContext ctx = new AnnotationConfigApplicationContext(SpringConfig.class);
DataSource dataSource = ctx.getBean(DataSource.class);
System.out.println(dataSource);
}
}至此使用@Bean来管理第三方bean的案例就已经完成。
如果有多个bean要被Spring管理,直接在配置类中多些几个方法,方法上添加@Bean注解即可。
🧠 理论理解
@Bean 注解用来告诉 Spring:“这个方法的返回值是我希望你管理的 Bean”。这样 Spring 在启动时执行这个方法,将返回值注册进容器。它是工厂方法模式的变体。
🏢 企业实战理解
-
阿里:使用
@Bean对不同环境下的数据源(测试、预发、生产)提供不同配置,并与 Nacos 配合动态刷新。 -
京东:京东支付系统里,所有的第三方服务(如微信/支付宝 SDK)都是用
@Bean动态注入,便于集中管理和监控。 -
字节跳动:自研的 RPC 框架在 Spring 项目中用
@Bean动态生成客户端代理类,这样服务发现和调用都无需硬编码。
❓ 面试题 2:@Bean 注解和 @Component 注解的区别是什么?为什么不能用 @Component 管理第三方 Bean?
✅ 参考答案:
@Component 用在类上,是类级别的注解,它的作用是把当前类交给 Spring 托管。比如我们自己写的 Service、Dao 都可以用 @Component。
但 @Bean 是用在方法上的注解,它的作用是:Spring 在执行该方法时,把方法的返回值注册为 Bean。
不能用 @Component 管理第三方类是因为我们没有权限去修改第三方库的源码,比如 DruidDataSource 类,它是一个外部类,我们没法加 @Component,所以必须用 @Bean。
一句话总结:
-
@Component适用于我们能控制源码的类; -
@Bean适用于不能控制源码但需要被管理的对象。
🛠 场景题 2:
项目中接入了 Druid 数据源,你通过 @Bean 注册 DataSource,但突然上线时 DBA 提出必须开启 SQL 日志。你会怎么动态修改已经注册好的 Bean,或者你会如何重新设计让这类“需求变动”更易扩展?
✅ 参考答案:
如果上线后才提出新需求,理论上已经注册好的 Bean 不方便再修改。但我会提前考虑“开放-封闭”原则,让 Bean 可配置。
改进方案👇:
1️⃣ 参数化 DataSource:
@Configuration
@PropertySource("classpath:jdbc.properties")
public class JdbcConfig {
@Value("${jdbc.url}")
private String url;
@Value("${jdbc.username}")
private String username;
@Value("${jdbc.password}")
private String password;
@Value("${jdbc.show-sql:false}")
private boolean showSql;
@Bean
public DataSource dataSource() {
DruidDataSource ds = new DruidDataSource();
ds.setUrl(url);
ds.setUsername(username);
ds.setPassword(password);
ds.setDriverClassName("com.mysql.jdbc.Driver");
ds.setConnectionProperties("druid.stat.slowSqlMillis=5000;druid.stat.logSlowSql=" + showSql);
return ds;
}
}
2️⃣ 配置文件动态控制:
在 jdbc.properties 中新增:
jdbc.show-sql=true
这样 DBA 不用改代码,改配置就能生效。
✅ 核心点:
-
使用
@Value注入配置项,控制细粒度参数; -
在
@Bean方法内做“灵活初始化”; -
如果更高级,我会设计一个
@Conditional注解,根据不同环境加载不同配置。
4.3 引入外部配置类
如果把所有的第三方bean都配置到Spring的配置类SpringConfig中,虽然可以,但是不利于代码阅读和分类管理,所有我们就想能不能按照类别将这些bean配置到不同的配置类中?
对于数据源的bean,我们新建一个JdbcConfig配置类,并把数据源配置到该类下。
public class JdbcConfig {
@Bean
public DataSource dataSource(){
DruidDataSource ds = new DruidDataSource();
ds.setDriverClassName("com.mysql.jdbc.Driver");
ds.setUrl("jdbc:mysql://localhost:3306/spring_db");
ds.setUsername("root");
ds.setPassword("root");
return ds;
}
}现在的问题是,这个配置类如何能被Spring配置类加载到,并创建DataSource对象在IOC容器中?
针对这个问题,有两个解决方案:
4.3.1 使用包扫描引入
步骤1:在Spring的配置类上添加包扫描
@Configuration
@ComponentScan("com.itheima.config")
public class SpringConfig {
}步骤2:在JdbcConfig上添加配置注解
JdbcConfig类要放入到com.itheima.config包下,需要被Spring的配置类扫描到即可
@Configuration
public class JdbcConfig {
@Bean
public DataSource dataSource(){
DruidDataSource ds = new DruidDataSource();
ds.setDriverClassName("com.mysql.jdbc.Driver");
ds.setUrl("jdbc:mysql://localhost:3306/spring_db");
ds.setUsername("root");
ds.setPassword("root");
return ds;
}
}步骤3:运行程序
依然能获取到bean对象并打印控制台。
这种方式虽然能够扫描到,但是不能很快的知晓都引入了哪些配置类,所有这种方式不推荐使用。
4.3.2 使用@Import引入
方案一实现起来有点小复杂,Spring早就想到了这一点,于是又给我们提供了第二种方案。
这种方案可以不用加@Configuration注解,但是必须在Spring配置类上使用@Import注解手动引入需要加载的配置类
步骤1:去除JdbcConfig类上的注解
public class JdbcConfig {
@Bean
public DataSource dataSource(){
DruidDataSource ds = new DruidDataSource();
ds.setDriverClassName("com.mysql.jdbc.Driver");
ds.setUrl("jdbc:mysql://localhost:3306/spring_db");
ds.setUsername("root");
ds.setPassword("root");
return ds;
}
}步骤2:在Spring配置类中引入
@Configuration
//@ComponentScan("com.itheima.config")
@Import({JdbcConfig.class})
public class SpringConfig {
}注意:
-
扫描注解可以移除
-
@Import参数需要的是一个数组,可以引入多个配置类。
-
@Import注解在配置类中只能写一次,下面的方式是==不允许的==
@Configuration //@ComponentScan("com.itheima.config") @Import(JdbcConfig.class) @Import(Xxx.class) public class SpringConfig { }
步骤3:运行程序
依然能获取到bean对象并打印控制台
知识点1:@Bean
| 名称 | @Bean |
|---|---|
| 类型 | 方法注解 |
| 位置 | 方法定义上方 |
| 作用 | 设置该方法的返回值作为spring管理的bean |
| 属性 | value(默认):定义bean的id |
知识点2:@Import
| 名称 | @Import |
|---|---|
| 类型 | 类注解 |
| 位置 | 类定义上方 |
| 作用 | 导入配置类 |
| 属性 | value(默认):定义导入的配置类类名, 当配置类有多个时使用数组格式一次性导入多个配置类 |
🧠 理论理解
为了让系统结构更清晰,可以把不同功能的配置拆成多个配置类,通过 @Import 或包扫描机制导入,形成模块化的配置结构。这种设计思想符合“高内聚、低耦合”。
🏢 企业实战理解
-
美团:将数据库、消息队列、缓存的配置拆成不同的配置类,再通过
@Import在主配置中集中引入,便于统一管理。 -
腾讯:微信支付 SDK 的接入在 Spring Boot 中是一个单独的配置模块,通过
@Import引入核心配置。 -
英伟达:在 GPU 云平台上,通过模块化配置实现对不同 GPU 集群的动态管理,降低了出错概率。
❓ 面试题 3:Spring 中如何将多个配置类组合起来?@ComponentScan 和 @Import 有什么区别?
✅ 参考答案:
Spring 提供两种方式组合多个配置类:
1️⃣ @ComponentScan:
-
它扫描指定包及子包中被
@Configuration注解标注的类; -
属于“自动发现”的方式。
2️⃣ @Import:
-
它是显式导入指定的配置类,适合我们清楚知道要加载哪些配置;
-
可以一次导入多个类(用数组)。
👉 区别:
-
@ComponentScan强调“扫描包路径”,更通用; -
@Import是直接指定某个配置类,结构更直观,企业中常用于组合模块。
企业实战中,如果项目很大,一般会用 @Import 明确导入,方便排查问题。
🛠 场景题 3:
项目组分模块开发,A 同事写了 JdbcConfig,B 同事写了 RedisConfig,现在上线前你要整合这两套配置,如何保证它们都能被 Spring 容器加载,且不会遗漏?
✅ 参考答案:
我会采用 显式引入 的方式,避免遗漏风险:
1️⃣ 新建 Spring 总配置类:
@Configuration
@Import({JdbcConfig.class, RedisConfig.class})
public class AppConfig {
}
2️⃣ 去掉 JdbcConfig 和 RedisConfig 上的 @ComponentScan(防止重复加载)。
✅ 为什么用 @Import 而不是 @ComponentScan?
因为显式 @Import 一目了然,所有加载的配置类都写在数组里,后期维护方便,且不会因为包路径变化而失效。
如果模块较多,我还会分层封装,比如:
@Import({DatabaseModule.class, CacheModule.class})
4.4 注解开发实现为第三方bean注入资源
在使用@Bean创建bean对象的时候,如果方法在创建的过程中需要其他资源该怎么办?
这些资源会有两大类,分别是简单数据类型 和引用数据类型。
4.4.1 简单数据类型
4.4.1.1 需求分析
对于下面代码关于数据库的四要素不应该写死在代码中,应该是从properties配置文件中读取。如何来优化下面的代码?
public class JdbcConfig {
@Bean
public DataSource dataSource(){
DruidDataSource ds = new DruidDataSource();
ds.setDriverClassName("com.mysql.jdbc.Driver");
ds.setUrl("jdbc:mysql://localhost:3306/spring_db");
ds.setUsername("root");
ds.setPassword("root");
return ds;
}
}4.4.1.2 注入简单数据类型步骤
步骤1:类中提供四个属性
public class JdbcConfig {
private String driver;
private String url;
private String userName;
private String password;
@Bean
public DataSource dataSource(){
DruidDataSource ds = new DruidDataSource();
ds.setDriverClassName("com.mysql.jdbc.Driver");
ds.setUrl("jdbc:mysql://localhost:3306/spring_db");
ds.setUsername("root");
ds.setPassword("root");
return ds;
}
}步骤2:使用@Value注解引入值
public class JdbcConfig {
@Value("com.mysql.jdbc.Driver")
private String driver;
@Value("jdbc:mysql://localhost:3306/spring_db")
private String url;
@Value("root")
private String userName;
@Value("password")
private String password;
@Bean
public DataSource dataSource(){
DruidDataSource ds = new DruidDataSource();
ds.setDriverClassName(driver);
ds.setUrl(url);
ds.setUsername(userName);
ds.setPassword(password);
return ds;
}
}扩展
现在的数据库连接四要素还是写在代码中,需要做的是将这些内容提
取到jdbc.properties配置文件,大家思考下该如何实现?
1.resources目录下添加jdbc.properties
2.配置文件中提供四个键值对分别是数据库的四要素
3.使用@PropertySource加载jdbc.properties配置文件
4.修改@Value注解属性的值,将其修改为
${key},key就是键值对中的键的值
具体的实现就交由大家自行实现下。
🧠 理论理解
@Value 注解主要用于注入基本数据类型或字符串,本质是通过占位符从配置文件中读取值,并填充到属性上。这提升了灵活性和可维护性,避免硬编码。
🏢 企业实战理解
-
阿里:数据源地址、Redis 配置等敏感信息通过 Nacos +
@Value注入,动态刷新。 -
字节:在直播高并发场景中,
@Value用于注入动态限流阈值,实时可配置。 -
Google:GCP 平台将云资源的连接串通过
@Value注入,并结合 KMS 加密系统确保安全。
4.4.2 引用数据类型
4.4.2.1 需求分析
假设在构建DataSource对象的时候,需要用到BookDao对象,该如何把BookDao对象注入进方法内让其使用呢?
public class JdbcConfig {
@Bean
public DataSource dataSource(){
DruidDataSource ds = new DruidDataSource();
ds.setDriverClassName("com.mysql.jdbc.Driver");
ds.setUrl("jdbc:mysql://localhost:3306/spring_db");
ds.setUsername("root");
ds.setPassword("root");
return ds;
}
}4.4.2.2 注入引用数据类型步骤
步骤1:在SpringConfig中扫描BookDao
扫描的目的是让Spring能管理到BookDao,也就是说要让IOC容器中有一个bookDao对象
@Configuration
@ComponentScan("com.itheima.dao")
@Import({JdbcConfig.class})
public class SpringConfig {
}步骤2:在JdbcConfig类的方法上添加参数
@Bean
public DataSource dataSource(BookDao bookDao){
System.out.println(bookDao);
DruidDataSource ds = new DruidDataSource();
ds.setDriverClassName(driver);
ds.setUrl(url);
ds.setUsername(userName);
ds.setPassword(password);
return ds;
}==引用类型注入只需要为bean定义方法设置形参即可,容器会根据类型自动装配对象。==
步骤3:运行程序
🧠 理论理解
方法参数注入是 Spring 的高级功能,当 @Bean 方法带有参数时,Spring 会自动从容器中找对应类型的 bean 注入,实现了自动装配。这是一种更灵活的依赖注入方式。
🏢 企业实战理解
-
美团:自动将日志监控组件(如 Logback 适配器)注入到数据源中,实现数据源层级的日志追踪。
-
OpenAI:在训练平台中,将数据源与模型训练任务调度器通过方法参数自动绑定,构建模块化流水线。
简单数据类型注入
❓ 面试题 4:生产中为什么建议不要把数据库连接信息写死在代码里?Spring 提供了哪些机制解决?
✅ 参考答案:
把数据库信息(驱动、URL、账号密码)写死在代码里有很大风险:
-
📉 不方便维护(换环境就要改代码);
-
🐞 不利于安全(容易泄露敏感信息);
-
💥 和 DevOps 理念冲突(环境变量/配置应解耦)。
Spring 提供 @Value 注解,结合 @PropertySource 加载 .properties 文件,实现外部化配置。生产中我们会把数据库信息写在 jdbc.properties 文件中,通过 ${} 占位符自动注入属性,达到“配置代码分离”。
例如:
@Value("${jdbc.url}")
private String url;
这样换环境时只要改配置文件即可,代码无改动。
❓ 面试题 5:在 @Bean 方法中如何注入容器中的其他 Bean?这种机制的底层原理是什么?
✅ 参考答案:
在 @Bean 方法的参数上声明需要的 Bean,Spring 会自动按类型注入。
例如:
@Bean
public DataSource dataSource(BookDao bookDao) {
// Spring 自动传入 BookDao 类型的 Bean
return new DruidDataSource();
}
底层原理:
-
Spring 在解析配置类时,会用
ConfigurationClassPostProcessor对@Bean方法做增强,形成 CGLIB 代理; -
当
@Bean方法被调用时,Spring 解析方法签名,根据参数类型在容器中查找匹配的 Bean 并注入。
这种机制本质是依赖查找 + 方法注入的组合,和 @Autowired 的原理类似,只是注入点从“属性”变成了“方法参数”。
简单数据类型注入
🛠 场景题 4:
你发现本地开发数据库是 localhost,但线上是内网 IP,想要让配置文件自动根据环境切换,不手动改代码,怎么实现?
✅ 参考答案:
我会采用Spring Profiles机制:
1️⃣ 拆分配置文件:
-
application-dev.properties(本地开发环境):
jdbc.url=jdbc:mysql://localhost:3306/dev_db
jdbc.url=jdbc:mysql://10.0.0.5:3306/prod_db
2️⃣ 配置类用 @PropertySource 动态加载:
@PropertySource("classpath:application-${spring.profiles.active}.properties")
3️⃣ 启动时切换环境:
-
本地运行时:
-Dspring.profiles.active=dev
-
生产运行时:
-Dspring.profiles.active=prod
这样不改代码、不动 jar 包,只需切换 profile 即可,企业非常常用。
🛠 场景题 5:
假如 DataSource 需要依赖一个自定义的加密组件来动态解密数据库密码,你怎么注入它?
✅ 参考答案:
我会这么做:
1️⃣ 先定义加密组件:
@Component
public class PasswordDecryptor {
public String decrypt(String encryptedPwd) {
// 自定义解密逻辑
return AES.decrypt(encryptedPwd);
}
}
2️⃣ 在 JdbcConfig 中注入:
@Bean
public DataSource dataSource(PasswordDecryptor decryptor) {
DruidDataSource ds = new DruidDataSource();
ds.setUsername("root");
ds.setPassword(decryptor.decrypt("ENCRYPTED_PWD"));
return ds;
}
✅ 核心点:
-
利用
@Bean方法参数注入; -
Spring 会自动将容器中的
PasswordDecryptor传入; -
确保解密逻辑与 DataSource 解耦。
这样以后只需要改解密组件,不影响其他代码。



















 1034
1034

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











