







2,统一结果封装
2.1 表现层与前端数据传输协议定义
SSM整合以及功能模块开发完成后,接下来,我们在上述案例的基础上分析下有哪些问题需要我们去解决下。首先第一个问题是:
-
在Controller层增删改返回给前端的是boolean类型数据

-
在Controller层查询单个返回给前端的是对象

-
在Controller层查询所有返回给前端的是集合对象

目前我们就已经有三种数据类型返回给前端,如果随着业务的增长,我们需要返回的数据类型会越来越多。对于前端开发人员在解析数据的时候就比较凌乱了,所以对于前端来说,如果后台能够返回一个统一的数据结果,前端在解析的时候就可以按照一种方式进行解析。开发就会变得更加简单。
所以我们就想能不能将返回结果的数据进行统一,具体如何来做,大体的思路为:
-
为了封装返回的结果数据:==创建结果模型类,封装数据到data属性中==
-
为了封装返回的数据是何种操作及是否操作成功:==封装操作结果到code属性中==
-
操作失败后为了封装返回的错误信息:==封装特殊消息到message(msg)属性中==

根据分析,我们可以设置统一数据返回结果类
public class Result{
private Object data;
private Integer code;
private String msg;
}注意:Result类名及类中的字段并不是固定的,可以根据需要自行增减提供若干个构造方法,方便操作。
🧠 理论理解
在前后端分离架构下,后端接口不仅要返回业务数据,还要让前端知道操作是否成功、出错原因是什么。
如果不同接口返回的格式各不相同(有的直接返回对象,有的返回布尔值,有的返回字符串),前端需要为每个接口写不同的解析逻辑,增加了开发成本和出错风险。
统一结果封装就是定义一套标准响应协议(通常包括 code、data、msg 三部分),让所有接口无论什么操作,都返回同一种格式。这样前端只需写一套通用处理代码,就能覆盖所有场景。
🏢 企业实战理解
-
阿里巴巴:阿里内部采用统一响应对象,前端 FE(Fusion)框架内置对 code 和 data 的解包器,后端返回统一格式,前端直接用统一中间件解析,减少重复工作。
-
字节跳动:字节在抖音、飞书、今日头条中,前后端都遵循字节通用 API 规范(类似 ResultWrapper),尤其是在微服务网关层,所有服务的响应格式会被强制包装为统一结构。
-
Google:Google Cloud API 提供统一 JSON 响应结构,包含状态码、消息、错误详情、traceId 等,方便云客户端自动化解析。
-
NVIDIA:NVIDIA GPU 云租赁平台使用统一响应对象,支持 REST 和 gRPC 接口双向封装,方便开发者 SDK 跨语言处理。
-
OpenAI:ChatGPT API 请求失败时,都会返回统一结构的 error 对象,开发者可根据 code 精细化处理(如限流、无权限、参数错误等)。
面试题 1:为什么要在后端统一封装 API 返回结果?
✅ 回答:
统一封装 API 返回结果的主要原因是提高前后端协作效率、降低出错概率、提高系统可维护性。
如果每个接口的返回格式不统一,前端需要针对不同接口写不同解析逻辑,既容易出 bug,又增加了开发复杂度。统一的返回结果(通常包含 code、data、msg 三个字段)使得前端只需编写一次通用的解析与异常处理代码,就能适配所有接口,提升开发效率。
同时,后端也更容易接入日志、监控、链路追踪等中间件,因为响应结构固定,系统可以自动化分析错误信息。
例如阿里巴巴、字节跳动内部都有“通用响应体”规范,要求所有服务强制遵守,否则代码无法通过 CI 流水线检查。
场景题 1:阿里巴巴双11活动接口崩溃
🌍 场景描述
双11大促前夕,阿里内部压测时发现,部分高并发场景下,前端请求返回的接口响应格式出现了混乱:有的接口直接返回对象,有的返回 JSON 字符串,有的因为异常返回了 HTTP 500 错误页,导致前端同学花大量时间写各种解析兼容逻辑。
📝 问题
如果你是后端开发负责人,你会怎么优化接口响应设计?具体会用什么技术或架构方案?
✅ 答案
我首先会推动团队在 Controller 层强制接入统一响应封装类(如 Result<T>),确保所有接口都遵循统一结构(包含 code、data、msg)。
此外,我会引入全局异常处理器(@ControllerAdvice + @ExceptionHandler),把所有后端抛出的未捕获异常统一转成 Result 格式。
为了防止历史接口“漏网之鱼”,我会写一套接口自动化测试,批量验证响应结构是否合规。
在阿里,这类问题通常配合 Sentinel(限流降级)和统一网关层,一旦后端服务压力过大,网关会直接返回预定义的“降级响应”包,保证响应结构稳定。
最终目标是:即便服务挂掉,前端也能收到明确的错误码和友好提示,而不是浏览器错误页。
2.2 表现层与前端数据传输协议实现
前面我们已经分析了如何封装返回结果数据,具体在项目中该如何实现,我们通过个例子来操作一把
2.2.1 环境准备
-
创建一个Web的Maven项目
-
pom.xml添加SSM整合所需jar包
-
创建对应的配置类
-
编写Controller、Service接口、Service实现类、Dao接口和模型类
-
resources下提供jdbc.properties配置文件
因为这个项目环境的内容和SSM整合的内容是一致的,所以我们就不在把代码粘出来了,大家在练习的时候可以在前面整合的例子案例环境下,进行本节内容的开发。
最终创建好的项目结构如下:
🧠 理论理解
环境准备主要是建立在已经搭建好的 SSM 项目上,不需要重复造轮子,只是在原有项目基础上扩展功能。这样能避免重复工作,提高开发效率,符合工程化的最优实践。
🏢 企业实战理解
-
美团:在大促场景下,常在现有后端服务快速引入统一响应规范以提升监控、追踪能力,而不是推倒重建系统。
-
字节跳动:使用 DevOps 平台快速在已有项目上添加统一响应模块,确保小步快跑、低风险上线。
场景题 2:字节跳动国际化接口扩展
🌍 场景描述
字节跳动的国际化产品(如 TikTok)上线多语言版本后,出现了一个问题:后端统一响应中的 msg 字段都是中文,导致海外前端收到错误提示时完全无法理解,用户体验很差。
📝 问题
你如何改进 Result 封装设计,支持国际化错误提示?
✅ 答案
我会重构 Result 类,把 msg 字段设计为消息码(messageKey),前端根据用户语言、从本地字典或远端配置获取对应翻译。
例如后端只返回:
{ "code": 50010, "messageKey": "USER_NOT_FOUND" }
前端根据 messageKey 映射到当前语言下的友好提示。
同时,后端也可以引入 Spring 的国际化支持(ResourceBundleMessageSource),在全局异常处理器中自动解析多语言文本。
字节跳动的工程体系中,这类国际化方案往往还结合了 A/B 测试,用来验证不同语言提示对转化率的影响。
2.2.2 结果封装
对于结果封装,我们应该是在表现层进行处理,所以我们把结果类放在controller包下,当然你也可以放在domain包,这个都是可以的,具体如何实现结果封装,具体的步骤为:
步骤1:创建Result类
public class Result {
//描述统一格式中的数据
private Object data;
//描述统一格式中的编码,用于区分操作,可以简化配置0或1表示成功失败
private Integer code;
//描述统一格式中的消息,可选属性
private String msg;
public Result() {
}
//构造方法是方便对象的创建
public Result(Integer code,Object data) {
this.data = data;
this.code = code;
}
//构造方法是方便对象的创建
public Result(Integer code, Object data, String msg) {
this.data = data;
this.code = code;
this.msg = msg;
}
//setter...getter...省略
}🧠 理论理解
Result 类作为一个响应数据的包装器,包含了实际数据(data)、响应码(code)和消息(msg)。这种设计遵循了分层解耦思想,把业务处理和响应构造分开,提高代码清晰度与可维护性。
🏢 企业实战理解
-
阿里巴巴:阿里有专门的 CommonResult 模板类,作为 Dubbo 接口、HTTP 接口、网关层输出的标准响应体。
-
字节跳动:字节采用通用 Response<T>,支持泛型封装,确保类型安全和灵活性。
-
Google:Google 的 Cloud Endpoints 和 API Gateway 强制封装 API 响应,带 traceId 和 debug 信息,便于跨团队排查问题。
步骤2:定义返回码Code类
//状态码
public class Code {
public static final Integer SAVE_OK = 20011;
public static final Integer DELETE_OK = 20021;
public static final Integer UPDATE_OK = 20031;
public static final Integer GET_OK = 20041;
public static final Integer SAVE_ERR = 20010;
public static final Integer DELETE_ERR = 20020;
public static final Integer UPDATE_ERR = 20030;
public static final Integer GET_ERR = 20040;
}
注意:code类中的常量设计也不是固定的,可以根据需要自行增减,例如将查询再进行细分为GET_OK,GET_ALL_OK,GET_PAGE_OK等。
🧠 理论理解
使用 Code 常量类代替“魔法数字”(magic numbers)是一种良好的编码规范。它让代码更易读、易维护,减少了硬编码带来的隐患。状态码分为成功码、失败码、业务细分码,有助于前端精细化处理。
🏢 企业实战理解
-
阿里巴巴:详细定义错误码(如 20001、20002、50001),并记录在 Wiki,所有前端、后端、测试人员共享同一份文档。
-
字节跳动:采用模块化错误码设计,如 10xxx 为用户模块,20xxx 为订单模块,30xxx 为支付模块。
-
OpenAI:API 响应错误码区分系统错误(如 500)、用户错误(如 400)、限流(如 429),便于开发者快速定位问题。
面试题 2:如何设计统一结果封装类中的 code 字段?
✅ 回答:
code 字段用于标识操作结果(成功/失败)以及具体的错误或业务状态。
设计时要注意几个要点:
1️⃣ 不要硬编码魔法数字,应该集中定义在常量类(如 Code 类)中;
2️⃣ 状态码需要分层设计,例如:
-
通用成功码(如 20000)、失败码(如 50000);
-
模块专属业务码(如用户模块 100xx,订单模块 200xx);
-
细分错误码(如参数错误、权限不足、资源不存在、限流等)。
这样设计不仅便于前端判断请求状态,还能帮助后端快速定位具体问题。
字节跳动、阿里巴巴的后端团队通常会在公司 Wiki 上维护一份统一错误码表,并定期更新,确保前后端团队共享同一套“语言”。
场景题 3:Google 分布式微服务链路追踪
🌍 场景描述
在 Google 的微服务系统中,统一响应封装已经是标配,但监控团队发现,部分接口的响应日志中 traceId 丢失了,导致链路追踪工具(如 Dapper)无法完整还原请求路径,影响问题排查。
📝 问题
你会如何优化统一响应封装,保障 traceId 始终存在?
✅ 答案
我会在统一响应 Result 中扩展一个 traceId 字段,由全局请求拦截器(HandlerInterceptor)或 Spring Cloud Sleuth 自动注入当前请求的 traceId。
如果是分布式架构,还要确保从网关层到下游微服务都统一传递 traceId(例如通过 HTTP Header 或 gRPC metadata),并在最终响应中带出。
Google 这种级别的公司,还会有专门的中间件组件统一治理 traceId 注入和传播,减少人工出错。最终目的是让每一条日志、每一个响应都能串起来,形成完整的调用链视图。
步骤3:修改Controller类的返回值
//统一每一个控制器方法返回值
@RestController
@RequestMapping("/books")
public class BookController {
@Autowired
private BookService bookService;
@PostMapping
public Result save(@RequestBody Book book) {
boolean flag = bookService.save(book);
return new Result(flag ? Code.SAVE_OK:Code.SAVE_ERR,flag);
}
@PutMapping
public Result update(@RequestBody Book book) {
boolean flag = bookService.update(book);
return new Result(flag ? Code.UPDATE_OK:Code.UPDATE_ERR,flag);
}
@DeleteMapping("/{id}")
public Result delete(@PathVariable Integer id) {
boolean flag = bookService.delete(id);
return new Result(flag ? Code.DELETE_OK:Code.DELETE_ERR,flag);
}
@GetMapping("/{id}")
public Result getById(@PathVariable Integer id) {
Book book = bookService.getById(id);
Integer code = book != null ? Code.GET_OK : Code.GET_ERR;
String msg = book != null ? "" : "数据查询失败,请重试!";
return new Result(code,book,msg);
}
@GetMapping
public Result getAll() {
List<Book> bookList = bookService.getAll();
Integer code = bookList != null ? Code.GET_OK : Code.GET_ERR;
String msg = bookList != null ? "" : "数据查询失败,请重试!";
return new Result(code,bookList,msg);
}
}🧠 理论理解
在 Controller 层集中封装返回结果,而不是把封装逻辑散落在 Service 或 Dao 层。这是因为 Controller 层作为表现层,直接面向前端请求,是定义接口协议的最佳位置。统一响应设计体现了单一职责原则(SRP)。
🏢 企业实战理解
-
美团:在订单服务 Controller 层统一封装结果,Service 层专注业务处理,网关层统一处理 traceId 和日志。
-
字节跳动:飞书后台服务要求 Controller 层实现统一响应,否则 CI/CD 流程会拦截代码合并。
-
Google:Google Maps API 后端在接口层统一注入 requestId 和响应封装,便于系统跟踪。
面试题 3:为什么 Result 类要设计成泛型(如 Result<T>)?
✅ 回答:
设计成泛型 Result<T> 而不是用 Object 类型的 data,有以下几个好处:
-
类型安全:编译期就能发现数据类型不匹配的问题,减少运行时 ClassCastException。
-
更好的代码提示:IDE(如 IntelliJ IDEA)能自动识别 T 的类型,提供代码补全和提示。
-
增强可读性:代码一目了然,明确知道 data 中装的是什么类型的对象。
大厂内部(如 Google、字节跳动)普遍推荐泛型封装方案,甚至通过代码扫描工具(如 FindBugs、SonarQube)强制禁止使用 Object 类型的 data,以保障系统代码质量。
场景题 4:腾讯云 API 网关统一响应规范
🌍 场景描述
腾讯云为外部客户提供海量 API 服务,后端团队发现有些业务团队私自修改了 API 返回格式,导致网关无法统一收敛接口数据,客户收到的响应格式混乱,投诉增多。
📝 问题
作为平台技术负责人,你怎么从架构上解决?
✅ 答案
我会在 API 网关层强制做响应格式封装,无论后端返回什么,网关都统一包裹成公司定义的标准响应结构(比如 code、data、msg、traceId)。
此外,在后端团队的开发环节,强制接入统一响应的 Lint 校验和 CI 检查,代码不符合规范的直接禁止合并。
腾讯云这样的公司,一般还会在 API 开发门户里定义清晰的接口规范文档,供所有业务团队遵循,避免随意扩展或修改响应格式。
步骤4:启动服务测试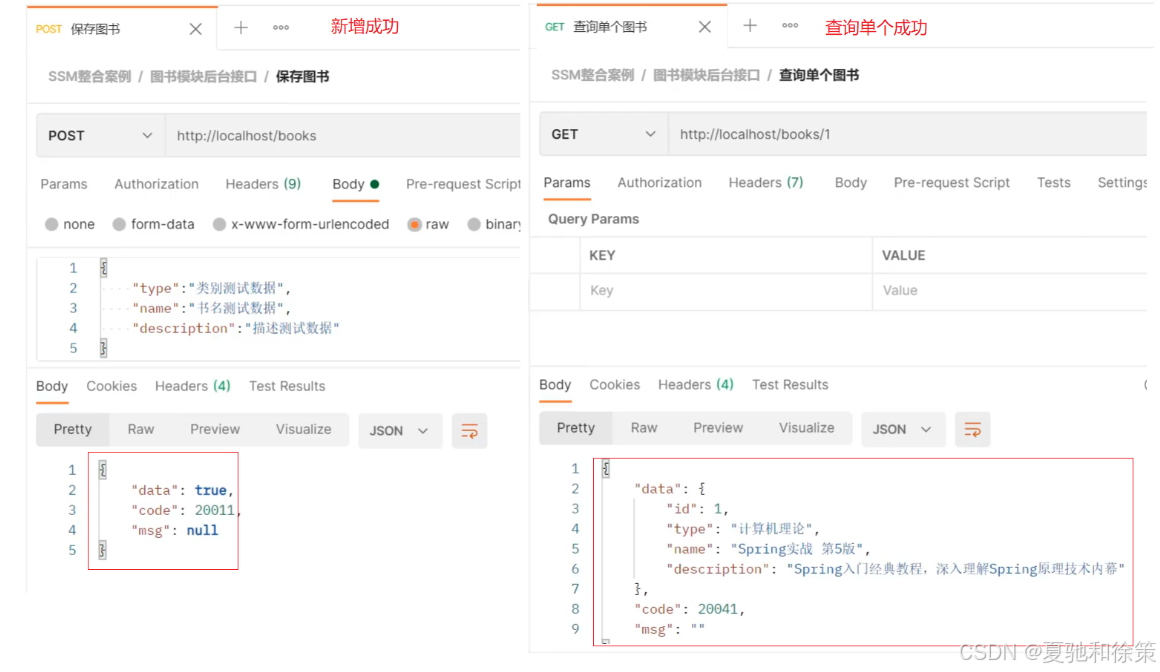
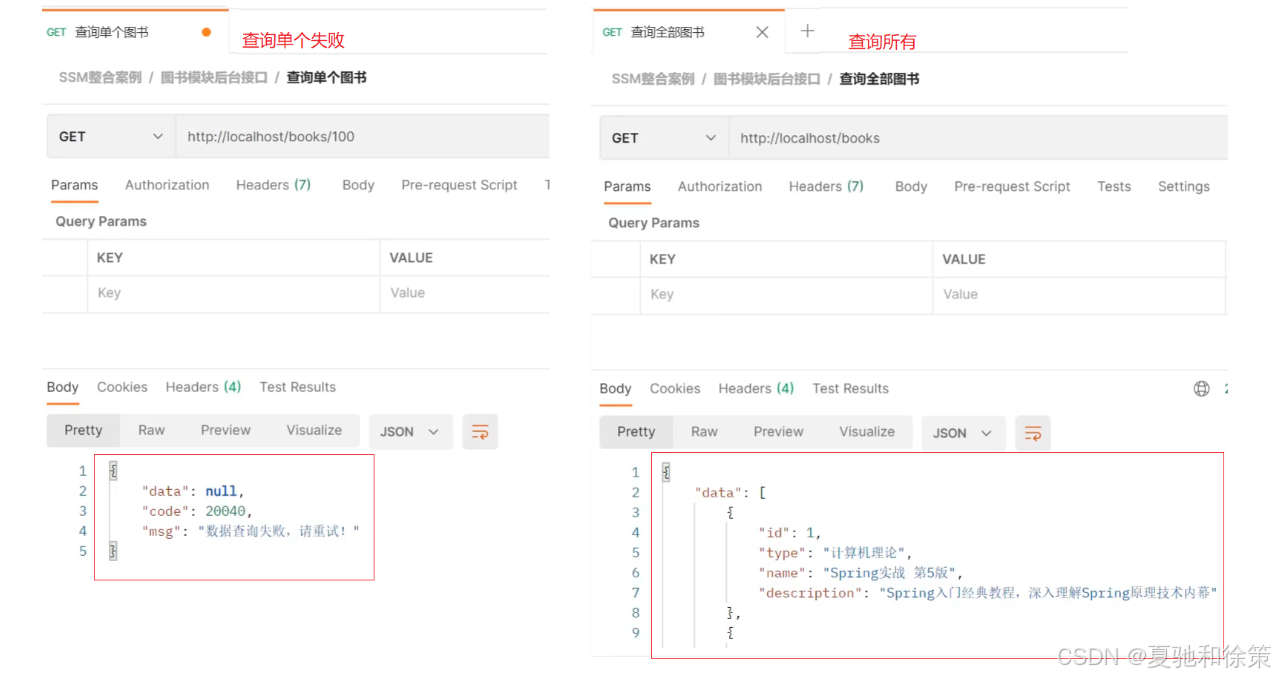
至此,我们的返回结果就已经能以一种统一的格式返回给前端。前端根据返回的结果,先从中获取code,根据code判断,如果成功则取data属性的值,如果失败,则取msg中的值做提示。
🧠 理论理解
统一响应不仅方便前端解析,也便于开发和测试。通过 Postman 或自动化测试工具,只需验证 code、data、msg 即可覆盖绝大部分测试场景,减少重复劳动,提升测试效率。
🏢 企业实战理解
-
阿里巴巴:阿里使用 PTS(性能测试服务)自动化跑通接口测试,只要响应结构统一,测试用例就能快速复用。
-
字节跳动:字节用自研测试工具覆盖接口测试,基于统一响应体自动提取并校验返回值,快速发现回归问题。
-
OpenAI:在 ChatGPT API 平台,自动化测试脚本每天跑上千次接口验证,统一响应结构极大降低了脚本复杂度。
面试题 4:统一结果封装应该放在哪一层实现,为什么?
✅ 回答:
统一结果封装应该在 Controller(表现层)实现,而不是 Service 或 Dao 层。原因是:
-
Controller 层面向外部接口,负责定义和维护前后端的数据传输协议;
-
Service 层专注于业务逻辑处理,Dao 层专注于数据访问,混入响应封装会破坏分层解耦原则;
-
在 Controller 层统一封装还能方便接入全局异常处理器(如 @ControllerAdvice),让异常也能返回统一格式。
在大厂(如阿里、字节、腾讯),如果你把封装逻辑写在 Service 层,很可能被 reviewer 打回,因为这属于典型的职责混乱,违反单一职责原则(SRP)。
面试题 5:如何结合统一结果封装和全局异常处理器优化系统设计?
✅ 回答:
全局异常处理器(通常用 @ControllerAdvice + @ExceptionHandler 实现)可以拦截系统中未捕获的异常,将其统一包装成 Result<T> 结构返回给前端。
这样,前端无论是正常请求还是发生异常,收到的都是固定结构的响应,极大简化了错误处理代码。
例如阿里巴巴会结合 Sentinel(限流)、日志埋点,把异常、限流、降级等响应全部通过统一响应封装返回,便于监控和告警。
字节跳动的微服务网关层也会拦截后端异常,转化成标准响应格式,以保证前端体验一致。
场景题 5:OpenAI 高并发下的异常与限流响应
🌍 场景描述
OpenAI 在 ChatGPT API 商业化过程中,遇到一个挑战:当系统超负荷时,部分限流或超时异常直接抛给前端,导致客户看不到明确的错误提示,只知道接口失败了。
📝 问题
如何用统一结果封装改进异常与限流响应?
✅ 答案
我会在后端统一响应封装中引入专门的限流和超时错误码(比如 code=42900 表示限流,code=50400 表示超时),并在全局异常处理器中拦截对应异常(如 RateLimitException、TimeoutException),转换为统一的 Result 响应。
此外,网关层也可以配置限流和超时保护,一旦触发阈值,直接返回标准化的限流响应包,而不是让请求一路打到后端才失败。
OpenAI 这类 AI 平台还会将这些响应打通到监控系统,实时展示限流和超时趋势,用于容量评估和扩容决策。
面试题 6:在高并发系统中,统一响应设计有哪些优势?
✅ 回答:
在高并发场景下,统一响应有两大优势:
1️⃣ 降低系统复杂度:前后端可以提前约定好所有可能的返回码和数据格式,避免实时协商和动态适配,减少接口摩擦点;
2️⃣ 提升监控可观测性:由于响应格式统一,监控系统可以通过简单的正则或 JSON Path 就解析出状态码、错误码、traceId 等信息,快速统计系统健康状态。
在大厂(如美团、字节、腾讯云),统一响应通常与 APM(应用性能监控)、链路追踪系统结合,自动生成告警、指标报表,实现全链路可观测。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











