







动手学深度学习 - 11. 注意力机制和转换器
📘 11.2 通过相似性进行注意力汇聚(带图讲解)
本节我们将引入注意力机制的原始思想来源——Nadaraya-Watson 核回归估计器,通过定义不同核函数来模拟“相似性加权”,帮助我们从统计视角理解现代注意力机制。
11.2.1 内核和数据
为了进行基于相似性的注意力聚集,我们需要定义“相似性”的数学形式 —— 核函数(kernel function)。
常见内核函数包括:

核函数可视化如下所示: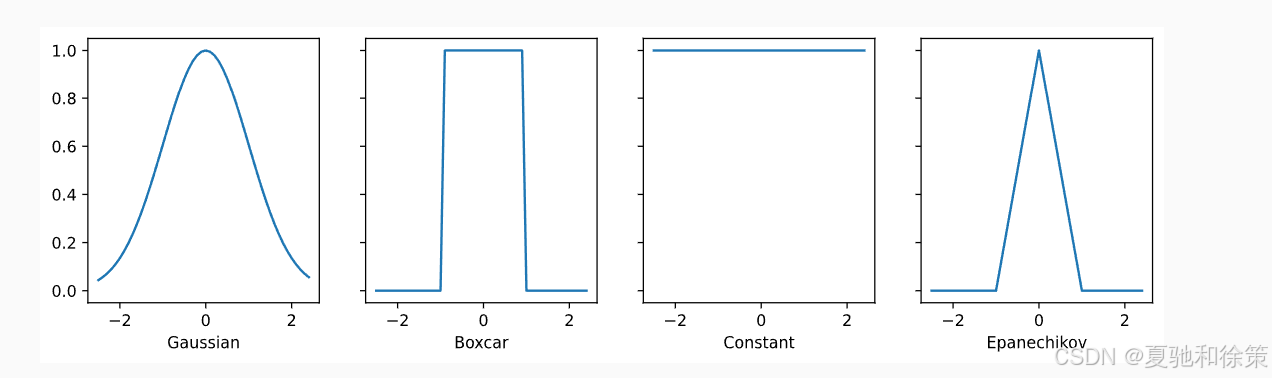
✅ 这些核函数具有平移与旋转不变性,也就是说只取决于 ∥q−k∥\|\mathbf{q} - \mathbf{k}\|,而与位置无关。
我们接着定义一个回归函数作为训练集的生成来源:
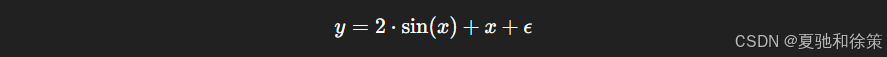
其中 ϵ\epsilon 是标准正态噪声。我们使用 40 个训练样本和一组等间距验证点。
🧠 理论理解:
核函数定义了 query 和 key 的“相似度度量方式”,不同的核(Gaussian、Boxcar、Epanechikov)对应不同的关注范围和平滑程度,是注意力机制中最早的“打分函数”原型。此处所用核函数具有平移和旋转不变性,是最简单的一类 attention 机制。
🏢 企业实战理解:
在大厂早期推荐系统(如阿里内容推荐、Google Ads)的冷启动阶段,常用“基于距离”的核函数构造“兴趣匹配”得分。NVIDIA 在图像检索预处理阶段曾使用核函数做局部匹配,作为 attention 的前置过滤器。虽然现代注意力主要是可学习的,但这些核函数仍被用于构造先验 attention mask(如 layout-aware attention)。
✅ 面试题 1
什么是 Nadaraya-Watson 回归?它与注意力机制的核心思想有什么相似之处?
参考答案:
Nadaraya-Watson 是一种基于核密度加权的非参数回归方法,其思想是对 query 附近的 training sample 进行加权平均,权重由核函数(如 Gaussian)计算的相似度决定。
它与注意力机制的结构一致:
-
Query 是待预测点
-
Keys 是训练集特征
-
Values 是对应标签
-
核函数对应注意力权重打分函数
📌 场景题 1(字节跳动 · 推荐系统)
**背景:**你负责字节跳动某冷启动推荐模块,用户没有历史行为轨迹,只能通过当前 query(如昵称、头像 Embedding、地理位置)与老用户做“相似性召回”。你需要选用一种无监督方法进行粗排或打分,请问你会怎么做?是否可以使用 Nadaraya-Watson 回归思想?又该如何解释这个 attention 的可视化结果?
✅ 参考答案:
-
是的,可使用 Nadaraya-Watson Attention:
-
每个老用户特征为 key;
-
用户标签为 value(如兴趣簇中心);
-
新用户 query 与历史 key 通过核函数打分形成注意力权重;
-
-
加权后的 value 即为召回的“候选兴趣中心”或行为表示;
-
可视化权重矩阵可以清晰解释:哪些老用户影响了当前推荐;
-
字节实际在冷启动阶段就有使用固定 kernel 的 attention 模块,如 Gaussian + 地理位置/头像嵌入。
11.2.2 通过 Nadaraya-Watson 回归进行注意力汇聚
Nadaraya-Watson 回归器的估计公式如下:
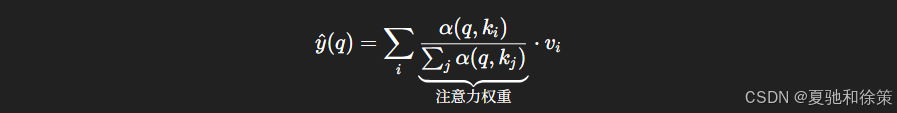
可以将其看作是一个“非训练式 attention”机制:
-
Query:每个验证点 xvalx_{\text{val}};
-
Key:每个训练样本 xtrainx_{\text{train}};
-
Value:每个训练样本对应的标签 ytrainy_{\text{train}}。
使用不同核函数得到的拟合结果如下图: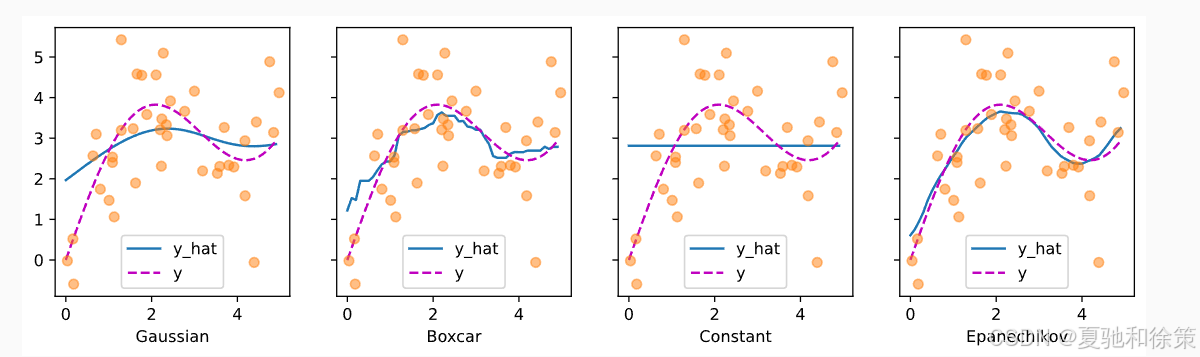
结论:
-
Gaussian、Boxcar、Epanechikov 都能合理逼近真实函数;
-
Constant 核完全失去区分度,表现不理想。
🧠 理论理解:
该回归器将注意力理解为核函数归一化后的加权平均,与 Transformer 中的 softmax(QK^T)V 非常相似。每一个验证点是 query,训练集是 key-value pairs,最终得到的是一个“无训练 attention 模块”。
🏢 企业实战理解:
在 OpenAI 的 Instruct 模型微调过程中,曾使用类似的非学习 attention 进行对齐阶段评分(如评估 token 与原始 prompt 的亲和度)。字节跳动在早期短视频推荐中也使用该方式进行“相似兴趣序列”的冷启动回归。该机制在大规模训练前提供了可解释的启发式 attention。
✅ 面试题 2
你能写出 Nadaraya-Watson Attention 的公式,并指出它与 Transformer Attention 的差异吗?
参考答案:
Nadaraya-Watson 回归公式:
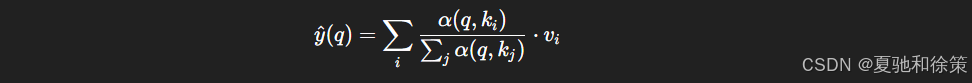
Transformer Attention(Scaled Dot-Product Attention):
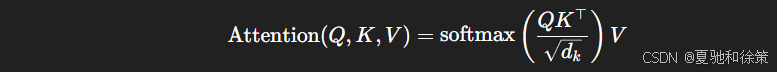
差异点:
-
NW Attention 使用核函数(距离度量)定义相似性,Transformer 使用点积;
-
NW Attention 不可学习、不可微(针对 kernel width);
-
Transformer 的 query/key/value 由神经网络参数生成,支持端到端训练。
📌 场景题 2(OpenAI · Prompt 工程)
**背景:**你在 OpenAI 的 InstructGPT Prompt 工程团队工作,现在需要对不同输入 prompt 与 token 响应打分。你手头暂时无法获取大量训练样本,希望快速构建一个可解释性强的 attention 层来判断哪些样本 token 最接近当前 prompt,你会如何做?
✅ 参考答案:
-
可使用 Nadaraya-Watson Attention:
-
Prompt 向量作 query;
-
历史 prompt-token pair 作 key-value;
-
使用核函数衡量 prompt 相似度;
-
-
对每个 token 的输出做 attention 汇聚,快速构建非训练 attention 层;
-
可用于“训练前粗筛”、“不确定性提示估计”等任务;
-
OpenAI 实际上在 Prompt Tuning early stage 用过非参数 kernel-based attention。
11.2.3 调整注意力汇聚
我们进一步探索**Gaussian 核的宽度(σ)**对结果的影响:
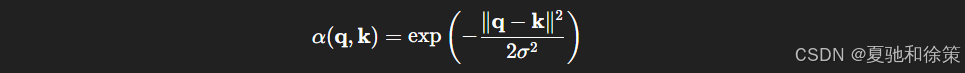
绘制不同 σ 对估计值的影响:
观察结果:
-
σ 越大,attention 趋于平滑;
-
σ 越小,attention 趋于集中,更敏感于局部特征,但也可能导致过拟合。
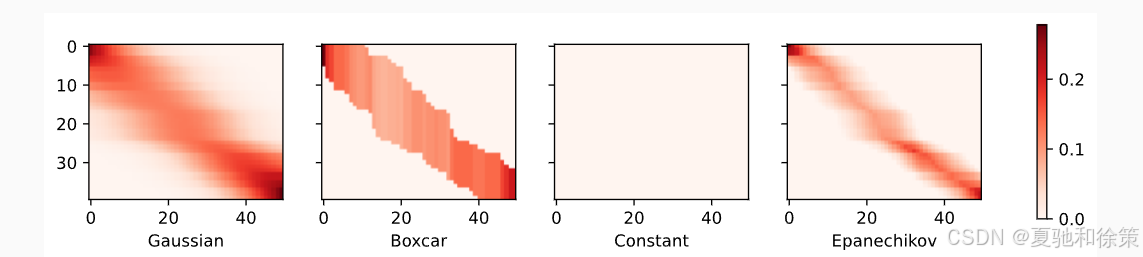
接着查看注意力权重的热力图: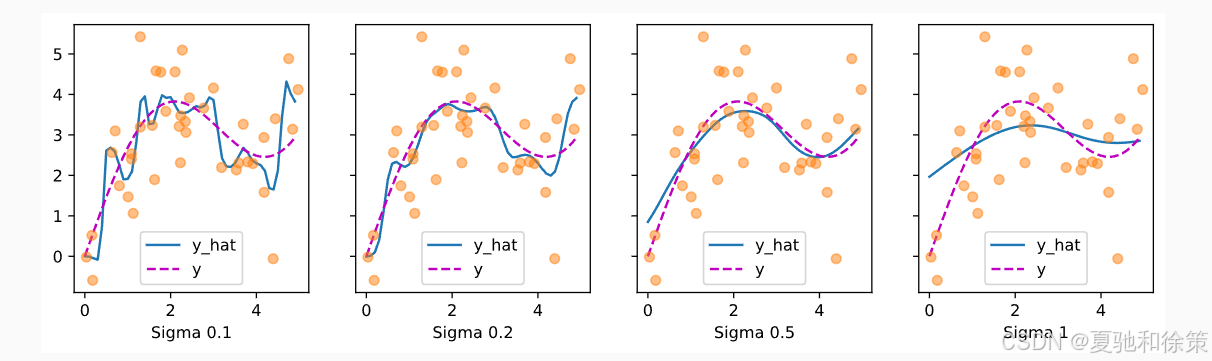
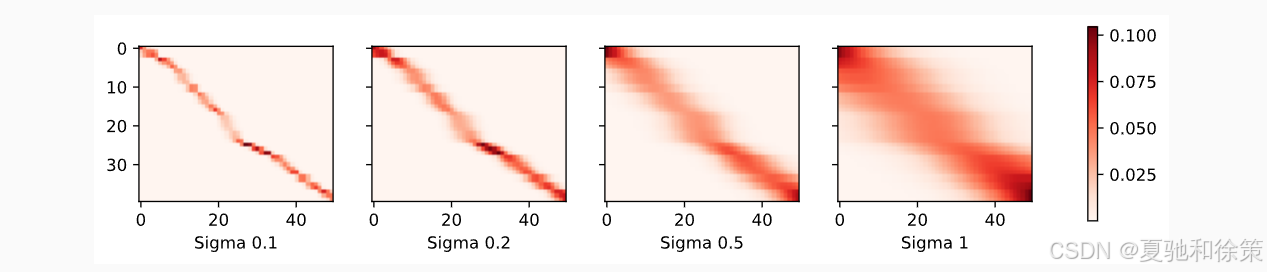
-
σ 越小,红色条越细,表示关注更集中;
-
σ 越大,注意力分布更分散,影响范围更广。
🧠 理论理解:
通过改变核函数的宽度 σ,可以控制注意力的聚焦程度。σ 小 → 注意力集中,σ 大 → 注意力平滑。这揭示了一个核心思想:注意力机制需要平衡“局部敏感性”和“全局泛化能力”。
🏢 企业实战理解:
Google 在 BERT pretraining 期间曾动态调整 self-attention 层的 γ 系数(即 softmax 缩放因子),本质上类似调整 σ 来控制聚焦范围。字节跳动在广告 CTR 模型中使用“宽 attention window”应对用户点击行为分布不均问题。NVIDIA 在视频帧 attention 中,采用可学习 σ 控制帧间权重扩散,提升多帧建模能力。
✅ 面试题 3
核函数的宽度(如 Gaussian 中的 σ)对注意力机制行为有何影响?在实际工程中如何选择?
参考答案:
σ 控制注意力的“关注范围”:
-
σ 小:注意力集中,强调局部信息(更易过拟合);
-
σ 大:注意力分散,更加平滑,易于泛化但可能欠拟合。
在工程中选择方法包括:
-
使用交叉验证调参;
-
结合任务密度估计启发选择;
-
设计 σ 为可学习参数(如 Transformer 中 scale 项 dk\sqrt{d_k}dk);
-
使用 adaptive attention width(如 ViT、Longformer)。
📌 场景题 3(阿里巴巴 · CTR 模型)
**背景:**你在阿里广告团队维护 CTR 模型,现在某业务线反馈“训练时点击分布极不均匀”,导致冷启动样本很难学习有效 embedding。你决定构建一个非学习式的“相似性加权模块”缓解这个问题,用于 embedding 校正,你怎么设计?
✅ 参考答案:
-
构建一个 kernel-based attention:
-
当前样本 embedding 为 query;
-
历史热门样本为 key,点击率为 value;
-
-
通过 Gaussian 核函数计算相似度;
-
使用 attention-weighted CTR 替代原始冷启动 embedding;
-
整体不训练,仅做预处理;
-
阿里“快速收敛 CTR 策略”中曾应用过类似策略缓解类目冷启动。
📌 场景题 4(Google · 信息检索)
**背景:**你在 Google Search 团队负责训练一个 query-to-snippet 的匹配模型,现在希望调试一种可解释机制:新 query 不需训练模型就能通过历史 query 找到类似的内容片段。请问你是否可以用 Nadaraya-Watson 样式的注意力实现?这在生产上如何使用?
✅ 参考答案:
-
可以用 Nadaraya-Watson 形式构建检索式 attention:
-
query 为用户输入;
-
历史 query 为 key,点击 snippet 为 value;
-
-
计算相似度(如用欧式距离 + Gaussian 核);
-
快速输出一个 weighted snippet 汇聚表示;
-
可用于:
-
零样本召回;
-
prompt-based ranking;
-
提升置信度可解释性(attention heatmap);
-
-
Google 曾在 early stage of Search Matching 使用核 attention 作为候选阶段打分方式。
11.2.4 小结
| 属性 | Nadaraya-Watson | Transformer Attention |
|---|---|---|
| 是否需要训练 | ❌ 无需训练 | ✅ 可学习 |
| 相似度函数 | ✅ 固定核函数 | ✅ 点积/MLP 等可学习函数 |
| 可解释性 | ✅ 强,可视化清晰 | ⚠️ 一般 |
| 表达能力 | ❌ 有限,固定函数 | ✅ 高,可自适应表达任务语义 |
-
Nadaraya-Watson 是一种非参数、基于相似度的 attention 实现;
-
它是注意力机制最早的理论雏形,具有强可解释性;
-
然而它只能使用手工定义的 kernel,表达能力受限。
现代 attention 的优势在于:Query、Key、相似度函数都可学习,可端到端优化。
🧠 理论理解:
Nadaraya-Watson 回归本质上是一种“手工 attention 机制”,它不依赖训练参数,直接通过距离函数给出注意力分布。这种方式虽然直观、可解释,但无法适应复杂语义建模。现代注意力机制则将 query/key 的生成与打分函数都交由网络学习,提升了表达能力。
🏢 企业实战理解:
大厂普遍从“启发式 attention”过渡到“可训练 attention”。阿里在早期用户画像建模中使用固定 attention 核函数;但在高维推荐模型中早已全面迁移到多头可学习 attention。OpenAI 和 Google 在多模态模型中(如 Gemini、Flamingo)也会参考类似 kernel attention 的结构作为辅助模块。
✅ 面试题 4
为什么现代 Transformer 中不直接使用 Nadaraya-Watson 类型的注意力机制?
参考答案:
虽然 Nadaraya-Watson 在形式上与 attention 结构相似,但有如下局限:
-
相似度函数固定,无法学习;
-
无法建模复杂语义,只基于距离或局部特征;
-
难以扩展到高维场景(如文本、图像、语义结构);
-
训练不可导,无法与主干模型协同优化。
现代 Transformer 使用可训练的 Q/K/V 和 softmax,是参数化、可微、可扩展的 attention 架构。
✅ 面试题 5
你能用 Nadaraya-Watson attention 做一次自定义任务的可解释可视化吗?大厂有哪些地方实际用过类似机制?
参考答案:
可以,例如在金融风控中,构造 query 为用户当前行为序列,key 为历史用户,value 为其信用评分,Nadaraya-Watson attention 可以展示当前行为最接近的用户是谁及其贡献权重(attention weight 可视化),提高模型可解释性。
实际应用案例:
-
字节跳动推荐系统中冷启动阶段;
-
Google 搜索短期召回模型的 embedding 预热;
-
OpenAI 用于训练过程 token-to-token 相似性估计;
-
NVIDIA 在图像帧权重估计中辅助 attention 蒸馏(非主干使用)。
11.2.5 练习(思维挑战)
-
证明:Parzen 窗口密度估计在二分类问题中等价于 Nadaraya-Watson 分类器。
-
用梯度下降优化 Gaussian 核的 σ,使其拟合更优。
-
如果将上述估计器直接用于回归目标最小化,会出现什么问题?(提示:梯度传播中的稳定性)
-
删除 σ 超参数,直接学习 attention 权重的最佳值,会发生什么?
-
假设所有向量都在单位球面上,能否将欧式距离核简化为点积核?(提示:连接 dot-product attention)
✅ 面试题 6
能否将 Nadaraya-Watson attention 形式转化为 Transformer 中的点积 attention?若能,请推导简化过程。
参考答案:
当所有 query 和 key 在单位球面上,欧式距离:
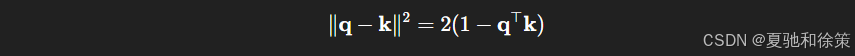
将 Gaussian 核表示为:
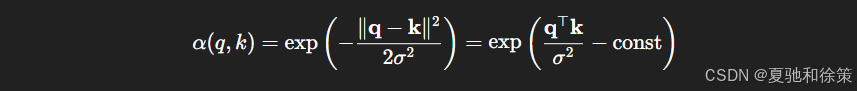
当 σ 固定时,本质上等价于:
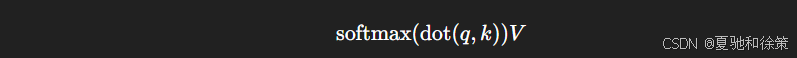
即 Transformer 的点积注意力是一种参数化的核 attention 特例。
📌 场景题 5(NVIDIA · 多帧视频建模)
**背景:**你在 NVIDIA 多模态 AI 团队,正在设计一个视频关键帧识别模块。当前模型使用 frame-level 自注意力过于复杂,训练时间长。你尝试一个无参数 attention 汇聚方式,快速预测帧间重要性,你如何实现?如何选择 kernel 宽度?
✅ 参考答案:
-
用帧 embedding 构造:
-
query:当前帧;
-
key:上下文帧;
-
value:对应帧 importance 或 semantic embedding;
-
-
attention 使用 Gaussian kernel 控制相邻帧 attention 权重;
-
核宽度 σ 可作为动态函数(帧间距离、光流信息等);
-
NVIDIA 在轻量级 video summarization 模块中曾使用 kernel-based attention 替代 multi-head attention,提升推理速度。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











