







数据标准化的意义
为了提升精度,与收敛速度。许多机器学习建模前,如果特征看起来一点都不符合标准正态分布的话,训练得到的模型可能会很糟糕。
标准化在某些比较和评价的指标处理中经常会用到,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。
min-max标准化
也称为离散标准化,是对原始数据的线性变换,将数据值映射到[0, 1]之间。
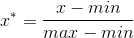
Z-score标准化
经过处理的数据的均值为0,标准差为1
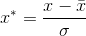
x:观测值
x_:总体平均值
σ:总体标准差
缺点:总体平均值和方差不一定可知,结果没有实际意义,只能用于比较。
sklearn中fit_transform, fit, transform区别
- fit():求得训练集X的均值,方差,最大值,最小值,这些训练集X固有的属性。
- transform():在fit的基础上,进行标准化,降维,归一化等操作(看具体用的是哪个工具,如PCA,StandardScaler等)。
- fit_transform():fit_transform是fit和transform的组合,既包括了训练又包含了转换。
transform()和fit_transform()二者的功能都是对数据进行某种统一处理(比如标准化~N(0,1),将数据缩放(映射)到某个固定区间,归一化,正则化等)
fit_transform(trainData)对部分数据先拟合fit,找到该part的整体指标,如均值、方差、最大值最小值等等(根据具体转换的目的),然后对该trainData进行转换transform,从而实现数据的标准化、归一化等等。
根据对之前部分trainData进行fit的整体指标,对剩余的数据(testData)使用同样的均值、方差、最大最小值等指标进行转换transform(testData),从而保证train、test处理方式相同。所以,一般都是这么用:
# 从sklearn.preprocessing导入StandardScaler
from sklearn.preprocessing import StandardScaler
# 标准化数据,保证每个维度的特征数据方差为1,均值为0,使得预测结果不会被某些维度过大的特征值而主导
ss = StandardScaler()
# fit_transform()先拟合数据,再标准化
X_train = ss.fit_transform(X_train)
# transform()数据标准化
X_test = ss.transform(X_test)














 574
574











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









