








一、写在前面
并行计算的入门文章非劳伦斯利弗莫尔国家实验室(LLNL)的《Introduction to Parallel Computing Tutorial》[1]所属,于是本着学习的态度,笔者对其进行了翻译,以下是《Introduction to Parallel Computing Tutorial》的中文版,篇幅限制,本篇博客仅包含C. 并行计算机内存架构和D. 并行编程模型两部分,为《Introduction to Parallel Computing Tutorial》的第二部分,共四部分。
【高性能计算背景】《并行计算教程简介》翻译 - 中文 - 1 / 4
【高性能计算背景】《并行计算教程简介》翻译 - 中文 - 2 / 4
【高性能计算背景】《并行计算教程简介》翻译 - 中文 - 3 / 4
【高性能计算背景】《并行计算教程简介》翻译 - 中文 - 4 / 4
二、摘要
这是“利弗莫尔计算入门”研讨会的第一篇教程。本文旨在简要概述并行计算这一广泛而宽泛的主题,作为后续教程的导读。因此,它只涵盖并行计算的基本知识,面向刚刚熟悉该主题并计划参加本研讨会的一个或多个其他教程的人。它并不打算深入讨论并行编程,因为这将需要更多的时间。本教程首先讨论并行计算 - 它是什么以及如何使用,然后讨论与并行计算相关的概念和术语。然后探讨了并行内存体系结构和编程模型的主题。这些主题之后是一系列关于设计和运行并行程序的复杂问题的实际讨论。本教程最后给出了几个如何并行处理几个简单问题的示例。包括参考文献,以供进一步自学。
A. 并行计算概述
1. 什么是并行计算?
2. 为什么使用并行计算?
3. 谁在使用并行计算?
B. 概念和术语
1. 冯诺依曼计算机体系结构
2. 弗林分类法
3. 通用并行计算术语
4. 并行编程的潜在好处、限制和成本
C. 并行计算机内存架构
1. 共享内存
常规特性
- 共享内存并行计算机差别很大,但通常都有一个共同点,即所有处理器都可以访问所有内存作为全局地址空间。
- 多个处理器可以独立运行,但共享相同的内存资源。
- 由一个处理器影响的内存位置变化对所有其他处理器都可见。
- 历史上,共享内存机器根据内存访问时间分为UMA和NUMA。
笔者记:UMA具有相等的内存访问时间, NUMA具有不同的存储器访问时间,访问不同节点存储的数据时。[2]
统一内存访问(UMA)
- 今天最常见的是对称多处理器(SMP)机器
- 相同的处理器
- 对内存的访问和访问时间相等
- 有时称为CC - UMA - 缓存一致性 UMA。缓存一致性意味着,如果一个处理器更新共享内存中的一个位置,则所有其他处理器都知道该更新。缓存一致性是在硬件级别实现的。
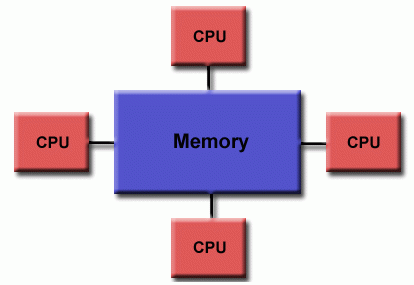
统一内存访问 👆
非统一内存访问 (NUMA)
- 通常通过物理连接两个或多个 SMP 来实现
- 一个 SMP 可以直接访问另一个 SMP 的内存
- 并非所有处理器对所有内存都有相同的访问时间
- 跨链路的内存访问速度较慢
- 如果保持缓存一致性,那么也可以称为 CC - NUMA - 缓存一致性 NUMA
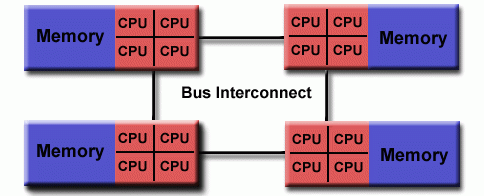
非统一内存访问 👆
优点
- 全局地址空间为内存提供了用户友好的编程视角。
- 由于内存接近CPU,任务之间的数据共享既快速又统一。
缺点
- 主要缺点是内存和CPU之间缺乏可伸缩性。添加更多CPU可以成几何级数地增加共享内存CPU路径上的通信量,对于缓存一致性系统,成几何级数地增加与缓存/内存管理相关的通信量。
- 程序员负责确保全局内存
正确访问的同步构造。
2. 分布式内存
常规特性
- 与共享内存系统一样,分布式内存系统差异很大,但具有共同的特征。分布式内存系统需要一个通信网络来连接处理器间内存。
- 处理器有自己的本地内存。一个处理器中的内存地址不会映射到另一个处理器,因此没有跨所有处理器的全局地址空间的概念。
- 因为每个处理器都有自己的本地内存,所以它独立运行。它对其本地内存所做的更改对其他处理器的内存没有影响。因此,缓存一致性的概念不适用。
- 当一个处理器需要访问另一个处理器中的数据时,程序员的任务通常是明确定义数据通信的方式和时间。任务之间的同步同样是程序员的责任。
- 用于数据传输的网络
结构千差万别,尽管它可以像以太网一样简单。
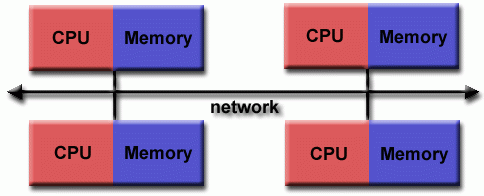
分布式内存 👆
优点
- 内存可以根据处理器的数量进行扩展。增加处理器数量,内存大小将按比例增加。
- 每个处理器都可以快速访问自己的内存,而不会受到干扰,也不会因试图保持全局缓存一致性而产生开销。
- 成本效益:可以使用商品,非专门设计的处理器和网络。
缺点
- 程序员负责与处理器之间的数据通信相关的许多细节。
- 可能很难将基于全局内存的现有数据结构映射到此内存组织。
- 非统一内存访问时间—驻留在远程节点上的数据访问时间比节点本地数据长。
3. 混合分布式共享内存
常规特性
- 当今世界上最大、速度最快的计算机采用共享和分布式内存体系结构。
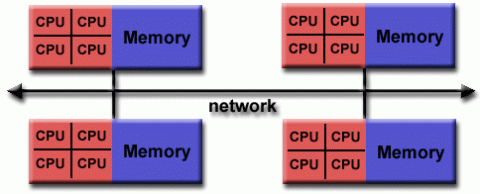
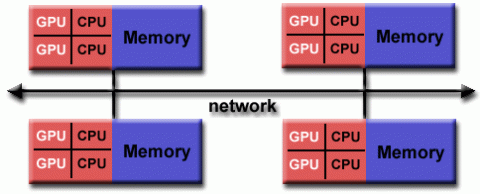
- 共享内存组件可以是共享内存机器
和/或图形处理单元(GPU)。 - 分布式内存组件是多个共享内存/GPU机器的网络,这些机器只知道自己的内存,而不知道另一台机器上的内存。因此,需要网络通信来将数据从一台机器移动到另一台机器。
- 当前的趋势似乎表明,在可预见的未来,这种类型的内存体系结构将继续占主导地位,并在高端计算中不断增加。
优点和缺点
- 共享和分布式内存体系结构的共同点。
- 增长的可扩展性是一个重要优点
- 程序员变成复杂性的增加是一个重要的缺点
D. 并行编程模型
- 有几种常用的并行编程模型:
- 共享内存(无线程)
- 线程
- 分布式内存/消息传递
- 数据并行
- 混合
- 单程序多数据流 (SPMD)
- 多程序多数据流 (MPMD)
- 并行编程模型作为硬件和内存架构之上的抽象存在。
- 虽然这些模型看起来并不明显,但它们并不特定于特定类型的机器或内存体系结构。事实上,这些模型中的任何一个(理论上)都可以在任何底层硬件上实现。下面讨论过去的两个例子。
分布式内存机器上的共享内存模型
- Kendall Square Research (KSR) ALLCACHE 方法。机器内存物理上分布在由网络连接的的机器上,但在用户看来,它是一个单一的共享内存全局地址空间。一般来说,这种方法被称为
虚拟共享内存。

共享内存机器上的分布式内存模型
- SGI Origin 2000 上的消息传递接口 (MPI)。SGI Origin 2000 采用 CC-NUMA 类型的共享内存架构,其中每个任务都可以直接访问分布在所有机器上的全局地址空间。然而,使用MPI发送和接收消息的能力已经实现并普遍使用,这通常是通过分布式内存机器网络完成的。

- 使用哪种型号? 这通常是什么是可用的和个人选择的结合。没有
最佳模型,尽管某些模型的实现肯定优于其他模型。 - 以下各节描述了上述每个模型,并讨论了它们的一些实际实现。
1. 共享内存模型
-
在这个编程模型中,
进程/任务共享一个公共地址空间,它们异步读写地址空间。
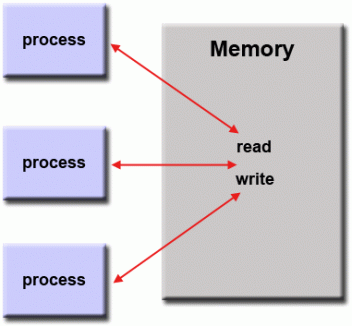
-
使用
锁/信号量等各种机制来控制对共享内存的访问、解决冲突并防止竞争条件和死锁。 -
这可能是最简单的并行编程模型。
-
从程序员的角度来看,该模型的一个优点是缺少数据
所有权的概念,因此没有必要明确指定任务之间的数据通信。所有进程都可以看到共享内存,并且对共享内存具有同等的访问权限。程序开发通常被简化。 -
性能方面的一个重要缺点是更难理解和管理数据局部性:
- 将数据保持在其上工作的进程的本地,可以节省多个进程使用相同数据时发生的内存访问、缓存刷新和总线通信。
- 不幸的是,控制数据局部性很难理解,可能超出了普通用户的控制范围。
应用
- 在独立共享内存机器上,本机操作系统、编译器
和/或硬件为共享内存编程提供支持。例如,POSIX标准提供了使用共享内存的API,UNIX提供了共享内存段(shmget、shmat、shmctl等)。 - 在分布式内存机器上,内存物理上分布在机器网络上,但通过专门的硬件和软件实现了全局化。可以使用多种SHMEM实现如下:http://en.wikipedia.org/wiki/SHMEM.
2. 线程模型
- 这种编程模型是一种共享内存编程。
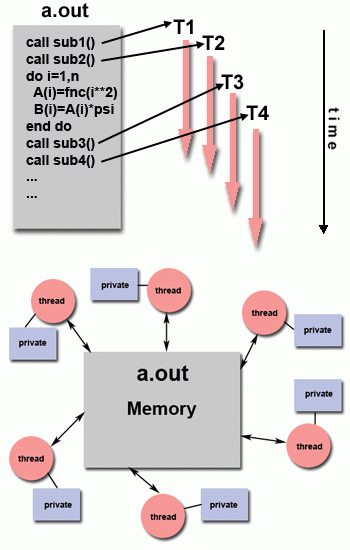
线程模型 👆
-
在并行编程的线程模型中,一个“重量级”进程可以有多个“轻量级”并发执行路径。
-
例如:
- 主程序a.out由本机操作系统调度运行。a.out加载并获取运行所需的所有系统和用户资源。这就是“重量级”过程。
- a.out执行一些串行工作,然后创建一些任务(线程),这些任务(线程)可以由操作系统同时调度和运行。
- 每个线程都有本地数据,但也共享a.out的全部资源。这节省了与为每个线程复制程序资源相关的开销(“轻量级”)。每个线程还受益于全局内存视图,因为它共享a.out的内存空间。
- 线程的工作最好描述为主程序中的一个子例程。任何线程都可以与其他线程同时执行任何子例程。
- 线程通过全局内存相互通信(更新地址位置)。这需要同步概念来确保多个线程在任何时候都不会更新相同的全局地址。
- 线程可以来来去去,但在应用程序完成之前,存在一个a.out来提供必要的共享资源。
应用
- 从编程角度来看,线程实现通常包括:
- 从并行源代码中调用的子程序库
- 嵌入在串行或并行源代码中的一组编译器指令
在这两种情况下,程序员应该负责确定并行性(尽管编译器有时会有所帮助)。
- 线程化实现在计算领域并不新鲜。过去,硬件供应商已经实现了自己的线程专有版本。这些实现之间存在着巨大的差异,这使得程序员很难开发可移植的线程应用程序。
- 不相关的标准化工作导致了两种截然不同的线程实现:POSIX Threads 和OpenMP。
POSIX Threads
- 由IEEE POSIX 1003.1c standard (1995)规定。仅限C语言。
- Unix/Linux操作系统的一部分
- 基于库
- 通常称为Pthreads。
- 非常明确的并行性;需要程序员非常注意细节。
OpenMP
- 行业标准,由一组主要计算机硬件和软件供应商、组织和个人共同定义和认可。
- 基于编译器指令
- 轻便 / 多平台,包括Unix和Windows平台
- 在C/C++和Fortran中可用
- 可以非常容易和简单地使用 —— 提供
增量并行。可以从串行代码开始。 - 其他线程化实现很常见,但此处不讨论:
- Microsoft线程
- Java、Python线程
- GPU的CUDA线程
更多信息
- POSIX Threads 教程: https://hpc.llnl.gov/sites/default/files/2019.08.21.TAU_.pdf [3]
- OpenMP 教程:https://hpc-tutorials.llnl.gov/openmp/ [4]
3. 分布式内存/消息传递模型
该模型具有以下特点:
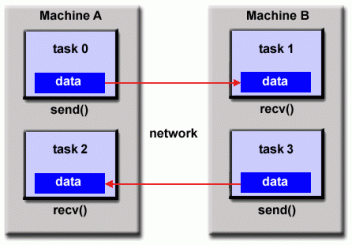
分布式内存模型 👆
- 在计算过程中使用其自身本地内存的一组任务。多个任务可以驻留在同一台物理计算机上
和/或跨任意数量的计算机。 - 任务通过发送和接收消息,通过通信交换数据。
- 数据传输通常需要每个进程执行协作操作。例如,发送操作必须具有匹配的接收操作。
应用
- 从编程的角度来看,消息传递实现通常包含一个子程序库。对这些子例程的调用嵌入在源代码中。程序员负责确定所有并行性。
- 从历史上看,自20世纪80年代以来,已有各种消息传递库可用。这些实现之间存在着巨大的差异,这使得程序员很难开发可移植的应用程序。
- 1992年,MPI论坛成立,其主要目标是为消息传递实现建立一个标准接口。
- 消息传递接口(MPI)的第1部分于1994年发布。第2部分(MPI-2)于1996年发布,MPI-3于2012年发布。所有MPI规范可在以下网站上获得:http://www.mpi-forum.org/docs/ [5].
更多信息
- MPI教程:https://hpc-tutorials.llnl.gov/mpi/ [6]
4. 数据并行模型
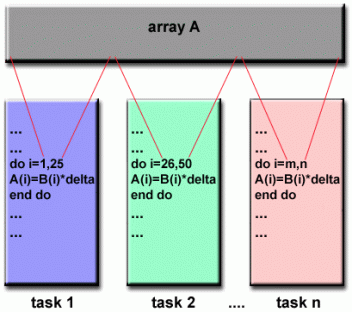
数据并行模型 👆
-
也可称为分区全局地址空间(Partitioned Global Address Space,PGAS)模型。
-
数据并行模型具有以下特点:
- 地址空间以全局方式处理
- 大多数并行工作集中于对数据集执行操作。数据集通常被组织成一个公共结构,例如数组或多维数据集。
- 一组任务在同一数据结构上共同工作,但是,每个任务在同一数据结构的不同分区上工作。
- 任务在其工作分区上执行相同的操作,例如,“向每个数组元素添加4”。
-
在共享内存体系结构上,所有任务都可以通过全局内存访问数据结构。
-
在分布式内存体系结构上,全局数据结构可以在任务之间进行逻辑
和/或物理拆分。
应用
- 目前,基于数据并行/PGAS模型,在开发的不同阶段有几个并行编程实现。
- Coarray Fortran:Fortran 95的一小部分扩展,用于SPMD并行编程。编译器相关。更多信息:https://en.wikipedia.org/wiki/Coarray_Fortran
- Unified Parallel C (UPC):用于SPMD并行编程的C编程语言的扩展。编译器相关。更多信息:https://upc.lbl.gov/
- Global Arrays:在分布式数组数据结构的上下文中提供共享内存风格的编程环境。具有C和Fortran77绑定的公共域库。更多信息:https://en.wikipedia.org/wiki/Global_Arrays
- X10:IBM在Thomas J.Watson研究中心开发的一种基于PGAS的并行编程语言。更多信息:http://x10-lang.org/
- Chapel:由Cray领导的开源并行编程语言项目。更多信息:http://chapel.cray.com/
5. 混合模型
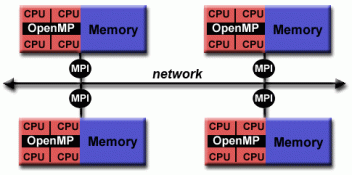
MPI和OpenMP的混合模型 👆
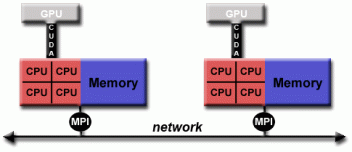
MPI和CUDA的混合模型 👆
- 混合模型结合了前面描述的多个编程模型。
- 目前,混合模型的一个常见示例是消息传递模型(MPI)与线程模型(OpenMP)的组合。
- 线程使用本地节点数据执行计算密集型内核
- 使用MPI通过网络在不同节点上的进程之间进行通信
- 这种混合模式非常适合最流行(当前)集群式
多核 / 众核机器的硬件环境。 - 混合模型的另一个类似且日益流行的示例是使用MPI和CPU-GPU(图形处理单元)编程。
- MPI任务使用本地内存在CPU上运行,并通过网络相互通信。
- 计算密集型内核卸载到节点上的GPU。
- 节点本地内存和GPU之间的数据交换使用CUDA(或类似的东西)。
- 其他混合模型也很常见:
- 使用Pthreads的MPI
- 使用非GPU加速器的MPI
6. SPMD 和 MPMP
单程序多数据流(SPMD)
- SPMD实际上是一种
高级编程模型,它可以建立在前面提到的并行编程模型的任何组合之上。
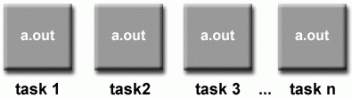
SPMD 模型
- 单程序:所有任务同时执行同一程序的副本。该程序可以是线程、消息传递、数据并行或混合。
- 多数据:所有任务可能使用不同的数据
- SPMD程序通常具有必要的编程逻辑,以允许不同的任务分支或有条件地仅执行其设计要执行的程序部分。也就是说,任务不一定要执行整个程序 - 也许只执行其中的一部分。
- 使用消息传递或混合编程的SPMD模型可能是多节点集群最常用的并行编程模型。
多程序多数据流(MPMD)
- 与SPMD一样,MPMD实际上是一个
高级编程模型,可以在前面提到的并行编程模型的任何组合上构建。

- 多程序:任务可以同时执行不同的程序。程序可以是线程、消息传递、数据并行或混合。
- 多数据:所有任务可能使用不同的数据
- MPMD应用程序不像SPMD应用程序那样常见,但可能更适合某些类型的问题,尤其是那些比区域分解更适合于功能分解的问题(稍后在分区中讨论)。
E. 设计并行程序
1. 自动并行 vs. 手动并行
2. 理解问题和程序
3. 分解
4. 通讯
5. 同步
6. 数据依赖
7. 负载均衡
8. 粒度
9. I/O
10. 调试
11. 性能分析和调优
F. 并行示例
1. 数组处理
2. 计算PI
3. 简单热方程
4. 一维波动方程
G. 参考资料和更多信息
四、总结
《并行计算教程简介》的C章节主要介绍了三种并行计算机的内存架构,是一些基本的体系结构知识。D章节讲了流行的并行编程模型及其应用,跟着作者一步步将知识串联的感觉太酷了。
以上就是今天要分享的内容,本文翻译了《并行计算教程简介》的C、D两个章节,笔者一人翻译难免有翻译的不足之处,望海涵 😐 。
如果本文能给你带来帮助的话,点个赞鼓励一下作者吧! 😐
五、参考
[1] Lawrence Livermore National Laboratory:https://hpc.llnl.gov/documentation/tutorials/introduction-parallel-computing-tutorial
[2] UMA和NUMA之间的区别: https://www.nhooo.com/note/qa04wu.html
[3] POSIX Threads 教程: https://hpc.llnl.gov/sites/default/files/2019.08.21.TAU_.pdf
[4] OpenMP 教程:https://hpc-tutorials.llnl.gov/openmp/
[5] MPI规范:http://www.mpi-forum.org/docs/
[6] MPI教程:https://hpc-tutorials.llnl.gov/mpi/















 1180
1180











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









