






 本文综述了基于信息熵的特征选择算法,包括BIF、MIFS、mRMR、MIFS-U、mMIFS-U、FCBF、DDC、CMIM、DISR、NMIFS、MIFS-CR和QMIFS-p等,探讨了各算法如何衡量特征与类别相关性和特征间冗余度。
本文综述了基于信息熵的特征选择算法,包括BIF、MIFS、mRMR、MIFS-U、mMIFS-U、FCBF、DDC、CMIM、DISR、NMIFS、MIFS-CR和QMIFS-p等,探讨了各算法如何衡量特征与类别相关性和特征间冗余度。
绪论
特征选择的目标是从样本数据集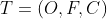 的原始特征F中寻找一个子集S,使得它包含尽可能多的类区分信息,即包含更多与类别C有关的知识,同时又使得子集内部的冗余程度尽量小。定义信息度量函数J(f),其目的是在原始特征集F内选择子集S,保证其与类别C之间相关性程度最大,同时又保证子集S内部的冗余性最小。
的原始特征F中寻找一个子集S,使得它包含尽可能多的类区分信息,即包含更多与类别C有关的知识,同时又使得子集内部的冗余程度尽量小。定义信息度量函数J(f),其目的是在原始特征集F内选择子集S,保证其与类别C之间相关性程度最大,同时又保证子集S内部的冗余性最小。
为了方便起见,下面先对几个常用的符号做一简单约定:符号F和S分别表示未选的和已选的特征子集,C表示分类类别, 和
和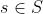 分别表示候选和已选的特征。
分别表示候选和已选的特征。
不失一般性候选特征f的信息度量函数J(f)可表示为如下形式:
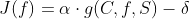
其中函数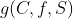 为候选特征f、类别C和已选子集S之间的信息量。它主要用来表示f加入S后,S与C之间的相关程度,即f能给S带来关于C的信息量。通常情况下,为互信息
为候选特征f、类别C和已选子集S之间的信息量。它主要用来表示f加入S后,S与C之间的相关程度,即f能给S带来关于C的信息量。通常情况下,为互信息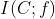 或条件互信息
或条件互信息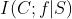 的形式。α是调控系数,它主要用于调节f所带来信息量的程度,δ是惩罚因子,用于惩罚候选特征f给已选子集S带来的冗余程度。他经常以f、C和单个已选特征s之间的互信息的形式出现。
的形式。α是调控系数,它主要用于调节f所带来信息量的程度,δ是惩罚因子,用于惩罚候选特征f给已选子集S带来的冗余程度。他经常以f、C和单个已选特征s之间的互信息的形式出现。
由上式可知,倘若候选特征f能给S带来更多信息(即上式中第一项越大),并且S产生较小的冗余性(即上市中第二项越大),那么他就是一个较好的特征(上式中J(f)越大),该特征将被优先选择。
基于信息论的特征选择算法
1、BIF算法
BIF(Best Individual Feature)[3]是一种最简单也是最直观的特征选择算法,他的评估函数J(f)就是互信息本身,即J(f)=I(C;f)。BIF选择算法的思想很简单,他首先对所有候选特征f计算其评价函数J(f),并根据函数值按降序顺序排序,然后选择前k个特征组成选择子集S。BIF算法的优点是效率高,因此他适合于高维数据情况,如文本分类等。他也经常用于混合选择方法的预处理步骤中,以预先过滤不重要的特征。BIF的缺点也很明显,比如他没有考虑特征之间的相互关联和冗余性等。
2、MIFS(Mutual Information based Feature Selection)
由于BIF算法未考虑特征的冗余性,如果S已经包含了特征f的信息量,所以f相对于S来说是无用的。另外,多个单独最优的特征组合在一起时,其性能也未必是最优的。Battiti R.于1994提出基于互信息的特征选择算法MIFS[4]。MIFS算法使用互信息度量候选特征与类别之间的相关性,以及与已选特征集合直接按的冗余性,以贪心策略选择与类别相关性强且已选特征冗余度低的特征集合。
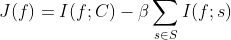
其中β 为惩罚因子,当β 取不同值时,MIFS算法性能波动较大,当β∈[0.5, 1] 时,算法性能较优。
3、mRMR(minimal redundancy maximum relevance)
与MIFS算法类似,mRMR算法[5]也采用互信息作为候选特征f与类别C之间相关性以及与已选特征集合S之间冗余性的度量标准,并且针对MIFS算法惩罚因子β 难以确定的问题,mRMR算法采用候选特征与已选特征的平均互信息作为冗余度的估值,即惩罚因子为1/|S| 。mRMR算法于2005年由Peng等人提出,评价函数为:
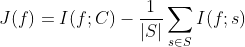
通过于单个已知特征s的相关性衡量f的重要性程度。
4、MIFS-U(Mutual Information Feature Selection Under Uniform Information Distribution)
Kwak和Choi指出MIFS选择算法中评价函数J(f)的惩罚因子并不能准确地表达冗余程度的增长量。为此,他们在MIFS-U算法[6]中使用不确定性系数CU(f,s)描述f与s之间的相关冗余程度,其中CU(f,s)=I(f,s)/H(s)。另外,他们还将已选择特征s与类别C之间的相关程度也纳入惩罚因子中。总之,MIFS-U算法的特征度量标准是:
![]()
与mRMR的做法类似,Huang等将公式中的β 替换为1/|S|,并结合遗传算法生成候选子集,然后利用支持向量机获取较好的分类效果。
算法5:mMIFS-U
与MIFS算法类似,MIFS-U算法中参数β 的取值将影响算法性能,而β 具体取什么值是件很棘手的事情。为了解决这个问题,Novovicova等提出MIFS-U的一种改进算法,称做mMIFS-U。它并不是利用f与s相关程度值和作为f与S的冗余程度,而实将f与S中单个已选特征相关程度最大的s作为他们之间的冗余程度。简言之,mMIFS-U就是采用max函数取代求和操作,即:
![]()
算法6:FCBF
FCBF是Yu和Liu提出的一种基于相关性的特征选择算法。它借助Markov blanket技术判定特征间的相似性,从而达到快速消除冗余特征的目的。在FCBF算法中,特征之间冗余性和特征与类别之间的相关程度都是通过对称不确定性(Symmetrical Uncertainty, SU)度量的。对称不确定性是互信息的一种归一化表示形式,用于客服互信息固有的缺点,即互信息标准倾向于哪些具有多值的特征。给定类别C,特征f与C的对称不确定性为:
![]()
这个函数就是FCBF算法的评价标准J(f),只不过在确定候选特征f是否冗余时,还需判断SU(s,f)<SU(C,f)是否成立。若不等式成立,则f是一个重要的特征;反之,f是冗余的。
算法7:DDC
Qu 等指出对称不确定性并没有涉及 f 与 S 之间的冗余程度,这可能导致一种情况,即选择过程会提供一些错误或不完全的信息。为此,他们提出决策依赖相关性来精确度量特征f和s间的依赖程度,即:
![]()
在他们提出的特征选择算法中,I(C;f)和QC(f,s) 共同构成特征评价标准,即一个好的特征f,它的I(C;f)不仅最大,且对于任意已选特征s,QC(f,s) 同时最小。等价地,他们的标准 J(f)可以表示为如下形式:
![]()
算法8:CMIM(Conditional mutual information)
条件互信息也常被引入到特征选择算法中,其中最著名的就是与2004年由Fleuret提出的CMIM算法。条件互信息适用于度量在某些变量一直的情况下,变量或者变量集合所包含的关于目标变量的信息量。在变量Z已知的情况下,变量X与目标Y的条件互信息定义如下:
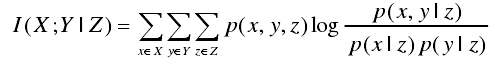
根据定义,条件互信息在计算新变量所提供的关于目标变量的信息量的似乎后,将已知变量所提供的信息量考虑在内,即考虑了变量之间按的依赖关系,这对特征选择来说非常适用。
CMIM算法认为候选特征f是值得选择的,当且仅当f提供了已选特征集合S所不包含的关于类别C的信息量,即特征评价函数为I(f; C|S),且条件互信息值越大,表示特征f包含的新信息越多。考虑到I(f;C|S)的计算代价较高,Fleuret采取了一种变通的方式,即使用单个已选特征s代替整个已选特征集合S,其中s的选择标准是使得I(f;C|s)取得最小值。由条件互信息的定义可知,如果f不包含新信息,即S中的特征包含了f所能提供的所有信息量时,I(f;C|s)取得最小值。选择s代替S,目的是将I(f;C|s)作为f所提供新信息量的保守估计。然后按照启发式规则,一次从候选特征集合F中选择使I(f;C|s)取得最大值的特征f。CMIM算法的特征评价函数为:
![]()
算法9:DISR
DISR选择算法使用另一种归一化的互信息SR(C;S) 度量S与C之间的相关程度,其中SR(C;S)=I(C;S)/ H(C,S)。另外,为了解决熵的计算困难问题,他们利用子集中单个已选特征与类别的标准化互信息之和代替SR(C;S)。因此,DISR的评价函数表示为:
![]()
算法10:NMIFS
Estévez等人于2009年提出MIFS算法的更进一步改进算法—NMIFS(Normalized Mutual Information based Feature Selection)。由于互信息准则对可取值较多的属性有所偏好,为减少这种拼啊好可能带来的不利影响,NMIFS算法采用“标准化”的互信息度量候选特征f和已知特征S之间的冗余度,并把惩罚因子设为1/|S|。NMIFS算法特征评价函数为:
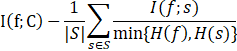
其中H(·)表示信息熵。
算法11:MIFS-CR
Wang 等人于 2015 年提出了 MIFS 算法的最新改进算法 MIFS-CR (Mutual Information based Feature Selection with Class-dependent Redundancy),相较于 MIFS,MIFS-CR 仍采用互信息度量特征 f 与类别 C 之间的相关性,不同的是,该算法采用了一种更为精确的度量方式计算特征 f 与已选特征集合 S 之间的冗余程度,并且将特征子集的相关性度量函数和冗余度度量函数作为多目标优化算法的两个目标优化函数,将最终求得的相关性最大、冗余度最低的 Pareto 最优解作为所选特征子集,取得了较好的结果。MIFS-CR 算法的特征评价函数为:
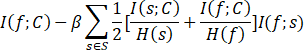
算法12:QMIFS-p
与MIFS-CR算法不同的是,QMIFS-p直接使用I(C;f,S)评估候选特征f的重要程度。为了避免已选子集S的冗余性,该算法还计算f与s之间的相关性r(f,s)。如果f与S中已选特征s的最大相关系数r(f,s)大于给定的阈值,那么f就被认为是冗余或无用的。这种提出冗余特征的做法与FCBF类似,都是采取两步骤实现。此外,作者在估计I(C;f,S)时使用高斯核技术。总之,QMIFS-p的评价函数如下所示:
![]()
结语
此部门对于基于信息熵做特征选择比较全的一个总结,来源于吉林大学刘华文博士论文《基于信息熵的特征选择算法研究》。

















 2018
2018

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









