







从1980年到2021年,中国的GDP总量以不变价格计算增长了40倍,年平均增长率超过9%,相当于平均每8年GDP总量翻一番。中国的GDP增速在1984年、1992年和2007年达到了最高峰,分别达到了15.2%、14.277%和14.247%。
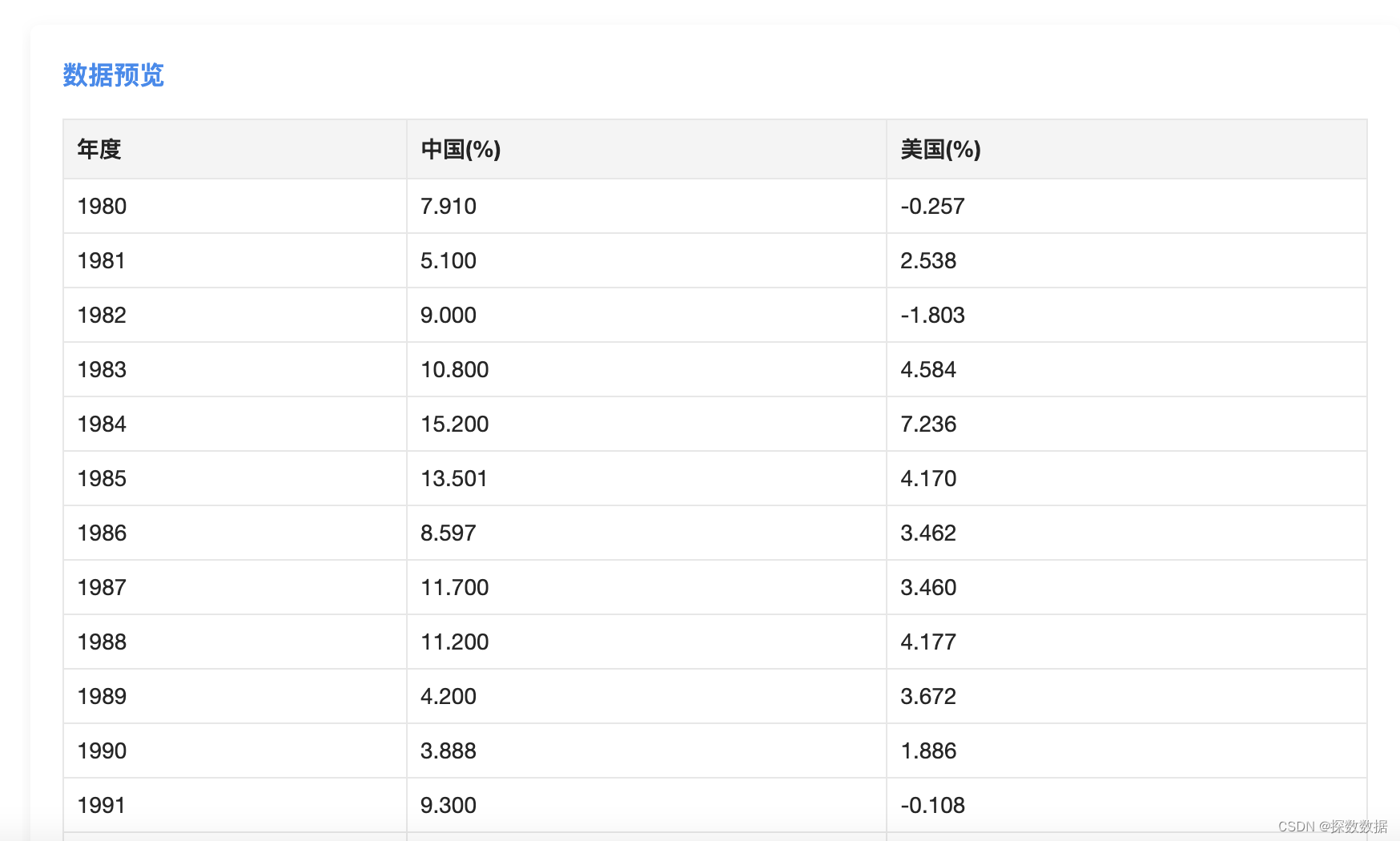
从1980年到2021年,中国的GDP总量以不变价格计算增长了40倍,年平均增长率超过9%,相当于平均每8年GDP总量翻一番。中国的GDP增速在1984年、1992年和2007年达到了最高峰,分别达到了15.2%、14.277%和14.247%。
 1万+
830
853
1万+
830
853











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言
























