







KMP算法
1.普通比较算法
首先我们先来了解普通的比较算法
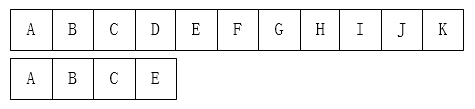
从左到右一个一个匹配,先从第一位比较,能完全匹配则返回匹配位置,反之子串向右移动一位,继续匹配,直到匹配主串结束。
如下图: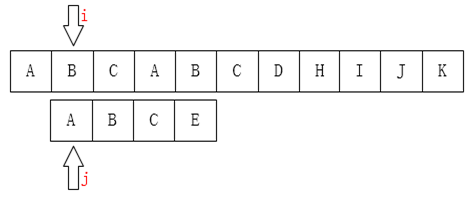
根据以上可以得到以下代码(暴力匹配,逻辑简单):
/**
* 暴力破解法
* @param ts 主串
* @param ps 模式串
* @return 如果找到,返回在主串中第一个字符出现的下标,否则为-1
*/
public static int bf(String ts, String ps) {
char[] t = ts.toCharArray();
char[] p = ps.toCharArray();
int i = 0; // 主串的位置
int j = 0; // 模式串的位置
while (i < t.length && j < p.length) {
if (t[i] == p[j]) { // 当两个字符相同,就比较下一个
i++;
j++;
} else {
i = i - j + 1; // 一旦不匹配,i后退
j = 0; // j归0
}
}
if (j == p.length) {
return i - j;
} else {
return -1;
}
}
这种方法太过于笨拙,我们可以看到明明第二位已经匹配,而且和第一位明显不同,但是计算机还是要匹配一次,这就造成了计算复杂度的提升,所有聪明的人研究出了KMP算法,来避免重复匹配。
== 暴力破解 的时间难度是O(n*m)==
2.KMP算法
参考下图
核心思维:利用已经部分匹配这个信息,保持i指针不变,通过修改J指针,让模式串移动到有效位置。换句话说,在某个字符与主串不匹配的时候,我们要知道指针移动到哪里。

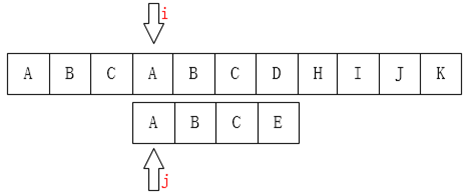
我们可以看到C和B不匹配了,这时候我们该怎么做?
我们可以直接将 j 指针移动到第二位,因为我们可以明显看到前两位都是一样的,以上可得:最前面的 K 个字符和之前的最后 K 个字符是一样的
P[0~K-1] == P[j-k ~ j-1]
PS:我在此将已经匹配的 K 个字符可以看做最大重复前缀
综上所述,我们需要一个新的指标来指示我们该移动到哪个有效位置,所以就推出NEXT数组,他的作用是可以指定在失配(匹配失败)之后, j 指标该移动的位置。
以下是公式验证前缀相同的证明:
(可看可不看,因为图片上肉眼一眼就能看出来)
因为:
当T[i] != P[j]时
有T[i-j ~ i-1] == P[0 ~ j-1]
由P[0 ~ k-1] == P[j-k ~ j-1]
必然:T[i-k ~ i-1] == P[0 ~ k-1]
我们可以看出,在失配之后,直接将j 移动到 k 值,就可以获得有效匹配。
使用next数组表示:
next[j] = k,表示当T[i] != P[j]时,j指针的下一个位置
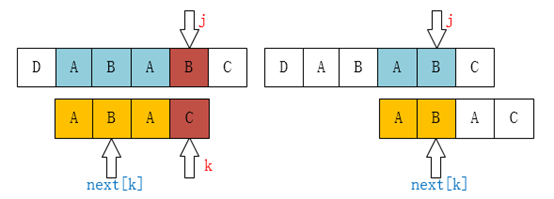
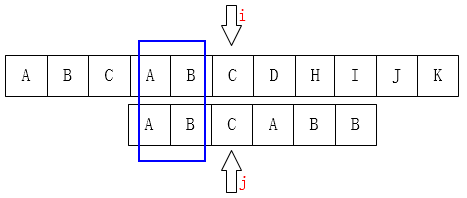
例如图上,已经匹配成功A、B、A三位,但是B和C没有匹配成功,这时候引进next[k]=j
让子串从P[next[k] = j ] 开始匹配,子串继续从i= 0开始匹配,匹配上则继续,反之则把j+1赋给next[k] ,然后重复以上操作,直至最后母串所有字符结束一次匹配。
时间复杂度O(n+m)
比较容易理解的一种方法,最大前/后缀
首先简单说下前后缀的概念,
"前缀"指除了最后一个字符以外,一个字符串的全部头部组合;
"后缀"指除了第一个字符以外,一个字符串的全部尾部组合。

部分匹配的实质是,有时候,字符串头部和尾部会有重复,比如,“ABCDAB”之中有两个“AB”,它的部分匹配值就是2,(”AB”的长度)搜索词移动的时候,第一个“AB”向后移动四位(字符串长度-部分匹配值),就到了第二个匹配“AB”的位置
下附代码:
#coding=utf-8
def kmp(mom_string, son_string):
# 传入一个母串和一个子串
# 返回子串匹配上的第一个位置,若没有匹配上返回-1
test = ''
if type(mom_string) != type(test) or type(son_string) != type(test):
return -1
if len(son_string) == 0:
return 0
if len(mom_string) == 0:
return -1
# 求next数组
next = [-1] * len(son_string)
if len(son_string) > 1: # 这里加if是怕列表越界
next[1] = -1
i, j = 1, 0
while i < len(son_string) - 1: # 这里一定要-1,不然会像例子中出现next[8]会越界的
if j == -1 or son_string[i] == son_string[j]:
i += 1
j += 1
next[i] = j
else:
j = next[j]
# kmp框架
m = s = 0 # 母指针和子指针初始化为0
while (s < len(son_string) and m < len(mom_string)):
# 匹配成功,或者遍历完母串匹配失败退出
if s == -1 or mom_string[m] == son_string[s]:
m += 1
s += 1
else:
s = next[s]
if s == len(son_string): # 匹配成功
return m - s
# 匹配失败
return -1
# 测试
mom_string = 'abababaababcad'
son_string = 'aababcad'
print(kmp(mom_string,son_string))
我感觉应该可以把next数组做到kmp内层,就是不知道效率如何,欢迎大佬指点。















 2764
2764











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









