







转换算子
主要做的是就是将一个已有的RDD生成另外一个RDD。Transformation具有lazy特性(延迟加载)。Transformation算子的代码不会真正被执行。只有当我们的程序里面遇到一个action算子的时候,代码才会真正的被执行。这种设计让Spark更加有效率地运行。
KV算子为Rdd内部为键值对类型
官方文档
RDD Programming Guide - Spark 3.5.1 Documentation
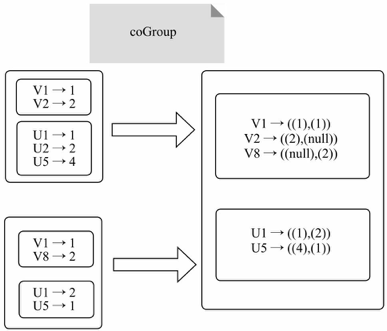
cogroup
cogroup:一组强大的函数,可以对多达3个RDD根据key进行分组,将每个Key相同的元素分别聚集为一个集合
val a = sc.parallelize(List(1, 2, 1,4), 1)
val b = a.map((_, "b"))
val c = a.map((_, "c"))
b.cogroup(c).collectArray[(Int, (Iterable[String], Iterable[String]))] = Array((4,(CompactBuffer(b),CompactBuffer(c))), (1,(CompactBuffer(b, b),CompactBuffer(c, c))), (2,(CompactBuffer(b),CompactBuffer(c))))

源码解析
/**
* For each key k in `this` or `other1` or `other2` or `other3`,
* return a resulting RDD that contains a tuple with the list of values
* for that key in `this`, `other1`, `other2` and `other3`.
*/
def cogroup[W1, W2, W3](other1: RDD[(K, W1)],
other2: RDD[(K, W2)],
other3: RDD[(K, W3)],
partitioner: Partitioner)
: RDD[(K, (Iterable[V], Iterable[W1], Iterable[W2], Iterable[W3]))] = self.withScope {
if (partitioner.isInstanceOf[HashPartitioner] && keyClass.isArray) {
throw new SparkException("HashPartitioner cannot partition array keys.")
}
val cg = new CoGroupedRDD[K](Seq(self, other1, other2, other3), partitioner)
cg.mapValues { case Array(vs, w1s, w2s, w3s) =>
(vs.asInstanceOf[Iterable[V]],
w1s.asInstanceOf[Iterable[W1]],
w2s.asInstanceOf[Iterable[W2]],
w3s.asInstanceOf[Iterable[W3]])
}
}
grouBy
groupBy算子接收一个函数,这个函数返回的值作为key,然后通过这个key来对里面的元素进行分组。
val a = sc.parallelize(1 to 9, 3)
a.groupBy(x => { if (x % 2 == 0) "even" else "odd" }).collect//返回的even或者odd字符串作为key来group RDD里面的值,
res42: Array[(String, Seq[Int])] = Array((even,ArrayBuffer(2, 4, 6, 8)), (odd,ArrayBuffer(1, 3, 5, 7, 9)))

可对比sortByKey与sortBy学习RDD转换算子(二)-KV算子(键值类)及源码解析-CSDN博客
源码解析
/**
* Return an RDD of grouped elements. Each group consists of a key and a sequence of elements
* mapping to that key. The ordering of elements within each group is not guaranteed, and
* may even differ each time the resulting RDD is evaluated.
*
* @note This operation may be very expensive. If you are grouping in order to perform an
* aggregation (such as a sum or average) over each key, using `PairRDDFunctions.aggregateByKey`
* or `PairRDDFunctions.reduceByKey` will provide much better performance.
*/
def groupBy[K](
f: T => K,
numPartitions: Int)(implicit kt: ClassTag[K]): RDD[(K, Iterable[T])] = withScope {
groupBy(f, new HashPartitioner(numPartitions))
}
/**
* Return an RDD of grouped items. Each group consists of a key and a sequence of elements
* mapping to that key. The ordering of elements within each group is not guaranteed, and
* may even differ each time the resulting RDD is evaluated.
*
* @note This operation may be very expensive. If you are grouping in order to perform an
* aggregation (such as a sum or average) over each key, using `PairRDDFunctions.aggregateByKey`
* or `PairRDDFunctions.reduceByKey` will provide much better performance.
*/
def groupBy[K](f: T => K, p: Partitioner)(implicit kt: ClassTag[K], ord: Ordering[K] = null)
: RDD[(K, Iterable[T])] = withScope {
val cleanF = sc.clean(f)
this.map(t => (cleanF(t), t)).groupByKey(p)
}
代码调试
创建GroupRDD对象,代码如下:
package com.soft863
import org.apache.spark.{SparkConf, SparkContext}
object GroupRDD {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[1]").setAppName("WC")
val sc = new SparkContext(conf)
val a = sc.parallelize(List(1, 2, 1,4), 1)
val b = a.map((_, "b"))
val c = a.map((_, "c"))
b.cogroup(c).collect.foreach(println)
val rdd = sc.parallelize(1 to 9, 3)
rdd.groupBy(x => { if (x % 2 == 0) "even" else "odd" }).collect.foreach(println)
}
}
运行结果
(4,(CompactBuffer(b),CompactBuffer(c)))
(1,(CompactBuffer(b, b),CompactBuffer(c, c)))
(2,(CompactBuffer(b),CompactBuffer(c)))
(even,CompactBuffer(2, 4, 6, 8))
(odd,CompactBuffer(1, 3, 5, 7, 9))
















 936
936

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











