






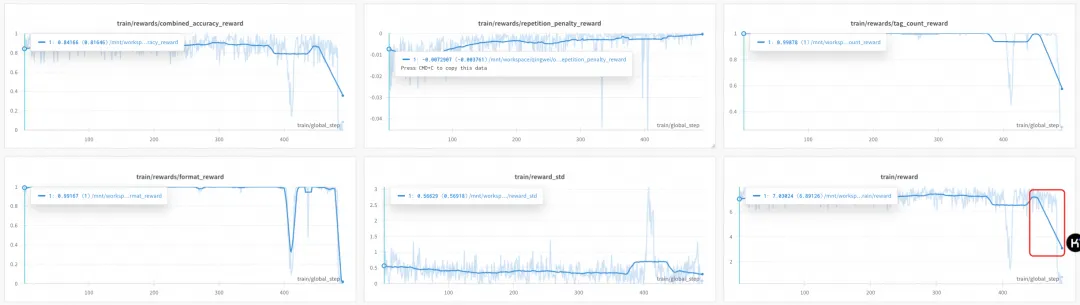
在大模型训练中使用GRPO,训到一半 reward 就很容易突然掉下来的原因?
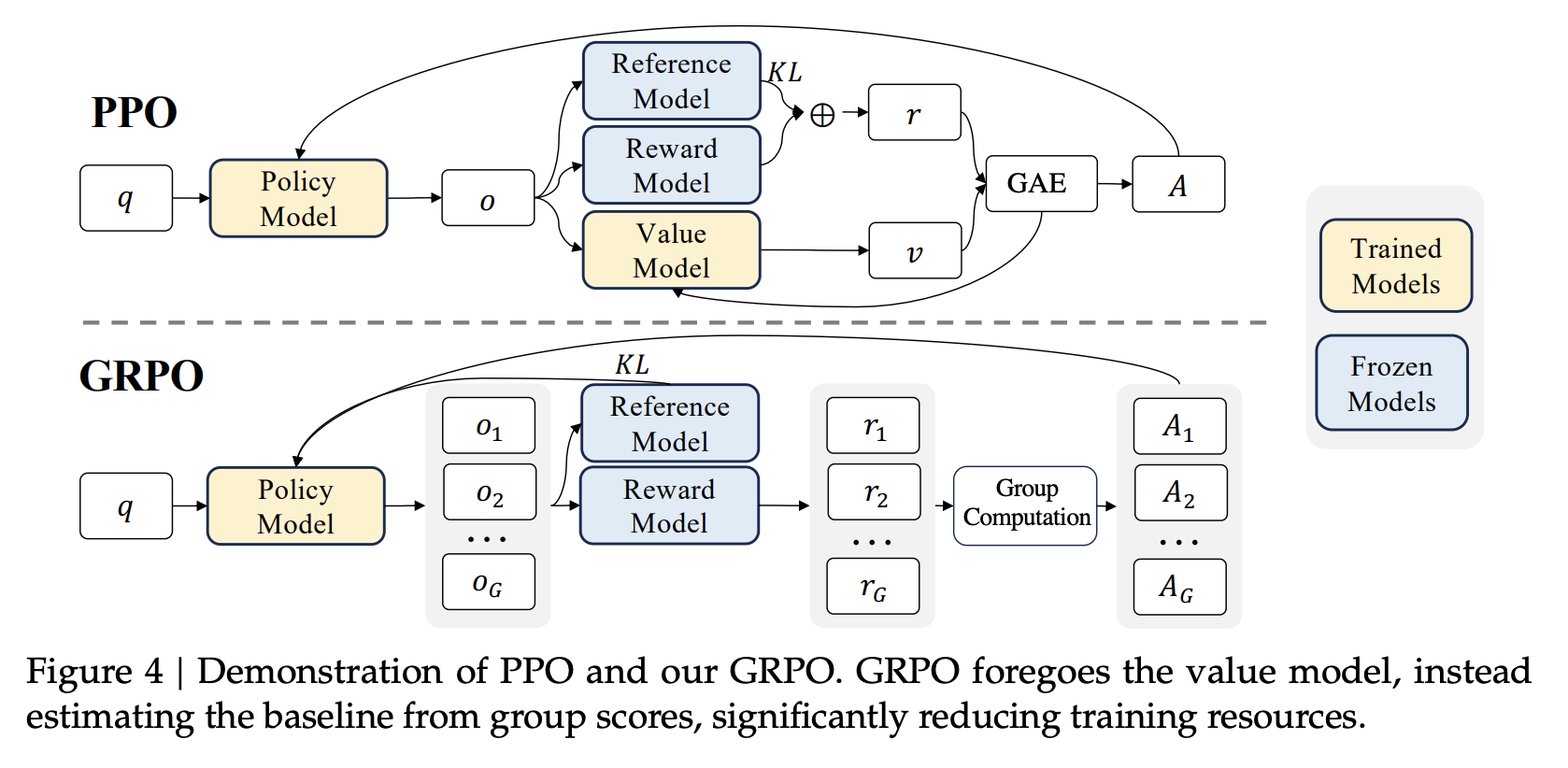
GRPO 出现这个问题,需要详细了解强化学习(RL)的基本迭代架构,即 Actor-Critic 架构。
很多中文书籍将 AC 架构翻译为“演员-评论家”架构,真是感觉好 low,信达雅的美感完全被破坏掉了。
我更加喜欢另一外中文翻译,即"知行互动"架构。译文的启发来自于王阳明先生的“知行合一”,更有中国文化的历史底蕴。
“知”为 Critic,它是“行动”的评价与指导,“行”是 Actor,它根据“认知”结果进行改进。"互动"两个字则反映了算法本身不断迭代的特性。知行互动(AC)架构为什么要有 Critic 呢?这就涉及强化学习的算法稳定性问题。与监督学习(SL)相比,RL 实际上是很难稳定的一类训练机制。
大致的原因如下:
RL 本身是处理动态系统的最优控制问题,而 SL 是处理一个静态优化问题。动,就比静更难处理。
加上 RL 的数据非稳态,Env-agent 交互机制的数据采集量少,这使得梯度计算的方差更大,方差一大就容易偏离预期目标,算法就容易跑飞了。
主流的强化学习算法是怎么解决这一问题的呢?加上 Critic,使用 State-value function 或者 Action-value function 稳定策略梯度的计算过程。更高级一些的算法是采用 Advantage Function,也就是加上了 Baseline,增加梯度计算的稳定性。这是 AC 算法总是优于 REINFORCE 算法的原因之一。然而 GRPO 并没有 Critic 部分,原因比较简单,因为 GRPO 是用于训练大模型(1000 亿级别的参数规模),若是使用“知行互动”架构的话,等于需要存储两个大模型。
一个是 Critic Network,另外一个是 Actor Network,这对存储要求是极高的。
怎么节约存储呢?把 Critic Network 去掉,替换为在线估计 Advantage function 的算法,采用了“时间(算力)”换“空间(存储)”的做法。这就是 GRPO 的设计思想。与之对比,OpenAI 提出的 PPO 算法(也是 GRPO 的基础算法),它的值函数通常是一个与策略模型大小相当的模型,这带来了显著的内存和计算负担。
考虑到 OpenAI 并不缺算力资源,不缺存储资源,即使 PPO 算法设计的如此糟糕,照样用的风生水起。除了 DeepSeek 之外,国内不少大模型团队照猫画虎,有样学样,实际上是选择了一条次优的技术路径,因为恰恰忘记了我们与 OpenAI 的最大区别是什么。回到最初的话题,从原理上看 GRPO 并非完美,与 PPO 相比实际上处于是半斤八两的水平,算法设计存在“稳定性”缺陷,但是为什么 DeepSeek 还能用的比较好呢?
因为 DeepSeek 的数据足够多,多到可以“完美”地避开 GRPO 的稳定性缺陷。每次的 Policy Gradient 计算,只要 Batch 数据足够多,就能有效降低 Policy Gradient 的方差,就能获得比较稳定的迭代了。很明显,对于高校科研团队,对于中小规模的 RL 训练(~百万或千万级别参数规模),GRPO 并非一个好的选择,尤其是当每次使用的数据批量比较小的时候,它的稳定性缺陷将是致命的。这类规模的策略训练,建议优先选择带有 Critic 的强化学习算法。
转载自 https://mp.weixin.qq.com/s/zm6wv2FAkVDVlnP2Xp191w
今天分享下这几天很火的这个工作,字节的DAPO工作。论文地址:https://arxiv.org/html/2503.14476v1
其实这个论文很精彩,可以先从故事说起。
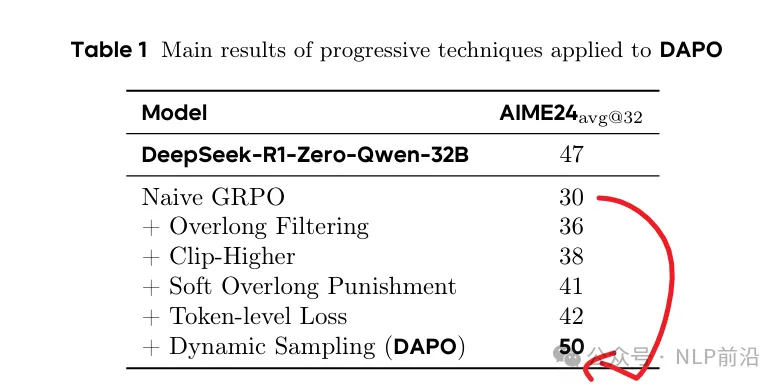
打开deepseek-r1的论文,论文里边提到使用GRPO用R1-zero的方式,训练 qwen-32B,在AIME 2024上可以达到47分。
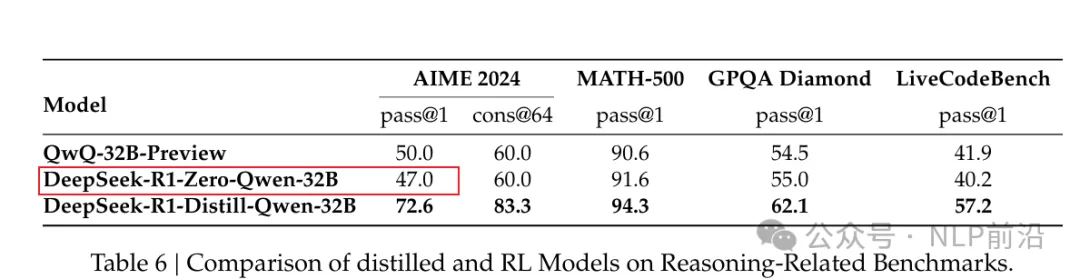
然后字节的大佬们,尝试复现了一下,发现用GRPO跑一下32B的Qwen,只能训出来30分。
这差出来的小20分,应该都是deepseek看家的不传之秘了(起码目前的技术报告中都没有透露)。
那这咋整尼,就分析,发现了用GRPO训练,存在一些问题,比如说熵崩溃、奖励噪声、训练不稳定。然后针对这些问题观察,见招拆招,就有了DAPO的工作。
熵崩溃,是发现,在训练的早期,策略的熵快速下降,因为组里边的响应基本都一致了。
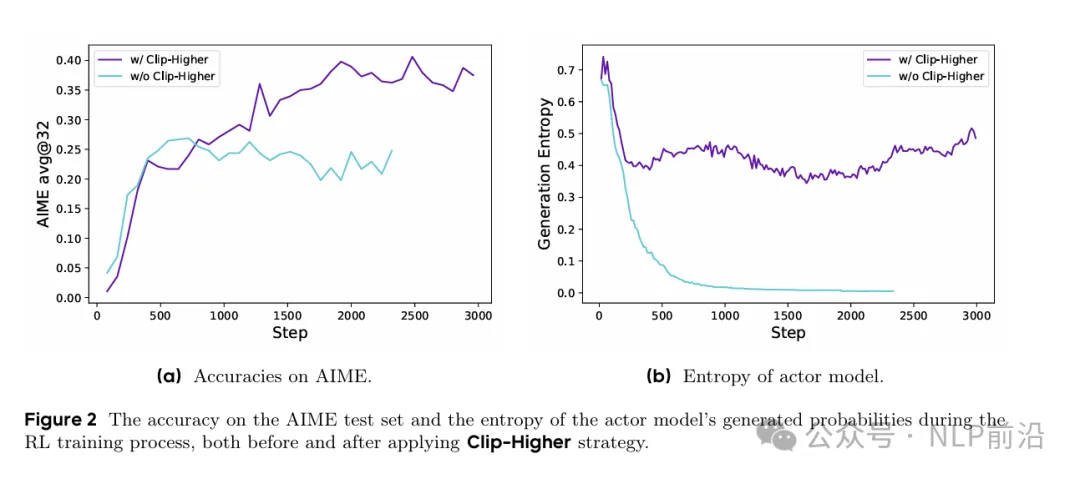
在ppo、grpo中,通过裁剪对策略更新比例进行了限制,确保每次更新不会很大,保持u需哪里稳定性。但是这个clip机制的上下限是一致的,这就一定程度限制了低概率token的探索能力。
所以DAPO的第一个观察改进就是,将上下限解耦, 给低概率的token增加留出更多的空间,从而避免熵崩溃。

接下来,第二个改进是为了提高训练效率的,在训练过程中,当某些输入的准确率是1/0, 这些样本对梯度没贡献了。看下图,step涨,正确的样本比例也在持续涨。
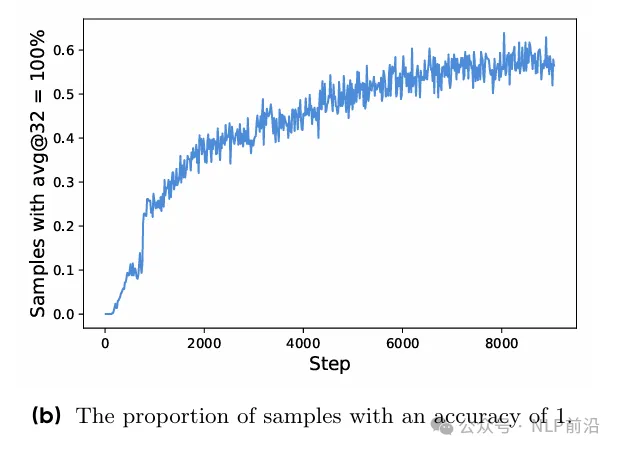
所以DAPO的采样过滤掉这些样本,确保每个批次样本都能有效贡献梯度。(持续采样,直到满足采样条件)

GRPO的损失,是先样本内的损失平均,再样本间的损失平均。这样每个样本赋予的权重是一样的,但是对于长序列这很显然就不公平了。包含较多token的样本,会出现一些低质量模式,如下图,熵和长度都呈现不正常的增长。
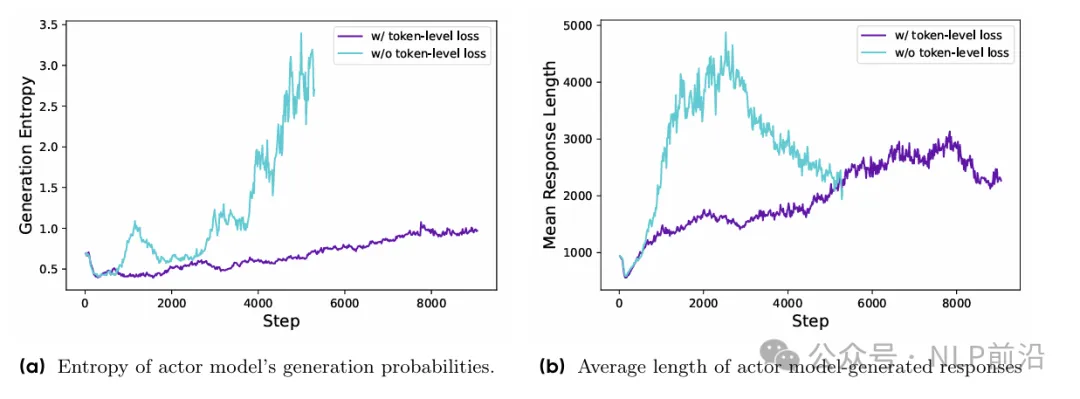
所以引入了token级别的策略梯度损失,让较长序列对整体梯度更新有更大的影响。(每个token的损失被单独计算,在整体损失中按其在序列中的位置进行加权。)
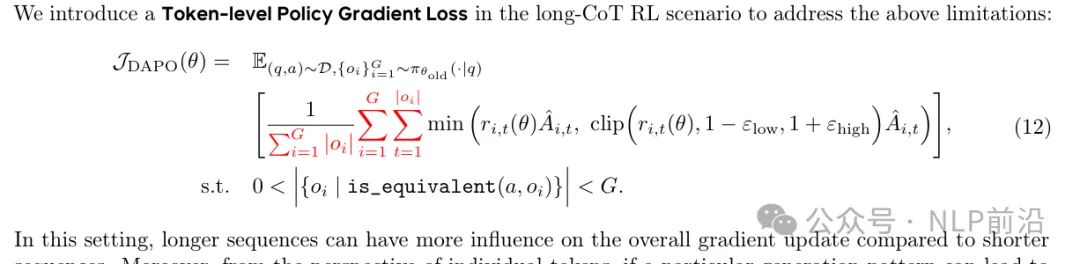
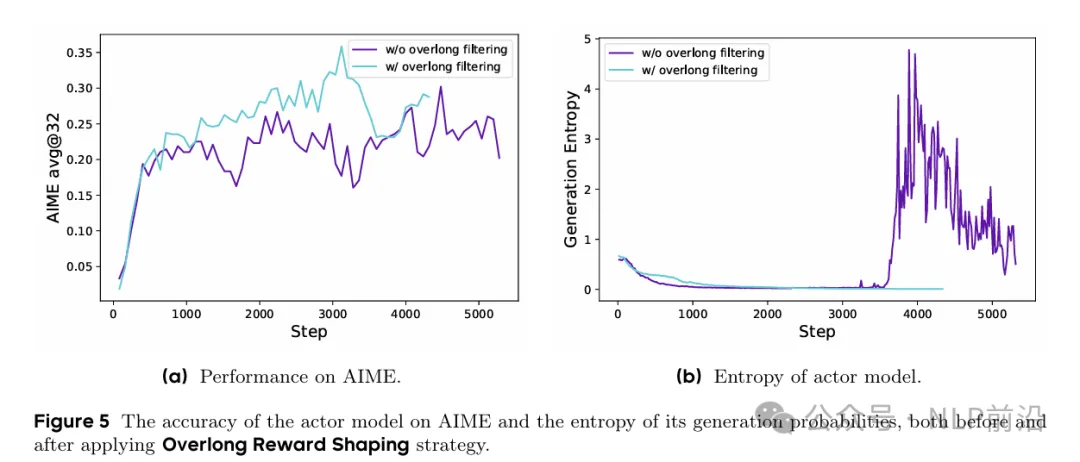
最后一个改进,在强化学习训练中,过长的样本可能会被截断,这个截断的样本会引入奖励噪声,干扰了训练。
所以作者们提出了2个策略来应对,一个是直接屏蔽截断样本的损失,其次是对超过预设长度的样本施加惩罚。
最后几层优化buff叠下来,起飞。
以上转载自 https://mp.weixin.qq.com/s/s721lnVxTPBuNdB1GP6H0A
以下转载自 https://zhuanlan.zhihu.com/p/31770741283,其中ga是gradient accumulation的意思,来自https://unsloth.ai/blog/gradient的讨论



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









