






模型量化的思路可以分为PTQ(Post-Training Quantization,训练后量化)和QAT(Quantization Aware Training,在量化过程中进行梯度反传更新权重,例如QLoRA),GPTQ是一种PTQ的思路。
QAT(Quantization Aware Training)
BN需要先融合掉:

伪量化节点是根据融合图来决定的
量化过程中不可导的部分是Round函数,Hinton论文中把他的导数置为1,这就解决了量化框架中梯度反向传播的问题,图片截取自https://www.bilibili.com/video/BV13s4y1D73L/:


AdaRound和AdaQuant这些论文都是一层层训练的,QAT需要把某些层切成子图,对子图量化即可。
QLoRA
几个关键点:
- 4bit NormalFloat 量化
- 双重量化
- Page Optimizer:Page Optimizer机制使得在GPU显存吃紧的时候可以把optimizer转移到内存上,在需要更新optimizer状态时再加载回来,据说可以有效减少GPU显存的峰值占用,文章称想要达到在24gb上训练33B 参数模型这个机制是必须的
QLoRA实现中用了bitsandbytes这个库
GPT
例如TensorRT的后量化,paddlepaddle的后量化,推理框架最清楚网络做哪些图融合,但是GPT不会训练,不会梯度反传。PPQ是商汤出的量化框架

OBD(Optimal Brain Damage)
截图自 https://readpaper.feishu.cn/docx/HaM7d7uGhoQ2VPxxZBacpduDny7

OBS(Optimal Brain Surgeon)
简单来说就是把权重直接展开,计算对应的海森矩阵,然后按照顺序进行量化。时间复杂度
O
(
(
d
row
⋅
d
col
)
3
)
O\left( \left( d_{\text{row}} \cdot d_{\text{col}} \right)^3 \right)
O((drow⋅dcol)3)
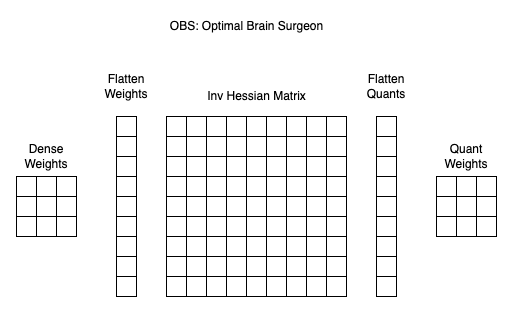

以下截图来自 https://readpaper.feishu.cn/docx/HaM7d7uGhoQ2VPxxZBacpduDny7

OBQ(Optimal Brain Quantization)
权重分行计算,但是贪心算法,每次找量化误差最小的进行量化。时间复杂度:
O
(
d
row
⋅
d
col
3
)
O\left( d_{\text{row}} \cdot d_{\text{col}}^3 \right)
O(drow⋅dcol3)

GPTQ(Gradient Post Training Quantization)
- GPTQ并不是完全凭空头脑风暴出来的想法,而是经过OBD(Optimal Brain Damage)->OBS(Optimal Brain Surgeon,Second Order Derivatives for Network Pruning)-> OBQ(Optimal Brain Quantization)->GPTQ逐渐演化过来的。这一类思路基本的出发点在于先考虑一个单层的网络W,如何找到一个量化后的网络Wq,使得W和Wq之间的差别最小?OBD方法是Lecun在1989年就在搞的方法,主要思路用W和Wq之间的误差进行泰勒展开,展开后舍弃一些项,得到利用海森矩阵进行迭代更新;OBS方法发现OBD方法在进行权重剪切的过程中并不完全合理,所以新增了权重删除补偿的策略;OBS在执行中是直接把权重展开计算对应的海森矩阵,然后按照顺序进行量化;OBQ对量化的顺序进行了调整,将权重分行进行计算,利用贪心算法每次找到量化误伤最小的行进行量化,量化复杂度显著降低;GPTQ在OBQ基础上使用相同顺序,各行并行计算,分批 BatchUpdate,分组量化,时间复杂度 O ( max { d row ⋅ d col 2 , d col 3 } ) O\left( \max \left\{ d_{\text{row}} \cdot d_{\text{col}}^2, d_{\text{col}}^3 \right\} \right) O(max{drow⋅dcol2,dcol3})
- GPTQ在实现中用Cholesky分解来稳定了数值计算
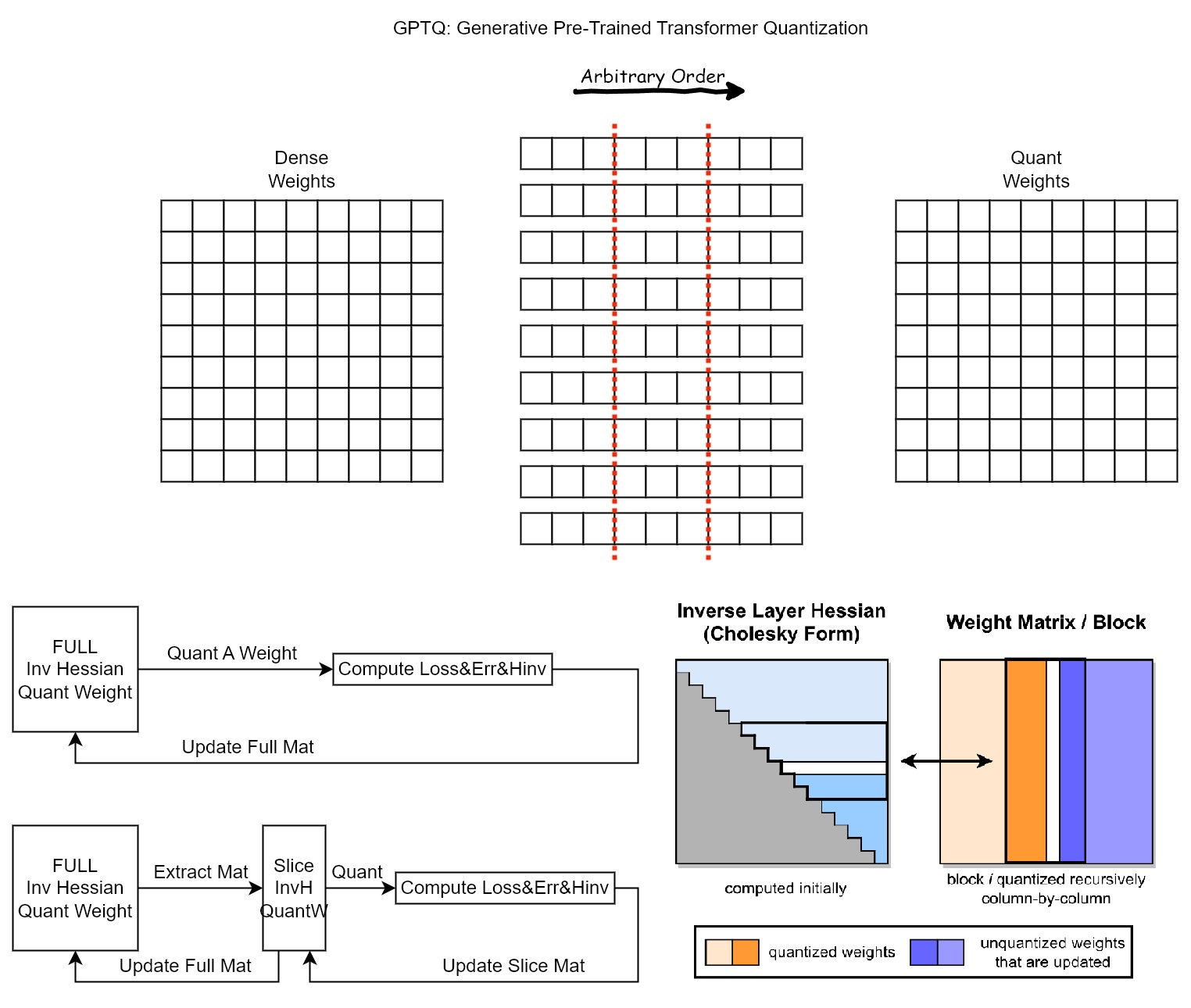
GPTQ的reorder原理(核心思想:分组优化与权重删除补偿、并行)
在量化过程中,GPTQ 将权重矩阵按列划分为多个子块(Block),例如每组 128 列。其核心目标是通过调整量化顺序和参数更新方式,减少量化误差的累积。具体来说:
- 分组优化:将权重矩阵按列分组,逐个子块量化。例如,先量化当前子块中的某一列,再调整该子块内其他未量化的列以补偿误差。
- 权重删除补偿:量化某一列后,通过数学方法(如 Cholesky 分解)计算量化误差对后续列的影响,并动态更新剩余权重,以最小化整体输出误差。
- 并行:GPTQ在OBQ基础上使用相同顺序,各行并行计算,分批 BatchUpdate,分组量化
参考文档
- https://readpaper.feishu.cn/docx/HaM7d7uGhoQ2VPxxZBacpduDny7
- https://readpaper.feishu.cn/docx/OPP2dTuXAoaO0oxWhQAcC05Wnpc

















 1770
1770

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









