






基本是从图片抹水印和视频抹水印两个方向
- Video Inpainting:https://paperswithcode.com/task/video-inpainting
- Image Inpainting:https://paperswithcode.com/task/image-inpainting
请根据目录查看
图片
Partial Conv
部分卷积层
源自于Image Inpainting for Irregular Holes Using Partial Convolutions这篇paper,部分卷积模型使用的是UNET结构,但将其中的卷积层替换为了部分卷积。其基本思想是对于图片被mask掉的区域进行由外而内的,递进式的修补,浅层网络学习孔洞外围,深层层网络学习孔洞内部,用作者的话来说就是 Our main extension is the automatic mask update step, which removes any masking where the partial convolution was able to operate on an unmasked value. Given sufficient layers of successive updates, even the largest masked holes will eventually shrink away, leaving only valid responses in the feature map.

Partial Conv Loss
在训练时,共使用了6个损失函数:
- Hole loss:对孔洞区域生成的像素和实际像素间做L1 Loss
- Valid loss:对非孔洞区域生成的像素和实际像素间做L1 Loss
以上两种都是像素级别的loss,但是当孔洞较大时,中间的像素loss就不够用了,所以补了Perceptual loss和Style loss
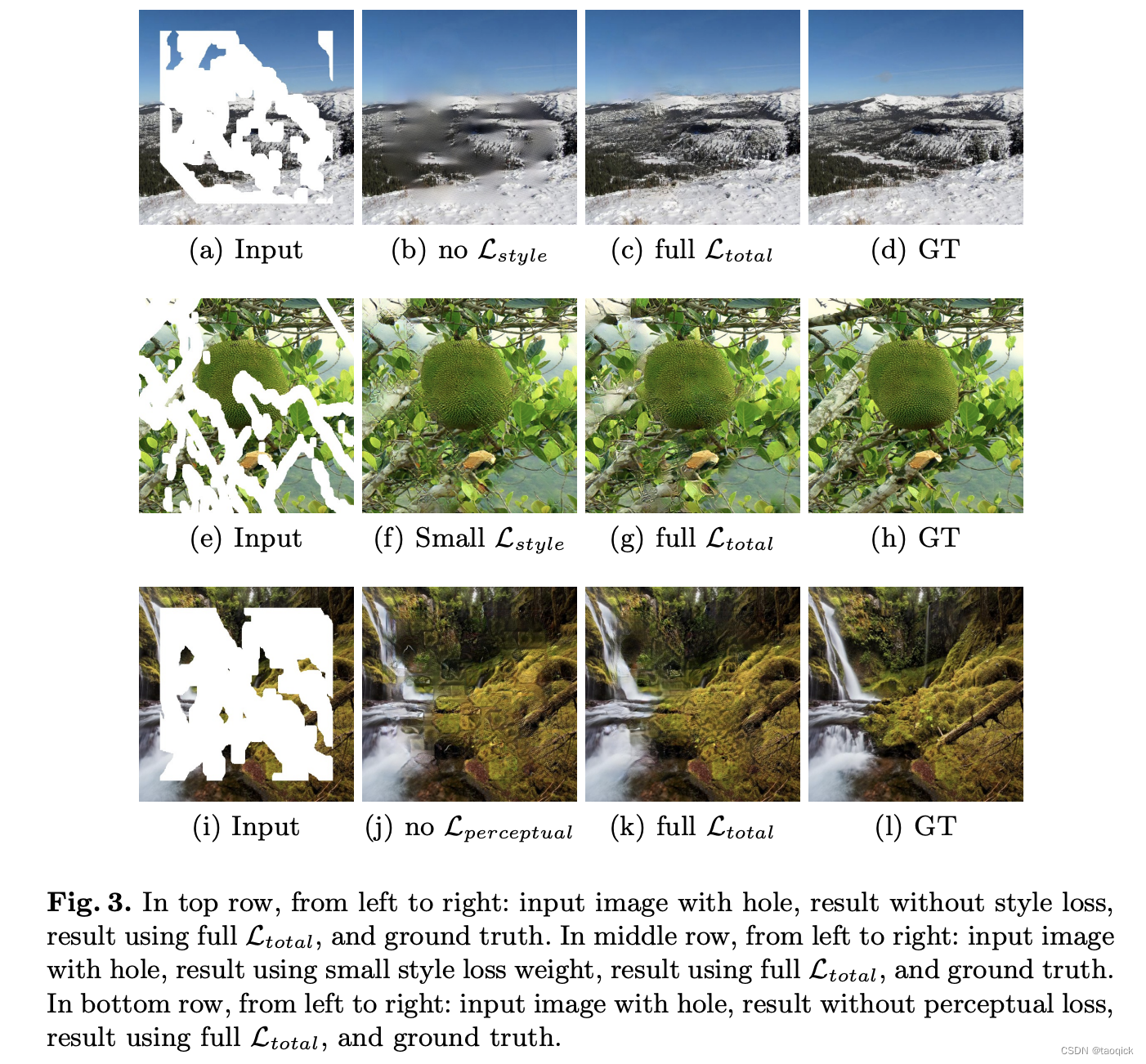
- Perceptual loss:使用一个预训练好的图片特征抽取网络,对原始图片和生成图片分别进行特征抽取,然后对抽取得到的特征图间做L1 loss
- Style loss:对于抽取出的特征图,求其格拉姆矩阵,然后对原始图片和生成图片的Gram matrix求L1 loss。格拉姆矩阵即两两向量的内积组成的矩阵,用以衡量一个特征图各channel之间的相关关系,其做法是将特征图各channel拉平为1维向量,然后互相做内积。向量的内积的几何意义是向量的夹角,Gram matrix就代表了图片特征图各channel的互相关程度,这一loss常用在风格迁移上,使图片的风格趋同,也即使图片的特征分布趋同。Style loss根据
I
c
o
m
p
I_{comp}
Icomp和
I
o
u
t
I_{out}
Iout填了两种,
I
c
o
m
p
I_{comp}
Icomp是
I
o
u
t
I_{out}
Iout把 the non-hole pixels directly
set to ground truth后的结果,用来强调非孔洞的逼真性。
为了使生成的图片孔洞交界部分更平滑,论文中还引入了TV loss来降噪:
- Total variation loss:将图片分别在x轴、y轴平移1像素,计算平移后的图片和原图片的L1 loss
SLBR
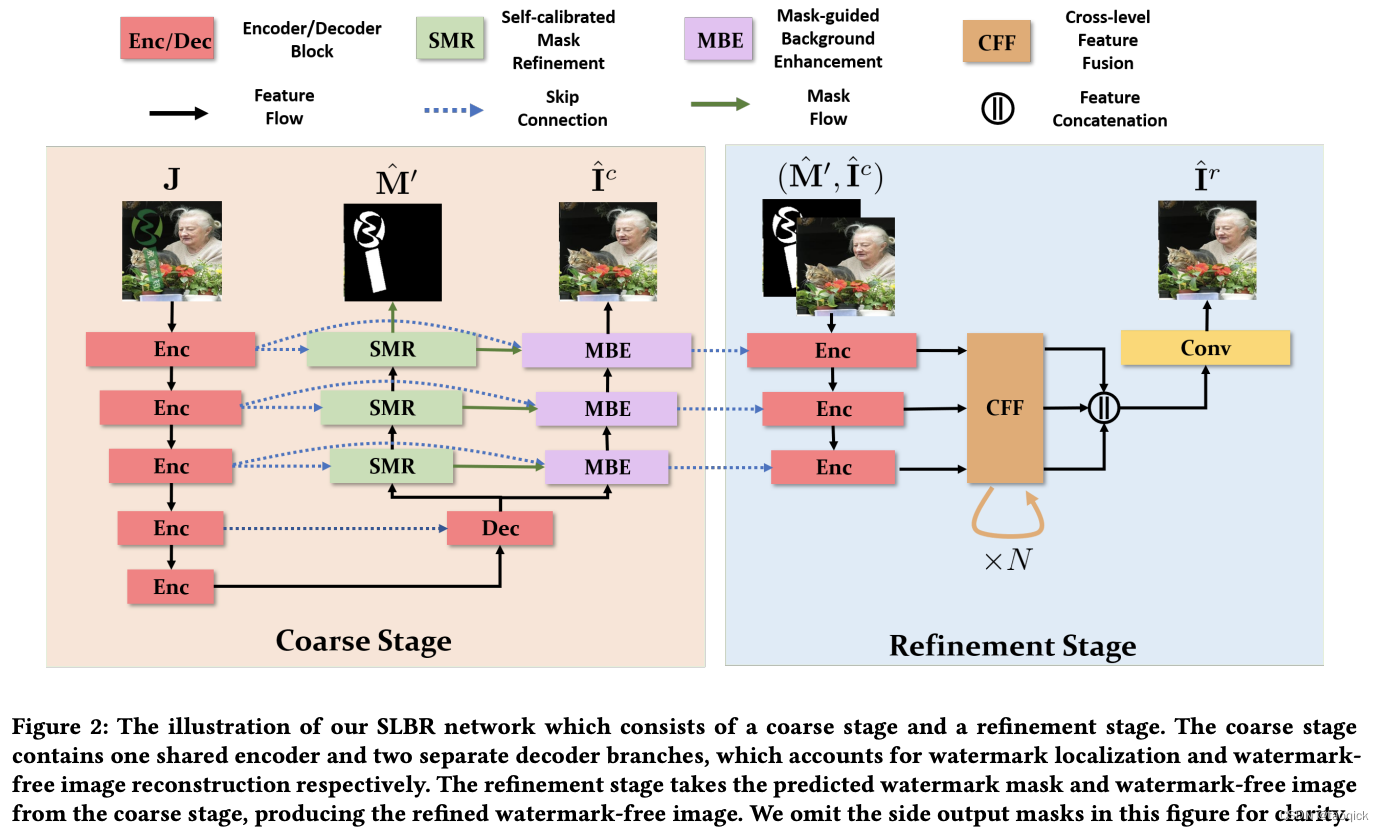
来自于Visible Watermark Removal via Self-calibrated Localization and Background Refinement这篇,Pconv是需要传入孔洞位置的,这篇相当于训练的时候检测和修复一起做了,end2end。但这种方法抹视频的时候会出现某些帧识别不好出现幽灵水印的情况,实际视频抹除也不适合这种做法,但本paper思路还是不错的。
SLBR的基本结构也是UNET,两个任务共用encoder和第一层decoder。模型分为两个阶段,Coarse Stage阶段生成mask和粗修复的图像,Refinement Stage阶段以生成的mask和粗修复的图像为输入,使用一个层数较小的UNET对图片进一步优化:
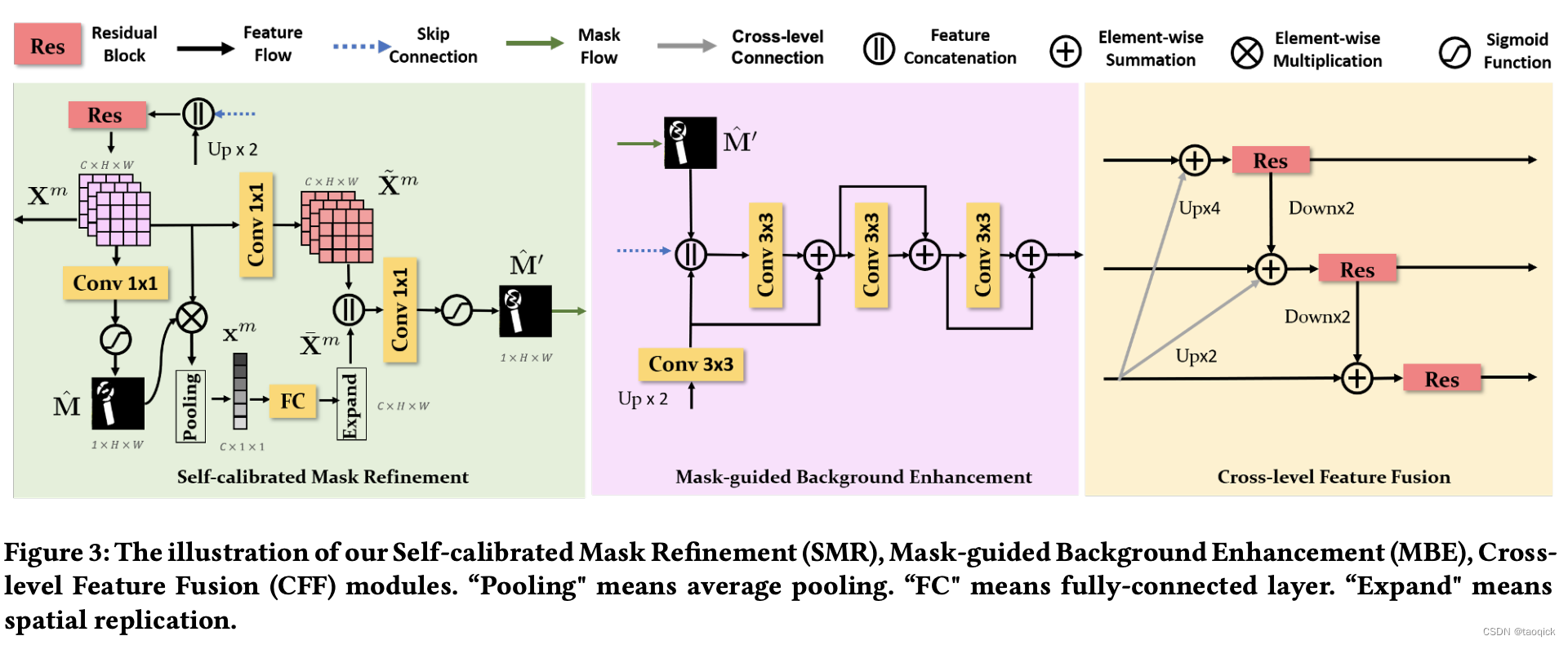
其中MBE模块就是将图片修复decoder层的输入特征拼接上mask decoder层的输出,加入mask信息来强化修复效果;CFF层为拼接了不同层的特征;SMR目标是消除mask像素识别的误召和漏召。首先根据当前层的特征图
X
m
X^m
Xm生成一个预测mask,将这个mask乘上
X
m
X^m
Xm,虽然此时的预测mask存在误召和漏召,但其中仍然是mask像素占主要部分,对其pooling后得到的特征向量
x
m
x^m
xm认为是代表了mask区域的主要特征。将
x
m
x^m
xm扩展为和特征图
X
m
X^m
Xm同样大小后,与
X
m
X^m
Xm拼接,生成最终的mask预测。然而实际中,像素级别的误召和漏召很难完全避免,这也是制约这种算法效果的一种主要原因。
LAMA
来自于Resolution-robust Large Mask Inpainting with Fourier Convolutions,想法是傅立叶卷积来代替通常的卷积层,增强模型的感受野,让模型在浅层就能学习到全局特征。傅里叶卷积听起来很厉害,但实际上用pytorch的卷积操作都可以实现,来自于Fast Fourier Convolution这篇。因为每个点都表示图中包含的一种波,也就是每个点都代表了一定的全局特征,所以进行傅立叶变换后再进行卷积,不管卷积核的大小如何,都是在对全局特征做计算。
LAMA使用了对抗损失,生成器负责生成图片,判别器负责判断这个图片是真实图片还是由生成器生成的图片,生成器和判别器间互相对抗,互相优化,从而最后使生成器能够生成以假乱真的图片,这一框架被广泛应用于各类图片生成任务中。
在图片修复任务中,修复模型是生成器,判别器的任务是判断原始图片和修复图片孰真孰假。本文中使用的是PatchGAN,即将图片切分为若干个patch,然后让判别器对每个patch判断真假,与水印区域有交集的patch标记为假,否则为真。具体实现上则是使用了若干层卷积网络叠加,输出NxN的预测矩阵,每个点即代表了对该点感受野的预测。相比于直接对整张图判断真假,PatchGAN能够对图像的局部做出判断,从而促使生成器生成更好的细节特征。
除了对抗损失,LAMA在训练时使用了High receptive field perceptual loss,最终的loss为:

视频
上面三个图像工作是三种思路,但是下面三个视频思路是一脉相承的
STTN
来自于Learning Joint Spatial-Temporal Transformations for Video Inpainting,关键点在于视频帧中间如何交互,提出了Spatial-Temporal Transformer模块,通过这一模块在时空上进行帧间信息的交换。其做法是将输入的特征图在宽高维度上切分为若干个patch,然后将patch拉成1维token,再去做attention。文中使用了不同patch size的attention头,大patch size的头关注全局结构,小patch size的头关注局部细节,最后将这些不同patch size头的输出加权相加,恢复为原始特征图的shape:
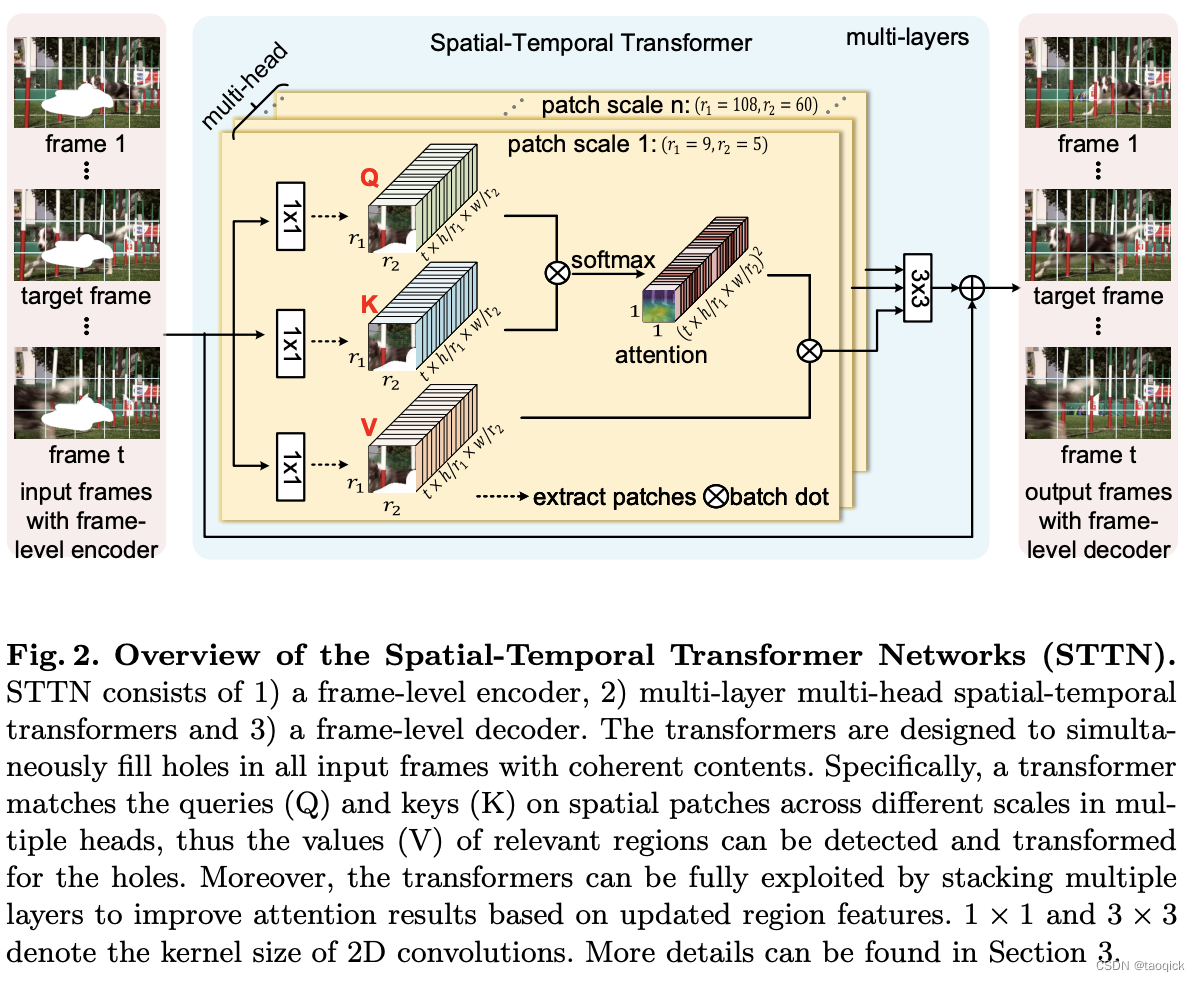
STTN模型也使用了对抗损失,其使用了名为T-PatchGAN的判别器,T指的是Temporal,相比于PatchGAN使用2维卷积,T-PatchGAN的判别器使用了3维卷积,来捕获帧间的时序信息,从而促使生成器生成在时序上连续性更强的帧。
FuseFormer
来自于FuseFormer: Fusing Fine-Grained Information in Transformers for Video Inpainting,同样是使用了Transformer模块,但与STTN不同的是,它没有用不同尺度的patch,而是使用了Soft Split来将图片分割为有交叠的patch。用作者自己的话来说就是It aims at tackling the drawbacks of lacking fine-grained information in patch-based Transformer models. The soft split divides feature map into many patches with given overlapping interval while the soft composition stitches them back into a whole feature map where pixels in overlapping regions are summed up.
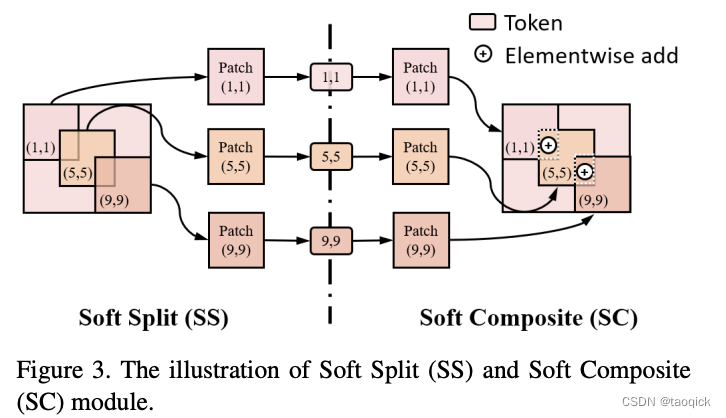
过完transformer后,再通过Soft Composite将这些patch拼合,交叠区域相加,通过交叠区域,来完成patch与patch间的特征交互。
E2FGVI = Optical + FuseFormer
来自于Towards An End-to-End Framework for Flow-Guided Video Inpainting,E2FGVI顾名思义在FuseFormer基础上又引入了光流。
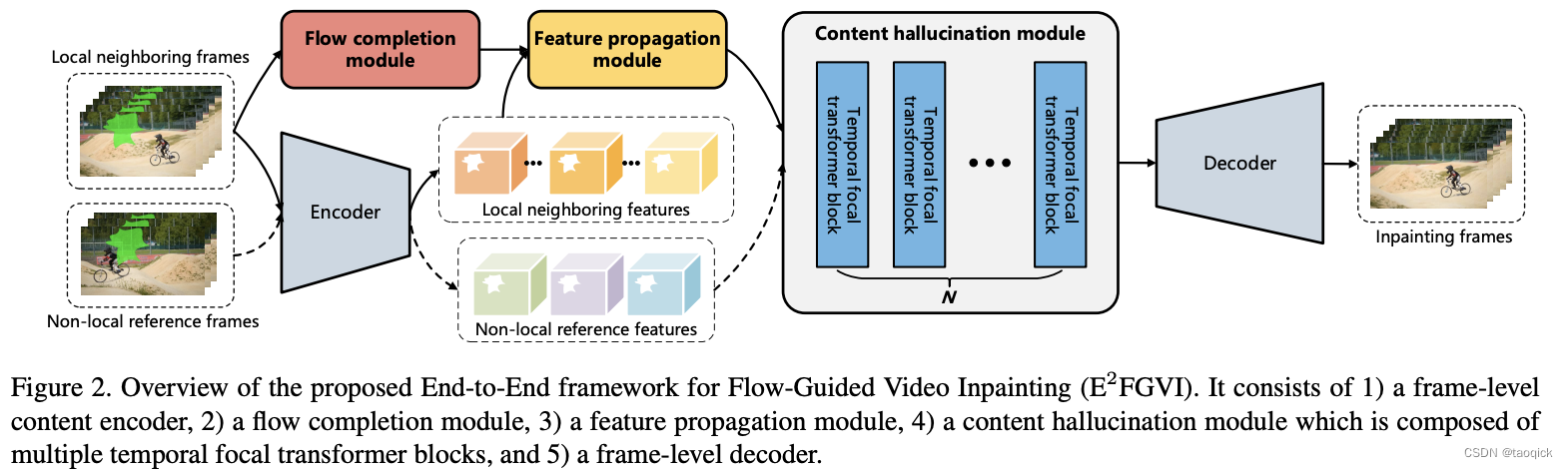
本文中光流预测使用了SpyNet,结合了传统方法中空间金字塔的思想,大大减少了传统FlowNet的参数量。
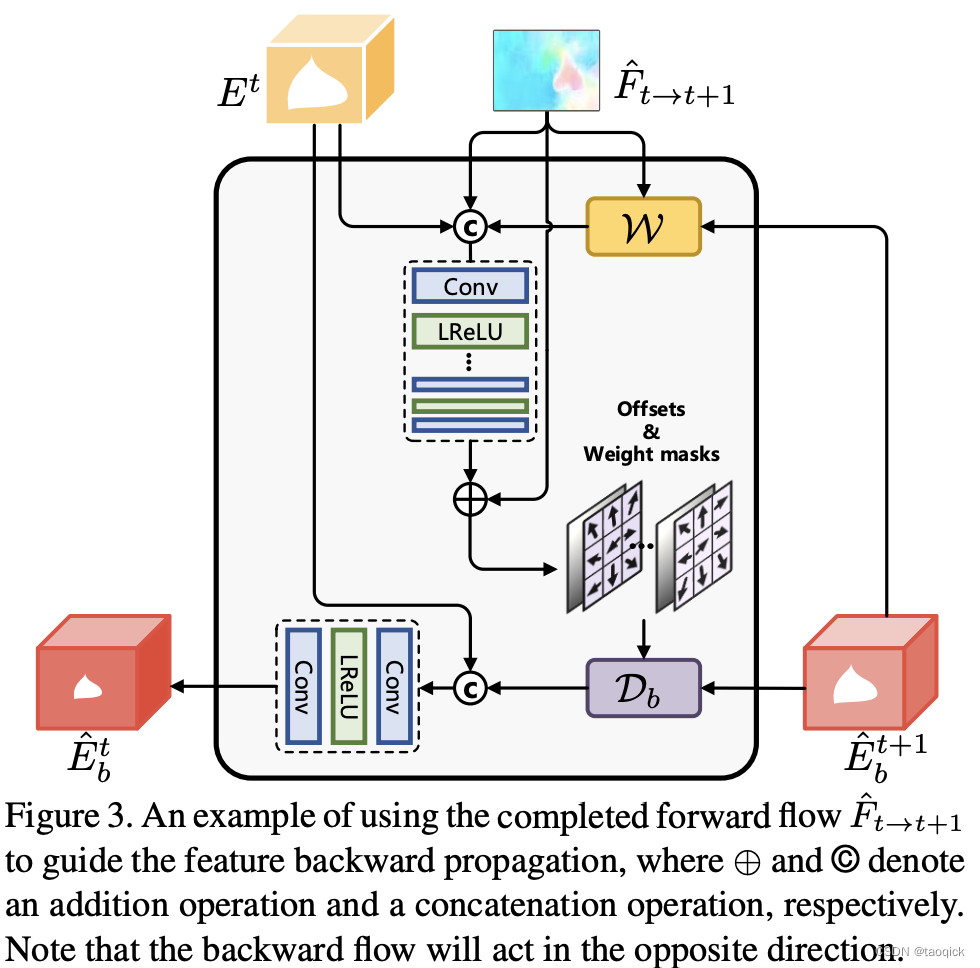
Optical flow其实代表了空间上的变化
图里 E b t ^ \hat{E_b^t} Ebt^表示 the backward propagation feature at the t-th time step, E t E^t Et表示 the local temporal neighboring features extracted from the context encoder, F ^ t − > t + 1 \hat{F}_{t->t+1} F^t−>t+1表示optical flow。值得注意的是,由于光流预测后本身有些噪声,所以作者并没有直接和 E t E^t Et融合,而是把光流信息经过一系列 deformable convolutional layer同时结合 E b t + 1 ^ \hat{E_b^{t+1}} Ebt+1^来得到图中的 D b \mathcal{D}_b Db,再和 E t E^t Et融合
FuseFormer其实代表了时间上的融合
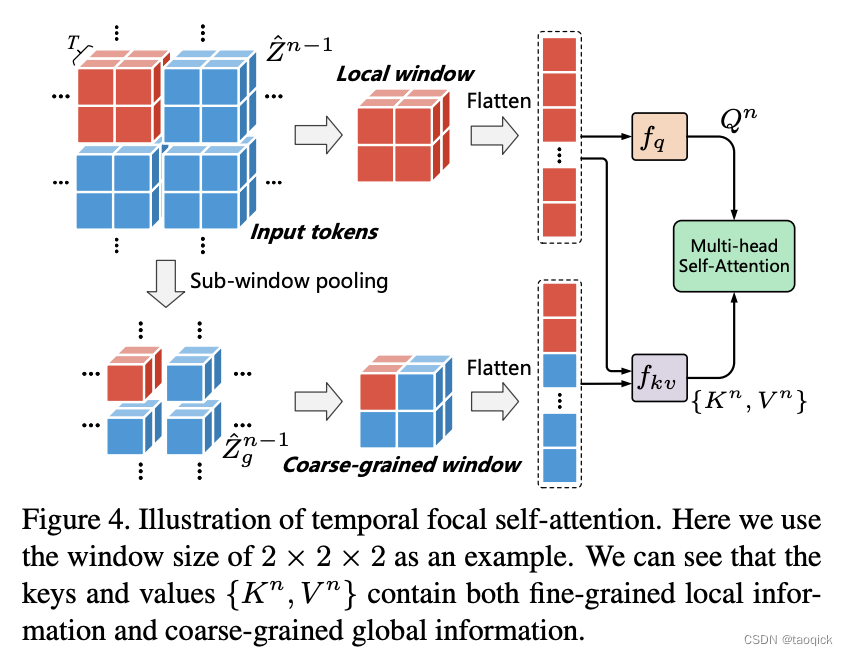
we stack multiple temporal focal transformer blocks to effectively combine the information from local and non-local temporal neighbors for performing content hallucination. 这里Transformer和STTN里还有些区别,如图,这种方式可以结合Coarse-grained和 fine-grained ,图里的
Z
^
n
−
1
\hat{Z}^{n-1}
Z^n−1表示经过SS后得到的embedding token
评估指标
PSNR
PSNR全称是Peak Signal-to-Noise Ratio,峰值信噪比,表示信号最大可能功率和影响它的表示精度的噪音功率的比值,对于原始图像和添加了噪音的图像,PSNR越大,代表和原图像越接近
SSIM
SSIM全程是Structural SIMilarity,结构相似性,衡量两张图片亮度、对比度和结构的相似度
参考文献
- Image Inpainting for Irregular Holes Using Partial Convolutions
- https://zhuanlan.zhihu.com/p/99605178
- 其他都在正文中注明














 2489
2489











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









